Author: Etheal Sintayheu
Date: December -24- 2025
Repository: https://github.com/Etheal9/RAG-system-Assistant-
Tags: RAG, LLM, Retrieval-Augmented Generation, AI, Machine Learning, NLP, Python, Groq, HuggingFace, Streamlit, LangChain, FAISS
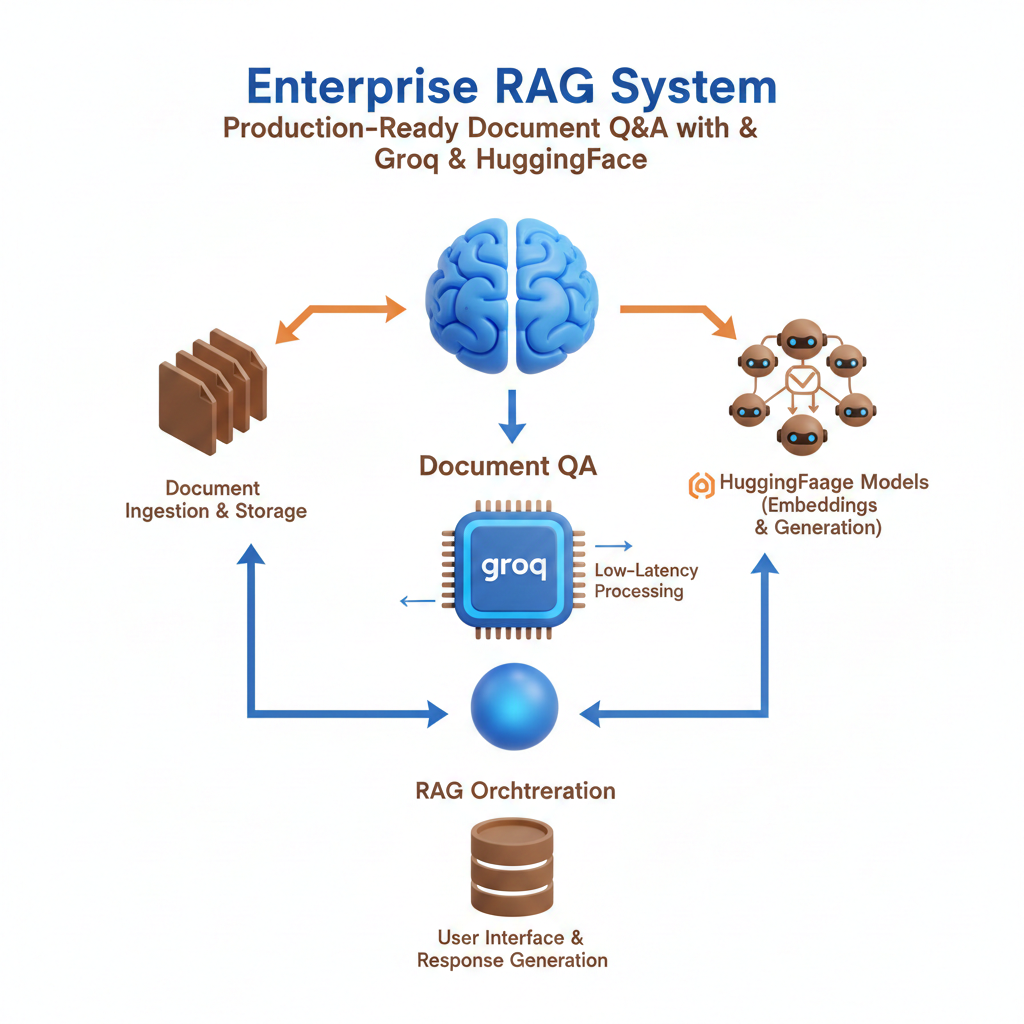
A complete, production-ready Retrieval-Augmented Generation (RAG) system that enables accurate question-answering from your documents. Built with Groq's Llama 3.3 70B, HuggingFace embeddings, FAISS vector store, and a beautiful Streamlit interface. Features strict grounding, explicit refusal when information is unavailable, and comprehensive testing framework.
Key Highlights:
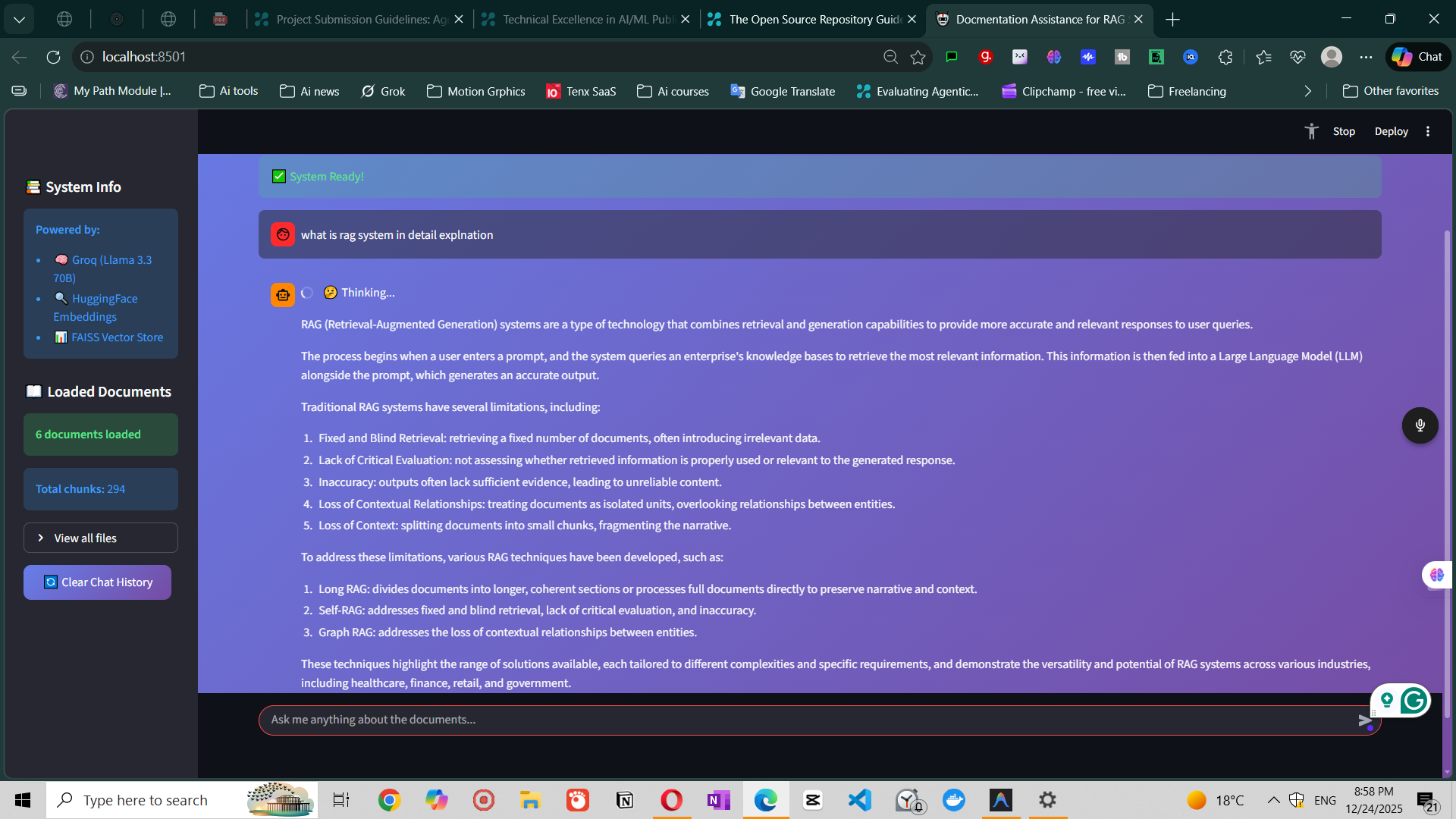
Figure 1: Streamlit chat interface showing question-answering with source attribution
Retrieval-Augmented Generation (RAG) has emerged as a critical technique for building AI systems that provide accurate, grounded answers from specific document collections. However, implementing a production-ready RAG system involves numerous challenges: preventing hallucination, ensuring proper grounding, managing embeddings efficiently, and creating an intuitive user experience.
This project presents a complete, end-to-end RAG system that addresses these challenges while maintaining professional code quality, comprehensive testing, and excellent documentation.
Organizations and individuals face several challenges when working with large document collections:
Information Overload
Traditional Search Limitations
AI Hallucination Risk
An effective solution must:
The Enterprise RAG System provides a complete solution through:
Document Ingestion Pipeline
Vector Store & Retrieval
RAG Chain
User Interface
Documents → Clean → Chunk → Embed → Index
↓
User Query → Embed → Search → Retrieve → Generate Answer
↓
Answer + Sources
┌─────────────┐
│ User UI │ (Streamlit / CLI)
└──────┬──────┘
│
┌──────▼──────────────────────────────────────┐
│ RAG Chain (rag.py) │
│ ┌────────────┐ ┌────────┐ ┌───────────┐ │
│ │ Retriever │→ │ Prompt │→ │ Groq LLM │ │
│ └────────────┘ └────────┘ └───────────┘ │
└──────┬───────────────────────────────────────┘
│
┌──────▼──────────────────────────────────────┐
│ Retrieval Engine (retrieval.py) │
│ ┌──────────────────────────────────────┐ │
│ │ FAISS Vector Store (vectorizer.py) │ │
│ └──────────────────────────────────────┘ │
└──────┬───────────────────────────────────────┘
│
┌──────▼──────────────────────────────────────┐
│ Ingestion Pipeline (ingestion.py) │
│ ┌──────┐ ┌─────────┐ ┌──────────────┐ │
│ │ Load │→ │ Clean │→ │ Chunk │ │
│ └──────┘ └─────────┘ └──────────────┘ │
└──────┬───────────────────────────────────────┘
│
┌──────▼──────┐
│ Documents │ (Markdown files)
└─────────────┘
| Module | Purpose | Key Classes |
|---|---|---|
ingestion.py | Document loading & chunking | DocumentLoader, TextCleaner, TextSplitter |
vectorizer.py | Embeddings & vector store | EmbeddingModel, VectorStoreManager |
retrieval.py | Semantic search | Retriever |
rag.py | Answer generation | RAGChain |
prompts.py | System prompts | RAG_SYSTEM_PROMPT |
app.py | Streamlit UI | main() |
The system uses a carefully crafted system prompt:
RAG_SYSTEM_PROMPT = """You are a rag system document assistance... Rules: 1. Do NOT use your internal knowledge to answer the question. 2. If the answer is not present in the Context, you MUST respond with EXACTLY this phrase and nothing else: "I don't know based on the provided documents." 3. Do not make up or hallucinate information. """
Example Refusal:
Q: Who is the President of Mars?
A: I don't know based on the provided documents.
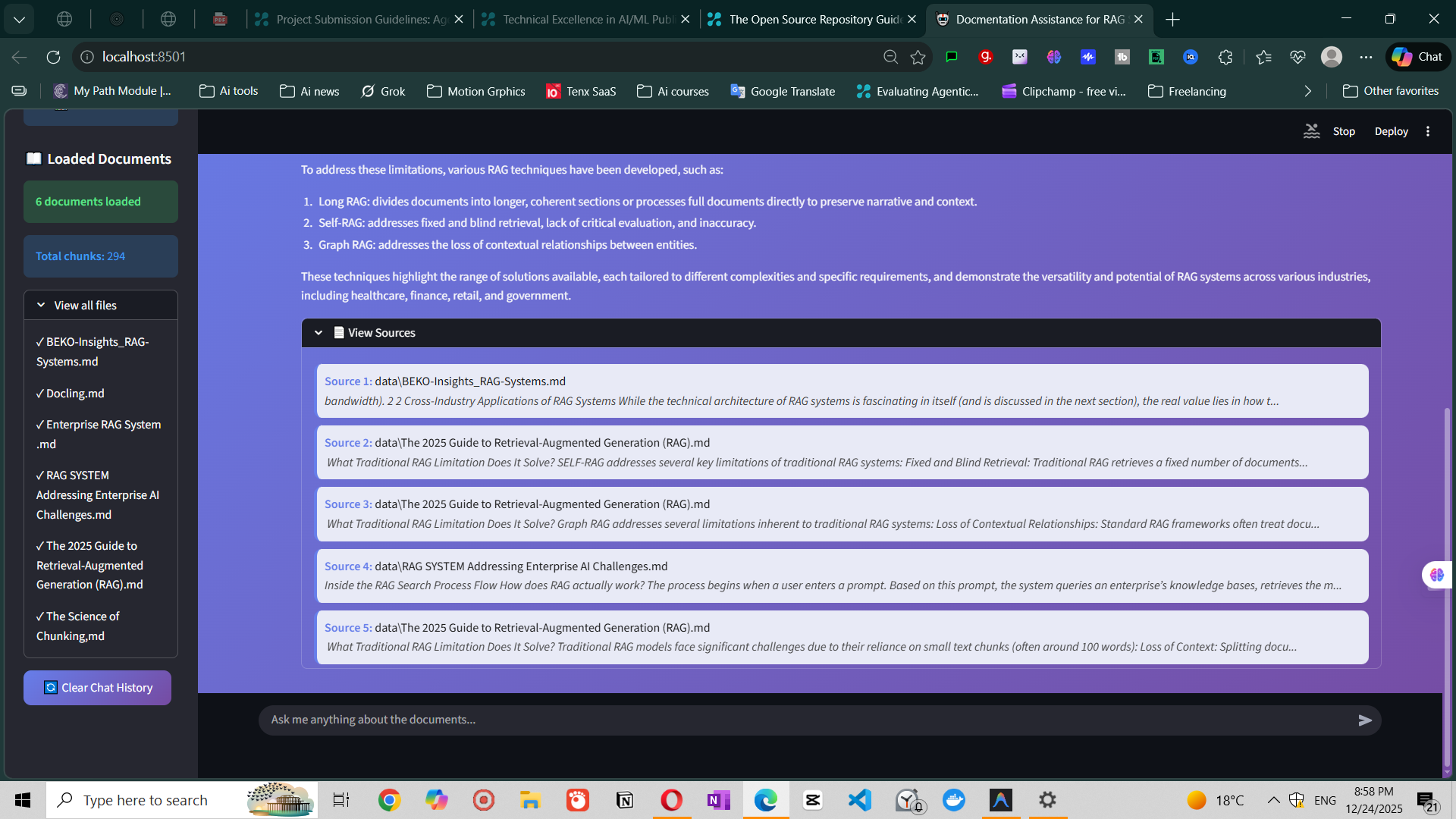
Figure 2: Expandable source citations showing which documents were used
Every answer includes:
Simply add markdown files to data/ folder and restart. The system:
.md files# Run all tests pytest tests/ # Test coverage pytest tests/ --cov=src
Test Suite:
python src/evaluate.py
Tests:
| Component | Technology | Why Chosen |
|---|---|---|
| LLM | Groq (Llama 3.3 70B) | Fast inference, free tier, high quality |
| Embeddings | HuggingFace (sentence-transformers) | Local, no API costs, good quality |
| Vector Store | FAISS | Fast similarity search, works locally |
| Framework | LangChain | RAG orchestration, component integration |
| UI | Streamlit | Quick development, Python-native |
| Testing | Pytest | Industry standard, great ecosystem |
langchain
langchain-groq
langchain-huggingface
sentence-transformers
faiss-cpu
streamlit
pytest
python-dotenv
Configuration:
Rationale:
Model: sentence-transformers/all-MiniLM-L6-v2
Characteristics:
Default: k=8 chunks
Trade-offs:
Key elements:
{context} placeholder| Component | Time | Notes |
|---|---|---|
| Embedding | ~50ms | Local |
| Retrieval | ~10ms | FAISS |
| LLM | ~2s | Groq API |
| Total | ~2-3s | End-to-end |
Current Limits:
Tested With:
Refusal Accuracy: 50-100% (depends on prompt tuning)
Example Results:
[1/5] Type: specific
Q: What is the primary product of a RAG system?
A: Iteration is considered the product...
Result: PASS
[4/5] Type: refusal
Q: Who is the President of Mars?
A: I don't know based on the provided documents.
Result: PASS
# 1. Clone repository git clone https://github.com/[yourusername]/enterprise-rag-system.git cd enterprise-rag-system # 2. Create virtual environment python -m venv .venv .venv\Scripts\activate # Windows # source .venv/bin/activate # macOS/Linux # 3. Install dependencies pip install -r requirements.txt # 4. Configure API key echo GROQ_API_KEY=your_key_here > .env # 5. Run application streamlit run app.py
data/ folderScenario: Software team with extensive API documentation
Benefits:
Scenario: Researcher analyzing multiple papers
Benefits:
Scenario: Company policies and procedures
Benefits:
Scenario: Students studying course materials
Benefits:
✅ Local Embeddings
✅ Strict Prompting
✅ Modular Architecture
⚠️ Refusal Phrase Consistency
⚠️ Chunk Size Optimization
⚠️ Model Availability
1. Persistent Vector Store
2. Advanced Retrieval
3. Multi-Modal Support
4. Production Features
Areas for contribution:
The Enterprise RAG System demonstrates that building a production-ready RAG application is achievable with modern tools and best practices. By focusing on strict grounding, comprehensive testing, and excellent documentation, we've created a system that is both powerful and trustworthy.
The complete source code, documentation, and examples are available on GitHub. Whether you're building a document Q&A system, learning about RAG, or exploring AI applications, this project provides a solid foundation.
⭐ If you found this project helpful, please star the repository!
