RAG services pipeline
RAG services pipeline
When building a generative AI project, such as RAG, an advanced generative AI reference architecture, you need to think about how to incorporate its important components. These components include databases, knowledge bases, retrieval systems, vector databases, model embeddings, large language models (LLMs), inference engines, prompt processing, guardrail, fine-tuning services, and more.
In short, RAG allows users to choose which applications and specific tasks to use. The workflow below focuses on using Charmed OpenSearch and KServe. Even though there is no fine-tuning involved, we can see that it can enhance the performance of an LLMs at project scales.
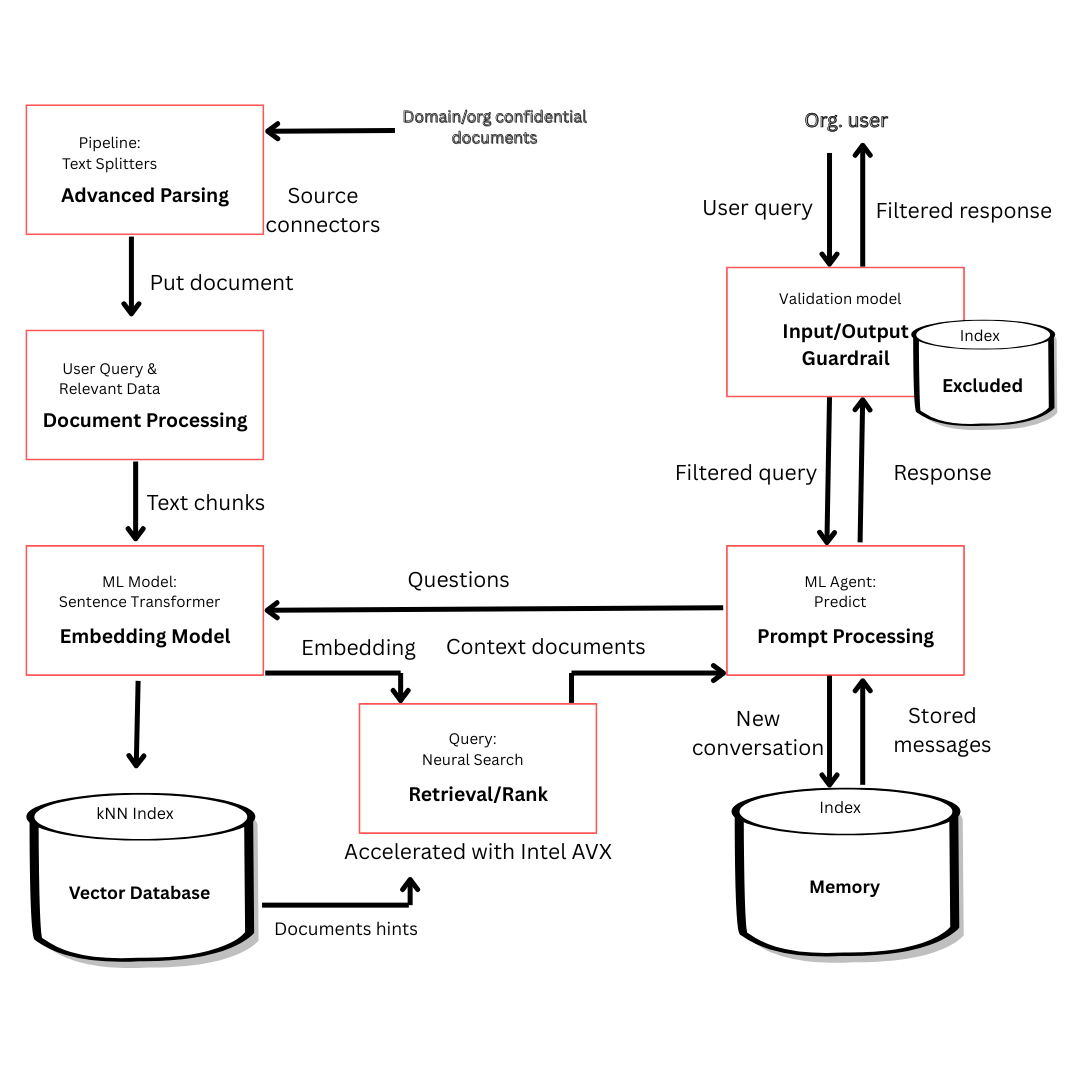
Now let's break down the workflow one by one.
Advanced parsing
Text splitters are advanced parsing techniques for documents entering a RAG system, so that only clear and informative input is provided. (Charmed Kubeflow)
Ingestion/data processing
This one is for the data pipeline layer, mainly for data extraction, cleansing, and removing unwanted data. (Charmed OpenSearch)
Embedding model
machine-learning to convert raw data back into vectors. (Charmed OpenSearch - Sentence transformer)
Retrieval and ranking
This section takes data from the knowledge base and ranks the information retrieved based on relevance scores. (Charmed OpenSearch with FAISS)
Vector database
The above is a db that stores vector embeddings for retrieval and ranking. (Charmed OpenSearch - KNN Index)
Prompt processing
Queries and retrieved text are converted into a readable format, so they are structured for LLM. (Charmed OpenSearch)
Guardrail
GenAI uses it as a filter to ensure ethical content for both input and output. (Charmed OpenSearch: guardrail validation model) Let's talk about Charmed OpenSearch in the next section.