The Ready Tensor Publication Explorer is your trusty AI buddy that makes research papers and articles easy to grasp. Toss in questions like “What’s this article about?” and get clear and short answers fast. Built with Retrieval-Augmented Generation (RAG) using LangChain, a persistent Chroma vector store, and Google’s Gemini 1.5 Flash; it is simple and smooth for students and curious minds exploring Ready Tensor publications.
Implementation is done using Python, leveraging these core tools and technologies:
The workflow of the application follows these steps:
Data Loading: The application pulls in a JSON file of publications which lists details like titles, authors, and descriptions.
Text Chunking: A document_loader script cleans articles text by stripping bold, italics, and HTML tags. It splits descriptions into 1000-character chunks with 200-character overlaps to capture full ideas, like paragraphs, while linking related text across chunks to maintain context.
Embedding Creation:
Each chunk is converted into a numerical vector using HuggingFace’s all-MiniLM-L6-v2 model, which encodes the text meaning for easy searching.
Vector Storage: Vectors are saved in a persistent Chroma vector store (chroma_db/), stored on disk for fast startups without rebuilding the database every time.
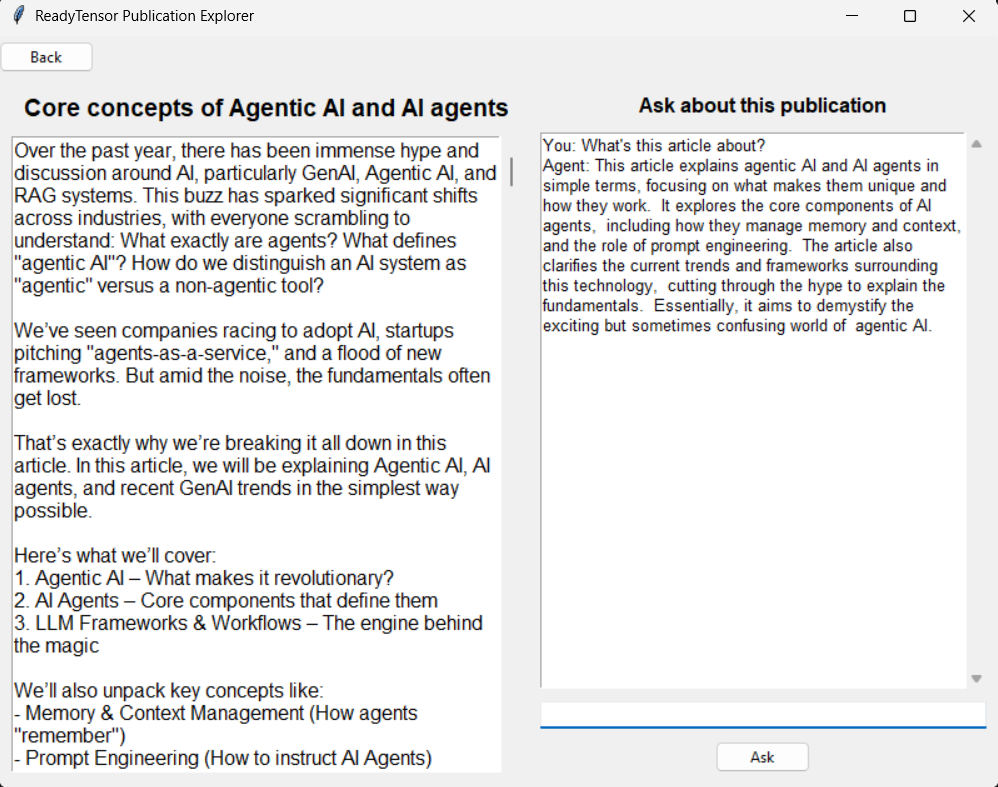
Question-Answering: When a question is asked, rag_pipeline uses LangChain to search Chroma for relevant chunks, filtered by publication ID to stay focused on the currently opened article or publication. These chunks are fed into a custom prompt, which instructs the Gemini API to craft an 80–100 word answer in plain, jargon-free language. The prompt ensures answers stick to the provided context, avoid buzzwords or hype, and politely decline out-of-scope or inappropriate questions. Then, LangChain combines chunks and prompt in an efficient model call.
Interaction: A simple interface (built with Tkinter), supports browsing publications and asking questions about a specific, selected one.
1. Clone the repo
2. Install dependencies:
pip install -r requirements.txt
Note: install tkinter too if not included.
3. Acquire a Gemini API key:
Gemini API (Navigate to "APIs & Services", "Enable APIs and services", and Search for "Gemini API" and enable it)4. Create a .env file in this project's root and include the Gemini API key there:
GEMINI_API_KEY=your-api-key-here
5. Run:
python run.py
The application should open to a screen listing available publications. Clicking any of them should move to a second screen displaying the content of the selected article and a chat box that allows asking the agent about that current article.