This project implements a Retrieval-Augmented Generation (RAG) chatbot designed as an AI tutor for students. It leverages Groq’s LLMs for fast inference, HuggingFace embeddings for semantic understanding, and ChromaDB for vector-based document retrieval. By ingesting custom knowledge bases (e.g., textbooks, lecture notes, PDFs), the chatbot delivers context-aware, accurate, and personalized responses. The system is modular, production-ready, and optimized for educational use cases.
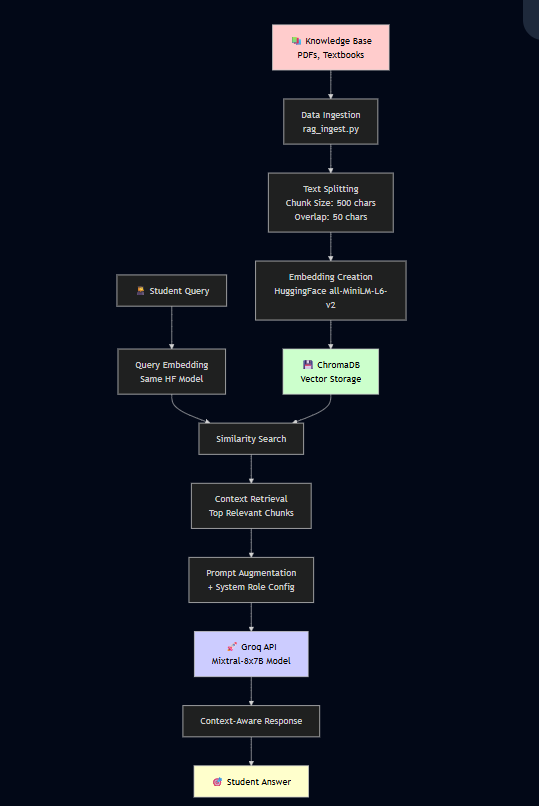
The chatbot follows a standard RAG pipeline:
![RAG Architecture Diagram]
Data Ingestion
rag_ingest.py.Chatbot Pipeline (student_chatbot.py)
config/).Logging & Debugging
Conversation Flow
The choice of models is critical to the performance, cost, and speed of the system.
Embedding Model: all-MiniLM-L6-v2
This sentence-transformers model was selected for its excellent balance between performance and computational efficiency. It maps sentences and paragraphs to a 384-dimensional dense vector space and is well-suited for semantic search tasks like those in this RAG system. Its small size makes it fast for both encoding documents and querying the vector database, which is ideal for a responsive chatbot.
Large Language Model: Mixtral-8x7b via Groq
The Mixtral-8x7B model is a high-quality, open-weight Sparse Mixture of Experts (SMoE) model known for its strong reasoning and instruction-following capabilities. It was chosen for its state-of-the-art open-weight performance. We access it via the Groq API primarily for its unparalleled inference speed. Groq's LPU™ inference engine delivers near-instantaneous responses, which is a fundamental requirement for creating an engaging and natural conversational experience for students, eliminating frustrating wait times.
Effective chunking is essential for retrieving meaningful context. We use LangChain's RecursiveCharacterTextSplitter to split documents by paragraphs while respecting natural language boundaries like \n\n.
This project is actively maintained. The current implementation is built with the following core dependencies:
langchain-core==0.1.xchromadb==0.4.xgroq==0.3.xFor support, please open an issue on the project's GitHub repository. Contributions, bug reports, and feature suggestions are welcome. The MIT License allows for free use, modification, and distribution, provided the license is included.
week3/
│── student_chatbot.py # Chatbot loop with Groq + Chroma
│── rag_ingest.py # PDF ingestion + vectorization
│── helper.py # Utility functions
│── paths.py # Config paths
│── data/ # PDF knowledge base
│── student_knowledge_base/ # Persisted ChromaDB store
│── config/ # App + Prompt YAML configs
│── LICENSE.md (MIT) # Open-source license
│── README.md # Documentation
# Step 1: Ingest PDFs into ChromaDB python rag_ingest.py # Step 2: Run the chatbot python student_chatbot.py
Type exit to quit the chatbot.
This project is released under the MIT License, encouraging open collaboration, adaptation, and deployment in academic and research contexts.