Repo Analyzer Multi-Agent System (RAMAS) is a fully automated, multi-agent, assembly-line–based system that ingests any GitHub repository, performs semantic understanding of code, generates metadata, suggests improvements, extracts tags, and produces high-value summaries. RAMAS is designed to serve as a core intelligence engine for developer tooling, AI agents, repository search platforms, or documentation automation pipelines. The system uses Groq-powered LLM nodes and LangGraph for agent orchestration.
RAMAS solves a high-impact problem:
“How can we deeply understand an entire repository—its purpose, code quality, tags, metadata, and structure—automatically, consistently, and at scale?”
Modern AI agents require structured metadata. Developers want automatic documentation. Companies want repository intelligence and categorization. RAMAS delivers this through a multi-stage, agent-based pipeline that moves through the repository like an assembly line, producing consistent, actionable outputs.
RAMAS is built to:
RAMAS uses the following components:
StateGraph Pipeline (LangGraph) — Manages deterministic multi-step execution
Four Specialized Agents — Repo Analyzer Agent , Metadata Agent , Tag Generator Agent , Reviewer Agent
Groq LLM Nodes — Ultrafast inference for structured generation
Embeddings-based Retrieval — Context-aware responses for agents
Prompt Templates Library* — Ensures deterministic, highly structured outputs

Creates:
Uses the following resource to generate keywords
Produces:
The system's workflow is governed by a framework that defines its computational steps, or nodes, as pure Python functions designed to manage explicit input and output states. This architecture is crucial for enforcing order within sequential processes, while simultaneously being robust enough to support parallel execution for independent tasks, such as those involved in generating multiple tag pipelines. A key feature of this design is its ability to provide fault-tolerant graph execution, ensuring the overall process remains reliable and stable even if individual nodes encounter errors.
The Groq LLM Nodes are deployed throughout the pipeline to handle crucial generative and analytical tasks. These powerful components are specifically used for metadata generation, creating descriptive and structural information about the repository files. They are also responsible for intelligent tag selection to classify the content accurately, as well as providing comprehensive summarization of files and analysis reports. Finally, they perform thorough reviews, acting as quality control mechanisms to critique and suggest improvement for the repository.
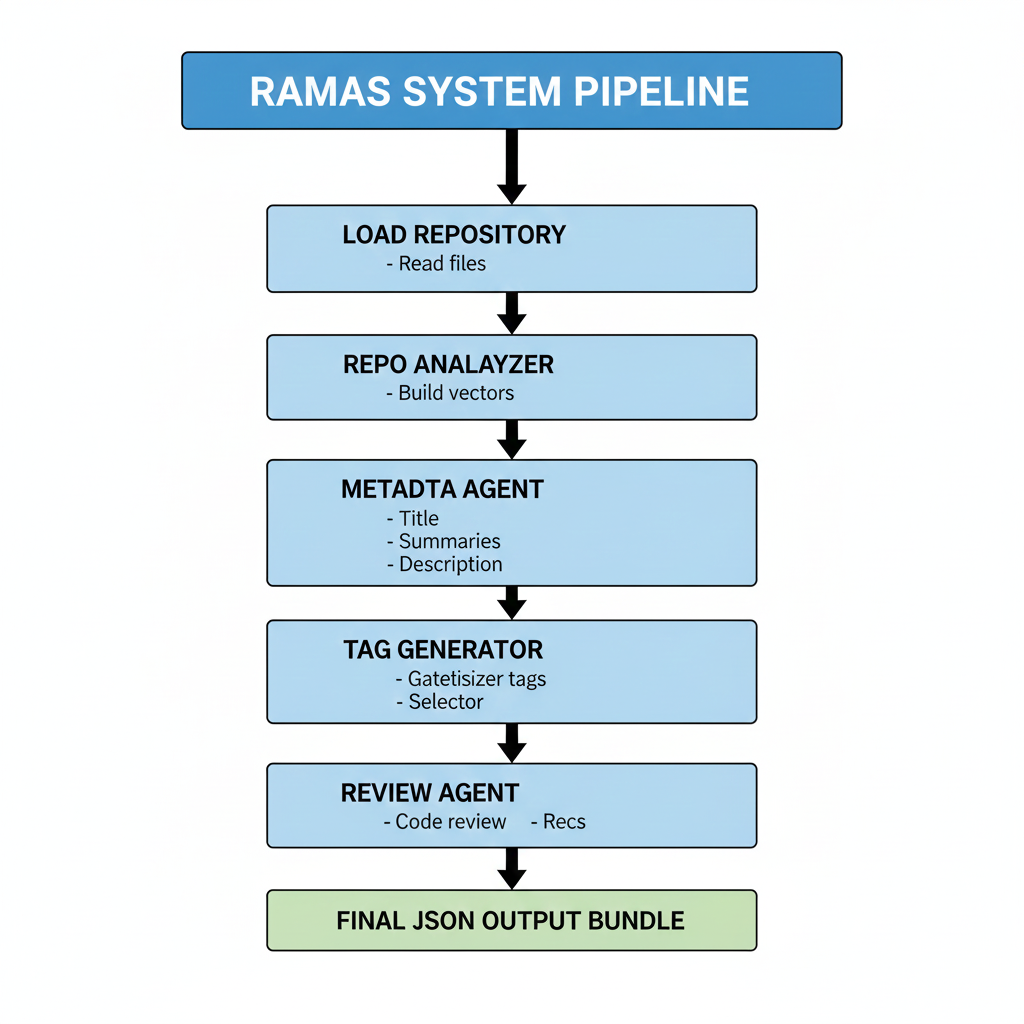
The Repo Analyzer Multi-Agent System (RAMAS) follows a deterministic assembly-line architecture implemented using a LangGraph Directed Acyclic Graph (DAG). In this design, agents do not communicate in an ad-hoc conversational manner; instead, they coordinate through a shared, evolving state object that is progressively enriched as it flows through the pipeline. This approach ensures reproducibility, modularity, and clear separation of responsibilities among agents.
At the core of RAMAS is the LangGraph pipeline, which acts as the orchestration layer. The DAG defines the execution order, dependencies, and data handoff rules between agents. Each agent is represented as a node in the graph and operates on a well-defined subset of the global state. Once an agent completes its task, it returns an updated state object, which is then passed downstream according to the DAG topology.
This architecture guarantees that:
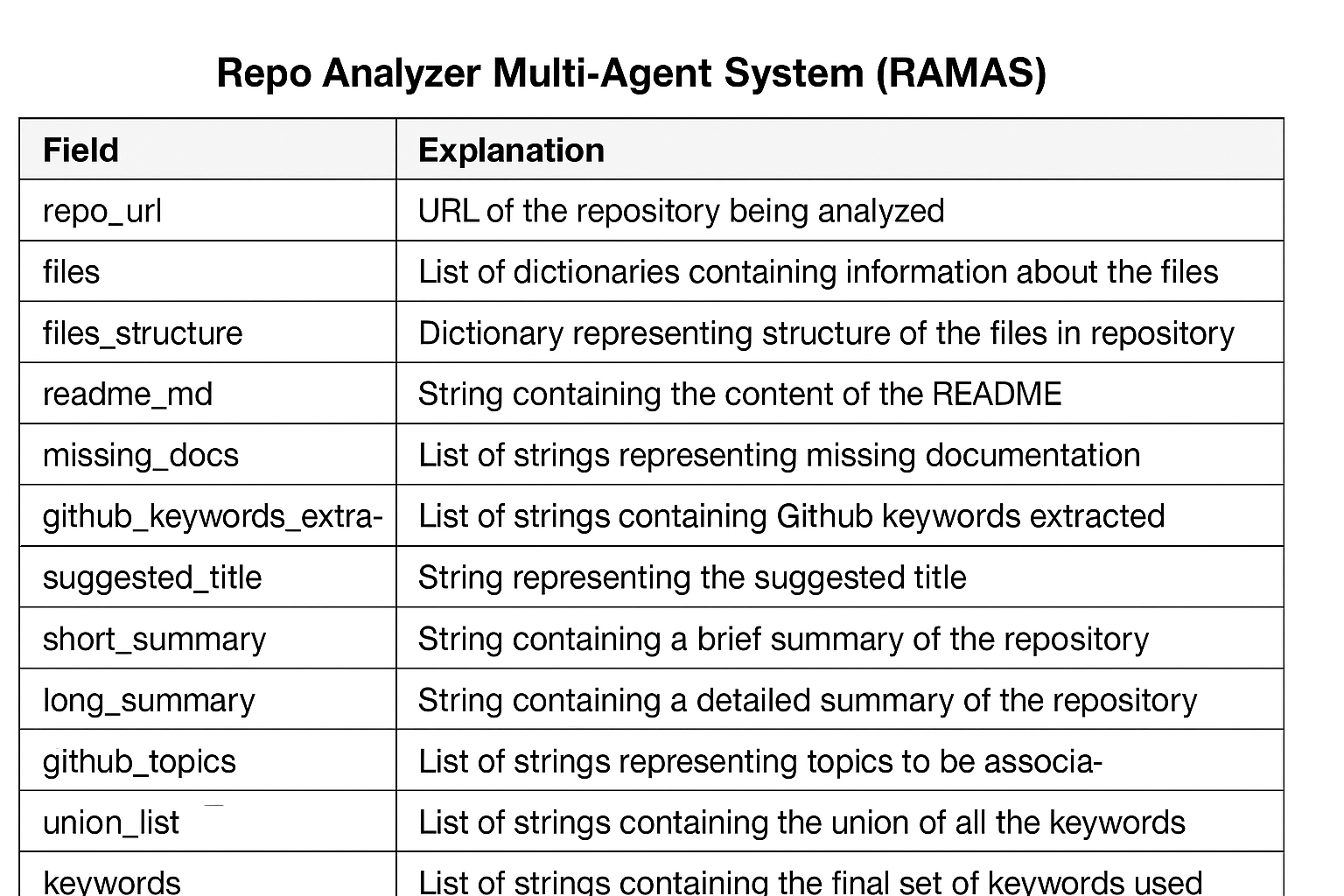
All inter-agent communication occurs through a unified JSON-based state bundle. Instead of direct message passing, agents read from and write to this shared state. This state includes repository metadata, extracted content, intermediate analysis results, and final outputs. By using structured fields, RAMAS ensures that each agent consumes only the data it needs and produces outputs in a predictable format for downstream agents.
The process begins when repository files and metadata (derived from the provided repository URL) are ingested into the system. This input initializes the shared state with raw file content, directory structure, and basic repository information.
The Repo Analyzer Agent performs low-level static analysis of the repository. It extracts the file structure, identifies important files (such as README.md, licenses, configuration files), detects missing documentation, and gathers raw textual content. Its output is appended to the shared state and passed to the Metadata Agent.
The Metadata Agent depends directly on this output. It enriches the state by normalizing repository information, consolidating extracted content, organizing summaries, and preparing structured metadata fields that are required by downstream agents.
Once the metadata layer is finalized, the Tag Generator Agent is triggered. It consumes cleaned textual content, README data, and structural metadata to generate semantic tags and keywords. This agent may apply multiple keyword extraction strategies (regex-based, spaCy, gazetteer-based, and LLM-assisted methods) and stores both intermediate and unified keyword lists back into the shared state.
The Repo Analyzer Agent, Metadata Agent, and Tag Generator Agent all feed into the Review & Improvement Agent. This agent acts as a convergence point in the DAG. It validates consistency across outputs, resolves conflicts (e.g., overlapping or noisy keywords), improves summaries, and synthesizes a coherent evaluation of the repository.
After validation and refinement, the Review & Improvement Agent produces the final unified JSON metadata bundle. This bundle represents the complete output of RAMAS and is suitable for downstream use cases such as repository indexing, search, recommendation systems, or documentation generation.
The RAMAS system primarily expects a single, mandatory input: containing the repository URL, which must be a string . While this URL is the only required input for basic operation, users must have to provide several additional configuration items. These include API keys for Groq (necessary for running the LLM nodes), a Gazetteer configuration YAML file ( for named entity recognition or specialized data lookups), and a prompt configuration file (to customize the instructions given to the LLM agents).
All prompts follow:
System Role: Defines persona, constraints, and output schema
Task Instruction: Action-specific
Output Constraints: Define rules for not to produce false output and to avoid hallucination
Output Format: Always JSON , Always validated
Goal: Final Instructions
The RAMAS system leverages several specialized tools and libraries to execute its pipeline. The core orchestration is managed by LangGraph, specifically utilizing its StateGraph functionality to define the structured, fault-tolerant execution flow. For all generative and analytical tasks, the system employs Groq LLMs, capitalizing on their speed for operations like summarization and review. Finally, SpaCy is integrated for robust NLP extraction (such as identifying keywords and entities), and standard YAML files are used for configuring specific parameters, particularly for tag and gazetteer definitions.






To run the Repo Analyzer Multi-Agent System (RAMAS), first create a Python virtual environment using
python -m venv venv
to isolate project dependencies. Activate the environment using
venv\Scripts\activate
on Windows or
source venv/bin/activate
on macOS/Linux, and deactivate it later with the deactivate command if needed. Once the environment is active, install all required packages by running
pip install -r requirements.txt
Next, configure the Groq API key by setting the GROQ_API_KEY environment variable in your terminal
$env:GROQ_API_KEY="your_api_key_here"
If additional dependencies are installed during development, they can be saved back into the requirements file using
pip freeze > requirements.txt
After completing these steps, the application can be executed by running
python code/_Runner.py
which initiates the full multi-agent analysis pipeline and produces the unified JSON output.
RAMAS is distributed under an open-source license, allowing users to study, modify, and extend the system for academic, research, or commercial purposes, subject to the terms of the selected license. Users are permitted to use the software in personal or organizational projects, provided that proper attribution is maintained and the original copyright notice is preserved. Redistribution of modified versions must comply with the same licensing terms, and any derived works should clearly indicate changes made to the original system. The project does not include warranties of any kind, and the authors are not liable for any damages resulting from the use of the software.
The RAMAS system currently operates with several key limitations. Analyzing large repositories necessitates significant computational resources, specifically requiring a GPU/TPU or Groq acceleration for efficient processing. Furthermore, the system is fundamentally restricted in the types of files it can handle, as it cannot analyze binary files; its capabilities are confined to text-based code and documentation.
The future development roadmap for the RAMAS system focuses on integrating more advanced analysis and utility features to significantly enhance its value proposition. Key planned enhancements include incorporating static code analysis integration to enable the detection of code smells, potential bugs, and adherence to coding standards directly within the repository files. A major planned feature is the capability to automatically generate UML diagrams (Unified Modeling Language) from the source code, providing visual representations of the system's structure and operational flow . Furthermore, implementing repository similarity search will allow users to efficiently discover other functionally or structurally similar codebases. For security, future versions will include integrated security vulnerability scanning to automatically check the code and dependencies against known risks.
The maintenance plan for the RAMAS system focuses on continuous refinement and adaptation to ensure its effectiveness and stability. This plan mandates a quarterly update of prompt templates to optimize the performance and output quality of the LLM agents. Furthermore, the Gazetteer keywords will be refreshed monthly to keep the specialized domain dictionaries current and relevant. To leverage the latest in AI technology, the plan includes the adoption of new LLM variants as they become available, particularly following Groq LPU upgrades. Crucially, a core objective of the maintenance strategy is to maintain backwards compatibility for the JSON schema, ensuring that the output structure remains consistent and usable for downstream systems and existing integrations.