RAG Wiki Assistant is a lightweight RAG-based Q&A app that answers user queries by restricting the responses in Wikipedia-sourced documents. The app demonstrates how reliable, source-bound answers can be produced without hallucinations by combining retrieval and generation proper prompting. Also, by grounding answers to specific AI/ML and LLM-related Wikipedia articles, the system offers an open, transparent and reproducible example of building trustworthy domain-focused assistants for education and research. This project combines a lightweight preprocessing pipeline that turns .txt files into dense vector embeddings, a ChromaDB vector store for retrieval, HuggingFace embeddings, LangChain orchestration for chunking and prompt templates, and GROQ as the generative model for answer composition. The repository includes clear instructions, YAML configuration, ingestion scripts, and a Streamlit interface so others can replicate or extend the system with their own topics or datasets.
Modern question-answering systems increasingly rely on retrieval-augmented generation (RAG) to combine the factual grounding of a document collection with the expressive ability of a generative model. Wikipedia is an attractive knowledge source: it is broad, well-structured, and frequently updated. In this project, I built a wikipedia assistant that strictly limits the model's output to evidence found inside the supplied Wikipedia documents. The key goals were:
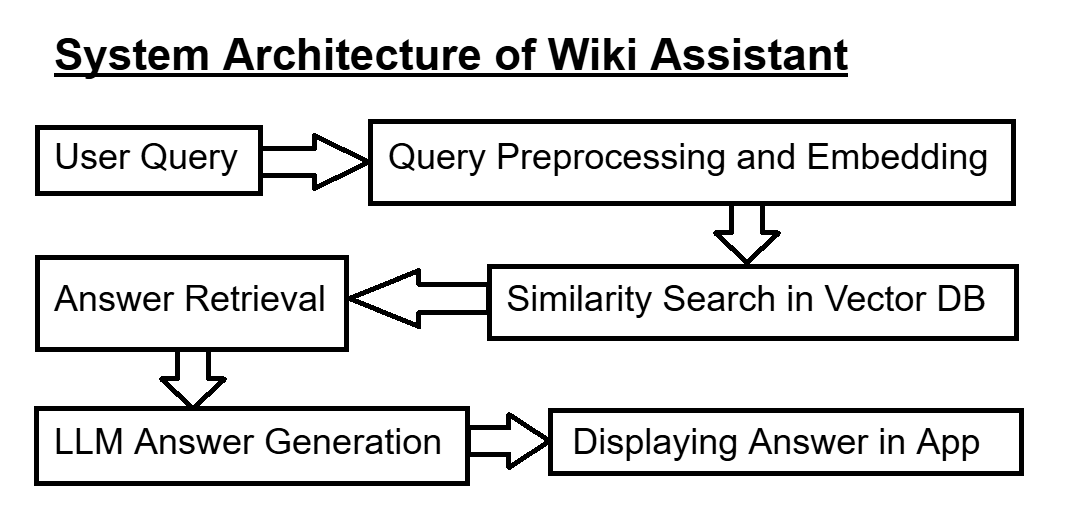
In this section, I'll first outline the complete pipeline — from data extraction to final answer generation — and then map each stage to its corresponding directory or file within the repository.
wikipediaapi library..txt file inside a dedicated data/ folder at the project’s root.wiki_pages) and a persistent directory (./chroma_db). The collection name and persistent directory are already mentioned as parameter for the initializing function found inside the vectordb_and_ingestion module.The
./chroma_dbdirectory is ignored using .gitignore so it won't be found in the repo.
.txt file is split into overlapping text chunks using LangChain’s RecursiveCharacterTextSplitter (using 1,000 characters per chunk, 200-character overlap).all-MiniLM-L6-v2 via LangChain’s HuggingFaceEmbeddings wrapper.⚠️ Warning: this is done for experimental and demonstration purposes only. Exposing the system prompt in real production environments could raise a security and integrity risk
rag-wiki-assistant/ ├─ app/ │ └─ app.py # Main Streamlit application ├─ code/ │ └─ config/ │ ├─ config.yaml # App-level settings │ └─ prompt_config.yaml # RAG prompts │ ├─ data_extraction.py # Extracts the relevant wikipedia articles using wikipediaapi in .txt format │ ├─ loader.py # Loads YAML configuration files │ ├─ logger.py # Minimal logging setup │ ├─ prompt.py # Prompt builder │ ├─ retrieval_and_response.py # Handles retrieval & LLM response │ ├─ vectordb_and_ingestion.py # Initializes the VectorDB and Feeds the files to ChromaDB ├─ data/ # Holds 25 .txt files ├─ images/ # Screenshots of app results ├─ requirements.txt # Python dependencies ├─ .gitignore ├─ LICENSE # MIT License └─ README.md
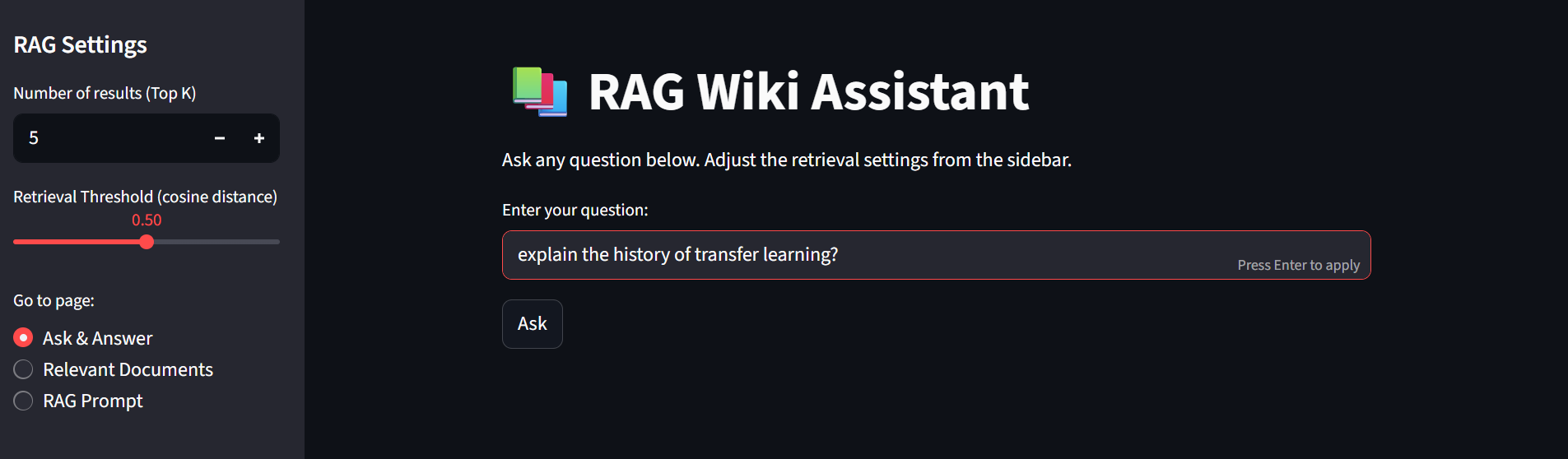


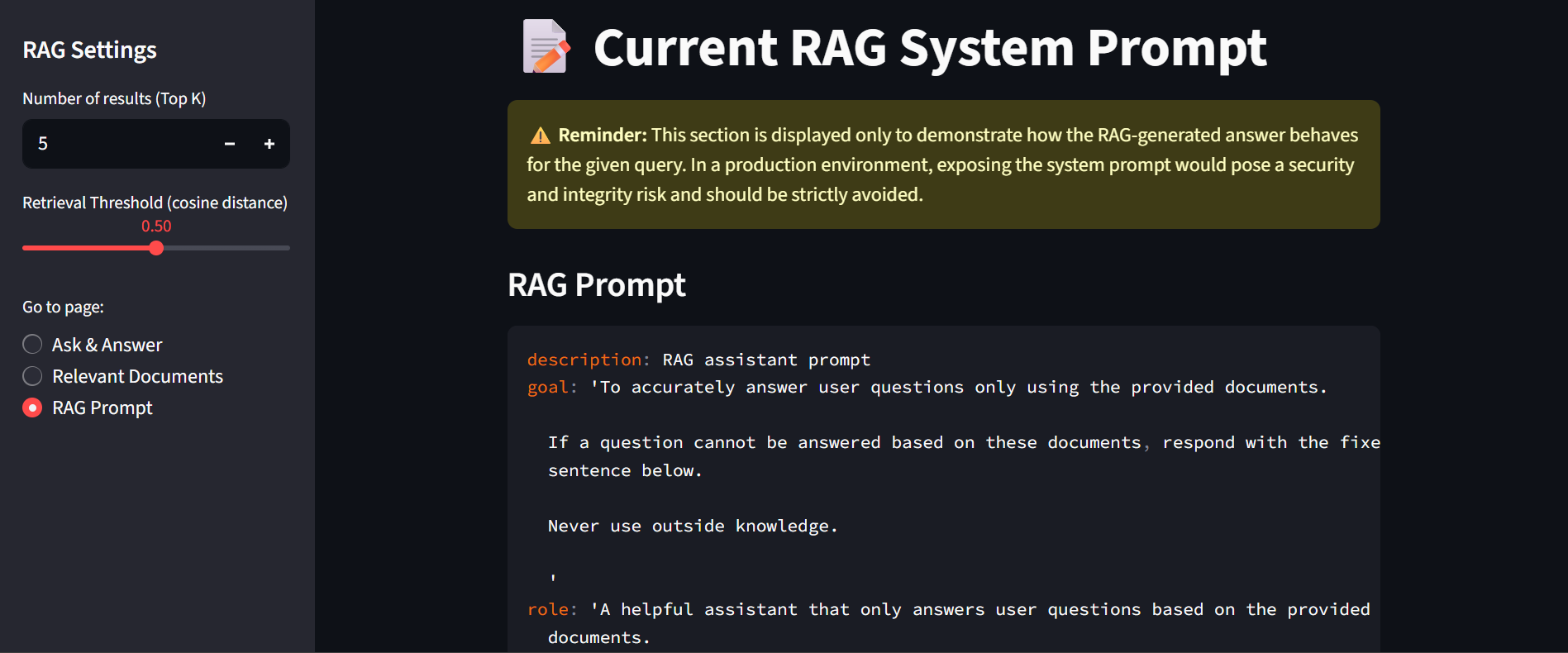
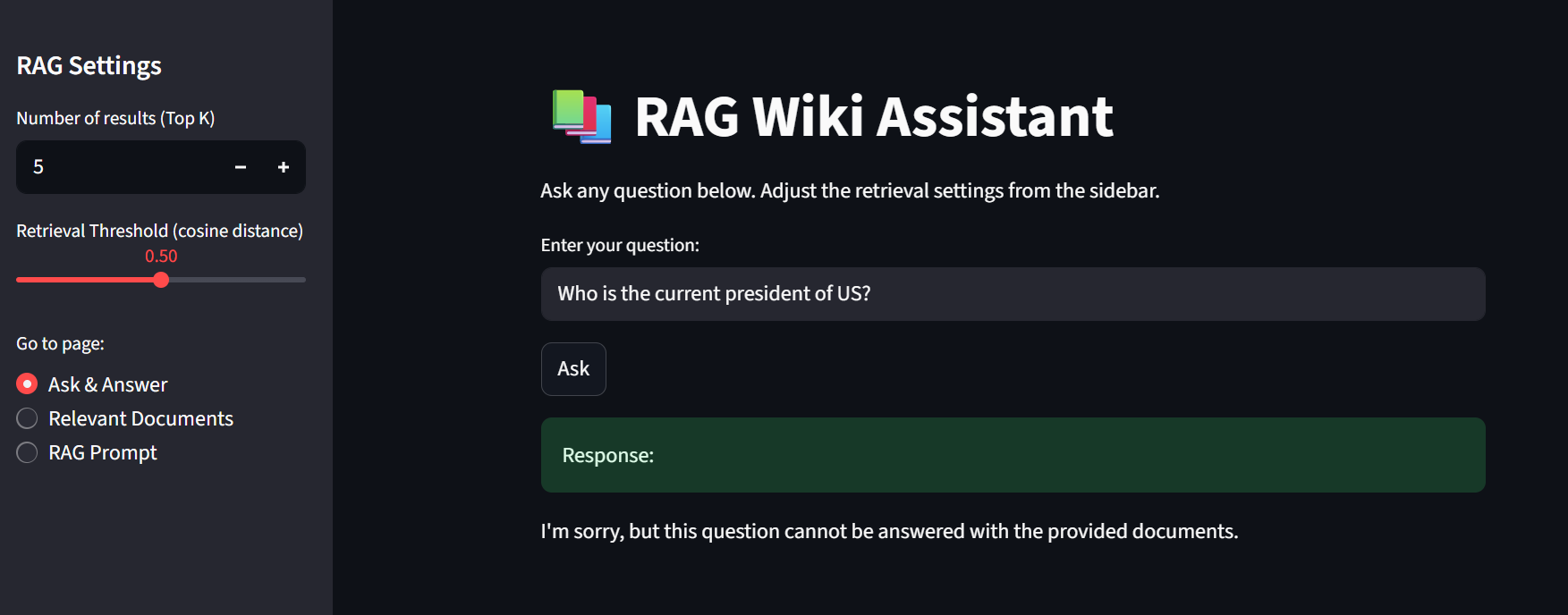
This Demo can also be found in the repo's README
Functional Outcome: The RAG Wiki Assistant successfully retrieves and generates answers restricted to the AI/ML and LLM-related Wikipedia articles. All user queries tested during the demonstration returned responses grounded in these documents only, with no observed hallucinations.
Performance: The system achieves fast retrieval and answer generation, owing to the use of ChromaDB for vector storage and efficient Hugging Face embeddings. Similarity search consistently returned the most relevant chunks, demonstrating the robustness of the chosen embedding model and chunking strategy.
User Experience: Through the Streamlit interface, the assistant displays retrieved content and generated answers clearly, allowing users to verify the source context.
Reproducibility: The pipeline, including data extraction, ingestion, and retrieval steps, has been documented and can be replicated by following the provided repository structure and YAML configuration files. Users can replace the source dataset with other topics to create their own domain-focused assistants.
This project demonstrates that a lightweight Retrieval-Augmented Generation (RAG) pipeline can be implemented with open-source tools to produce trustworthy, source-grounded answers. By combining Wikipedia content with LangChain-based chunking, Hugging Face embeddings, ChromaDB storage, and a GROQ-powered LLM, the assistant illustrates a reproducible template for domain-specific question-answering systems. Also, this repository can be implemented for almost any basic RAG apps by just changing the files in the documents, updating the system prompt and a few tweaks to the models.
The Wiki Assistant is currently maintained as an open-source research prototype. Future work will focus on expanding support for new data sources and improving retrieval performance. Community contributions and issue reporting are actively encouraged via the GitHub repository.
Contact me: leoulteferi1996@gmail.com