
Type: Software Tool + Real-World Application
Goal: Showcase how RAG enables domain-specific expertise from general-purpose language models
This project demonstrates how Retrieval-Augmented Generation (RAG) enhances a language model’s capabilities by connecting it to a curated knowledge base. The integration empowers the model to generate accurate, context-aware, and evidence-backed responses, combining the creativity of generative AI with the reliability of verified data.
Whether you're building legal assistants, educational tools, or enterprise support bots — this RAG approach bridges the gap between language fluency and domain trust.
Many researchers and engineers face the limitations of LLMs when they need accurate responses in niche areas. I show how easily you can integrate custom data into LLMs using a modern RAG stack, allowing for factual and source-grounded answers.
It will be particularly useful for researchers and academics who want to interactively query their own scientific literature. Students and educators can leverage this chatbot to build personalized educational tools. Additionally, AI/ML engineers working on products that integrate RAG workflows will benefit from the hands-on approach and modular design. Finally, the project may also be of interest to potential employers looking for candidates experienced with LangChain, ChromaDB, and generative AI pipelines, as it showcases real-world application and technical implementation.
The process begins with document chunking, where large files such as PDFs, HTML pages, or plain text are split into manageable pieces to improve semantic understanding and retrieval accuracy. These chunks are then transformed into numerical representations through embedding generation, typically using models like OpenAIEmbeddings or other compatible embedding techniques.
The resulting vectors are stored in ChromaDB, a vector database that supports both local and cloud-based deployments. During user interaction, the system performs semantic retrieval of the most relevant document chunks and passes them into a prompt template for LLM-based response generation using LangChain or LlamaIndex.
The interface is built using Streamlit and supports:
Uploading PDF files
Entering user queries
Displaying structured responses with links to sources

Local launch: no cloud connection required
Fast PDF document indexer
Flexibility in updating the knowledge base
Ability to adapt to new domains (law, medicine, education, etc.)
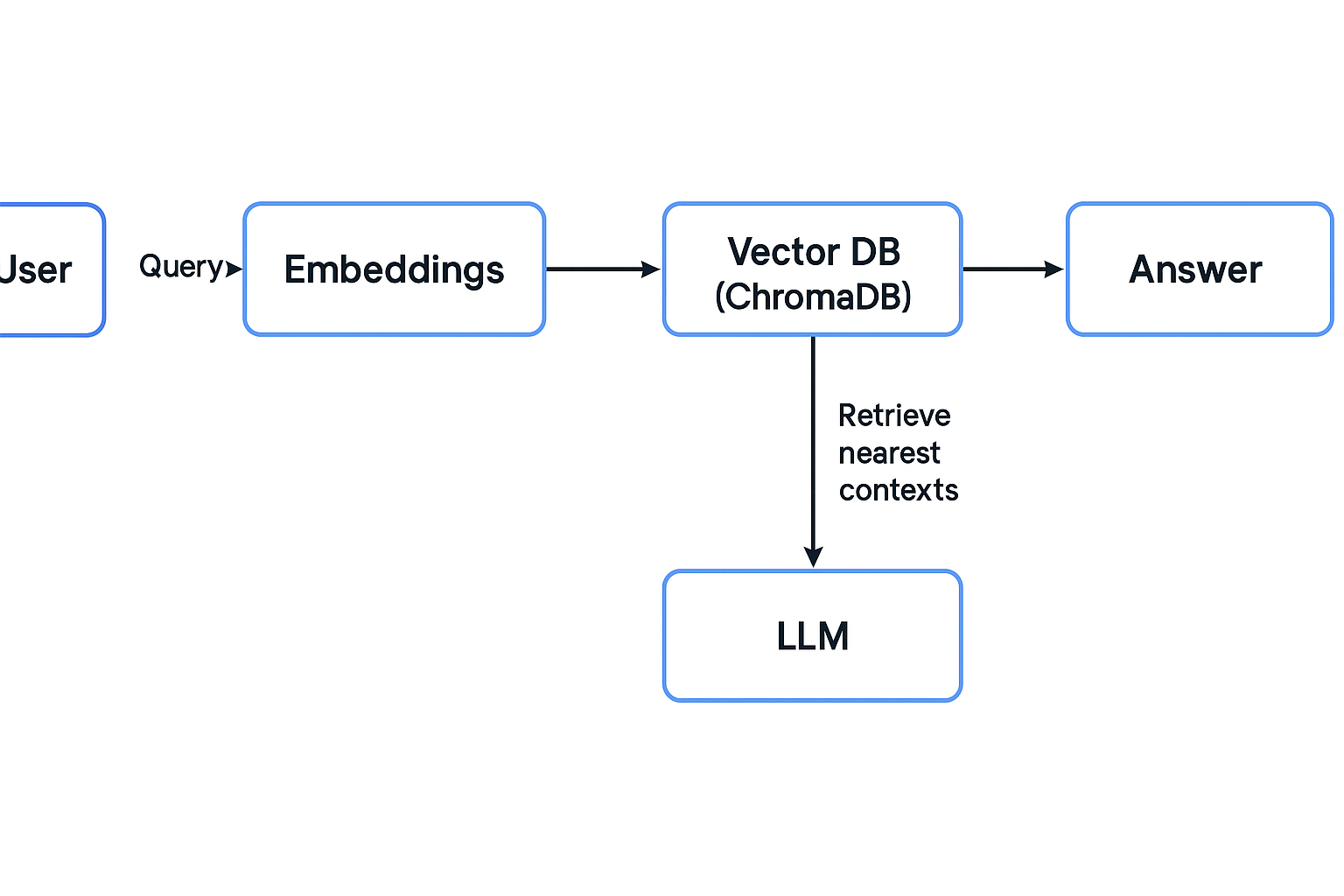
We showcase a Retrieval-Augmented Generation (RAG) pipeline that transforms a general-purpose language model into a focused domain expert. Here’s how each component fits together:
Setting Up the Knowledge Base
We begin with a curated collection of domain-specific documents — for example, scientific papers or policy reports. These form the foundation of our chatbot’s knowledge.
Loading the Publications
Using PDF or text loaders, we extract clean, structured text from the source documents. This step ensures we’re working with high-quality data.
Chunking Our Publications
Next, we split the documents into smaller, overlapping text chunks. This makes it easier for the system to retrieve relevant content later and maintain context during generation.
Creating Embeddings
We convert each text chunk into a vector embedding that captures its semantic meaning. This allows us to compare a user’s query with the most relevant pieces of information in our corpus.
Storing in a Vector Database
These embeddings, along with their metadata, are stored in ChromaDB — a fast, local vector store. This enables efficient retrieval during chat sessions.
Intelligent Retrieval
When a user asks a question, the chatbot searches for the most relevant chunks using vector similarity. This ensures that answers are backed by real, source-based content.
Generating Research-Backed Answers
Finally, we combine the retrieved chunks with a Large Language Model (LLM) using LangChain.
The result: answers that are coherent, grounded, and traceable to the original documents.
Here is a short code snippet that demonstrates how PDF file indexing works:
from langchain.document_loaders import PyPDFLoader from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings loader = PyPDFLoader("myfile.pdf") pages = loader.load_and_split() embedding = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") vectorstore = Chroma.from_documents(pages, embedding=embedding)
The Retrieval-Augmented Generation (RAG) Flow defines the full lifecycle of a query through the system — from user input to final answer. It visually and conceptually maps how components like the retriever, vector database, and LLM interact.
Understanding the RAG flow is essential because it:
| Step | Description |
|---|---|
| User Query | The user submits a question or input |
| LangChain Retriever | The retriever searches for relevant documents using LangChain |
| ChromaDB Search | The vector database (ChromaDB) finds relevant chunks |
| Relevant Chunks | Retrieved document chunks are passed on |
| Prompt Template | A prompt is generated using the retrieved chunks |
| LLM Generation | The language model generates a response |
| Streamlit Response | The response is displayed in the Streamlit interface |
Text chunking is the process of splitting large documents into smaller, manageable parts (chunks) before indexing them in a vector database like ChromaDB.
Most LLMs (Large Language Models) have a context window limit (e.g., 4K–32K tokens), so feeding in an entire document is often not feasible. Chunking helps by:
Chunking Strategy Used
| Parameter | Value |
|---|---|
| Chunk Size | 512 tokens |
| Chunk Overlap | 128 tokens |
Overlapping ensures that important context (like a legal clause that spans pages) isn't lost between chunks.
How It Works in Practice?
The system follows a clear and efficient pipeline to deliver relevant, high-quality responses:
First, uploaded documents are segmented into manageable parts using a token-based chunking method. These chunks are then transformed into dense vector embeddings that capture their semantic meaning. Finally, all vectorized chunks are stored in ChromaDB, a fast and scalable vector database.
When a user asks a question, the system retrieves the most relevant chunks based on semantic similarity and generates a grounded answer using a language model.
To evaluate how well the retrieval system supports the chatbot’s responses, we use several key retrieval metrics. These metrics help determine how relevant and complete the retrieved information is before it reaches the LLM.
In RAG systems, the quality of retrieved chunks directly affects the accuracy and usefulness of generated answers. Without relevant documents, even the best LLMs can "hallucinate" or produce vague responses.
To ensure the quality of document retrieval in our RAG-based chatbot, we evaluated the retriever using key information retrieval metrics.
| Metric | Description |
|---|---|
| Recall@k | Whether any relevant document is in the top‑k results |
| Precision | Proportion of retrieved documents that are actually relevant |
| mAP | Mean average precision across varying values of k |
How Recall@k Works?
For each user query, the retriever returns a ranked list of documents. Recall@k checks if any of the ground-truth relevant documents are present among the top-k retrieved ones.
For example, if the true relevant document is doc42 and it's retrieved at position 2 in the top 3,
then Recall@3 = 1.
When to use these metrics?
Use them:
def recall_at_k(retrieved_docs, relevant_docs, k): """ Returns 1 if at least one relevant document appears in the top-k retrieved results. """ return int(any(doc in relevant_docs for doc in retrieved_docs[:k])) # Example usage across queries all_recalls = [] for example in test_set: retrieved = example['retrieved_ids'] relevant = set(example['ground_truth_ids']) all_recalls.append(recall_at_k(retrieved, relevant, k=3)) recall_at_3 = sum(all_recalls) / len(all_recalls) print(f"Recall@3: {recall_at_3:.2f}")
Get started locally in just a few steps:
git clone https://github.com/sahilk12nayak/PDF-Reader-ChatBot-Using-RAG.git cd PDF-Reader-ChatBot-Using-RAG
python -m venv venv source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt
Create a .env file in the root folder with:
OPENAI_API_KEY=your_openai_key
You can switch to Hugging Face models by adjusting the config.
streamlit run app.py
The chatbot will open in your browser at http://localhost:8501/.
Tip: Upload any PDF, .txt, or .md file and ask questions in plain English.
The app will retrieve relevant chunks and generate context-aware answers using RAG.
These test results demonstrate the thoroughness of our development process.
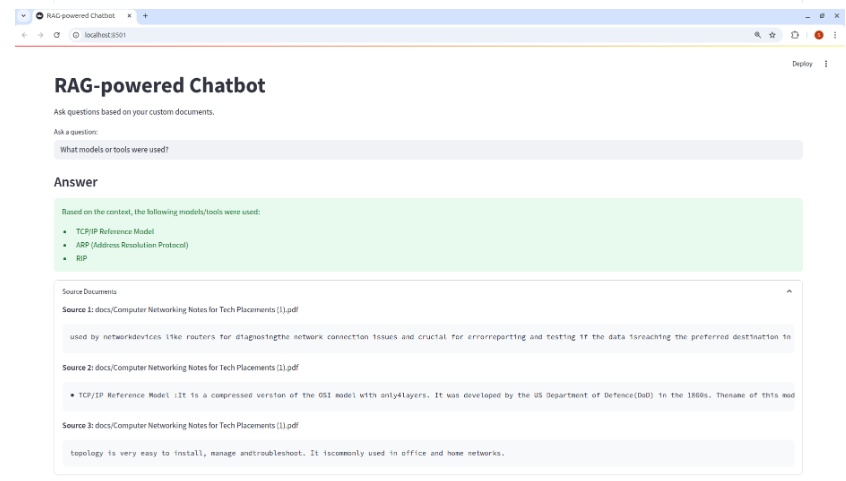
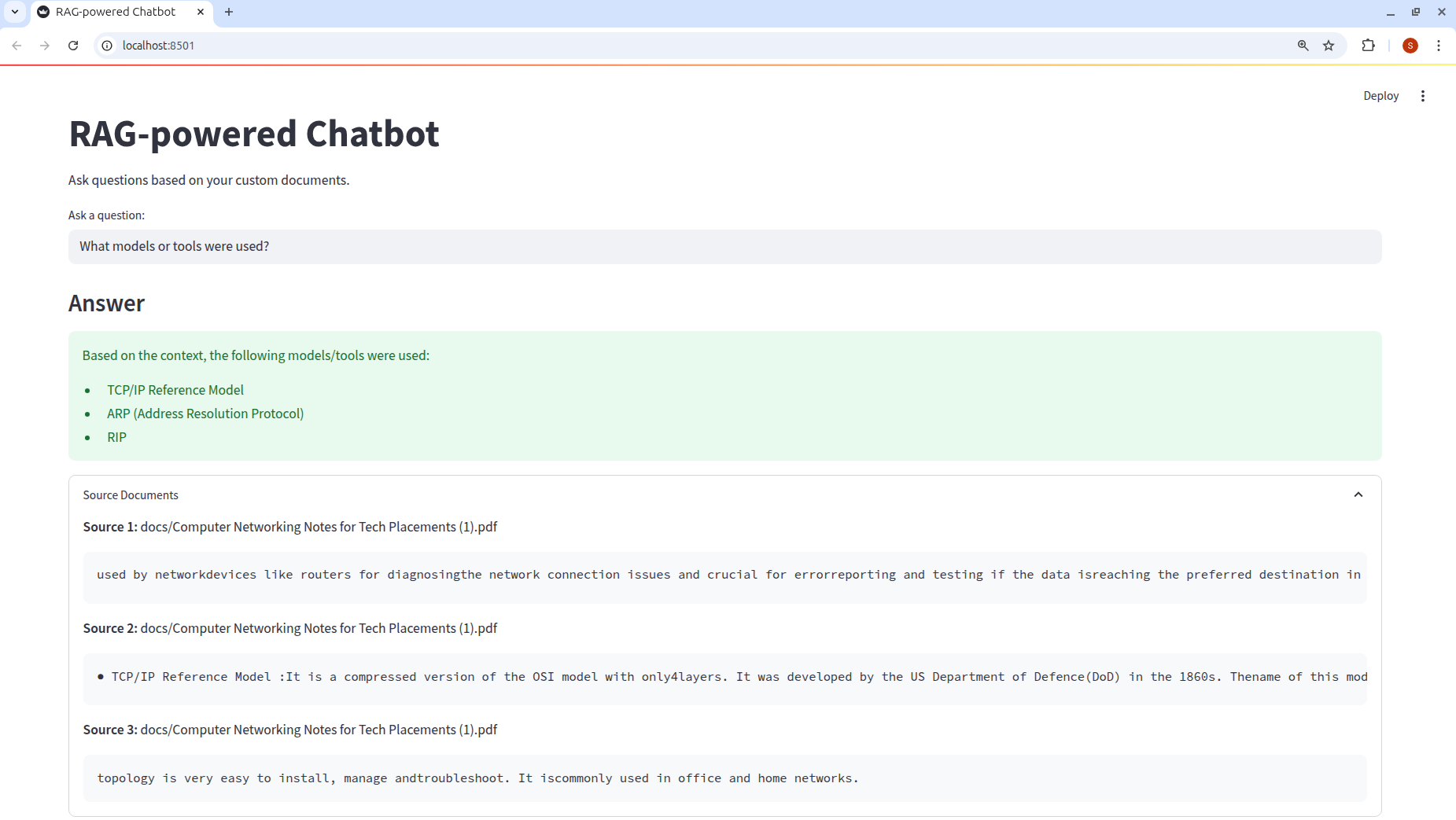
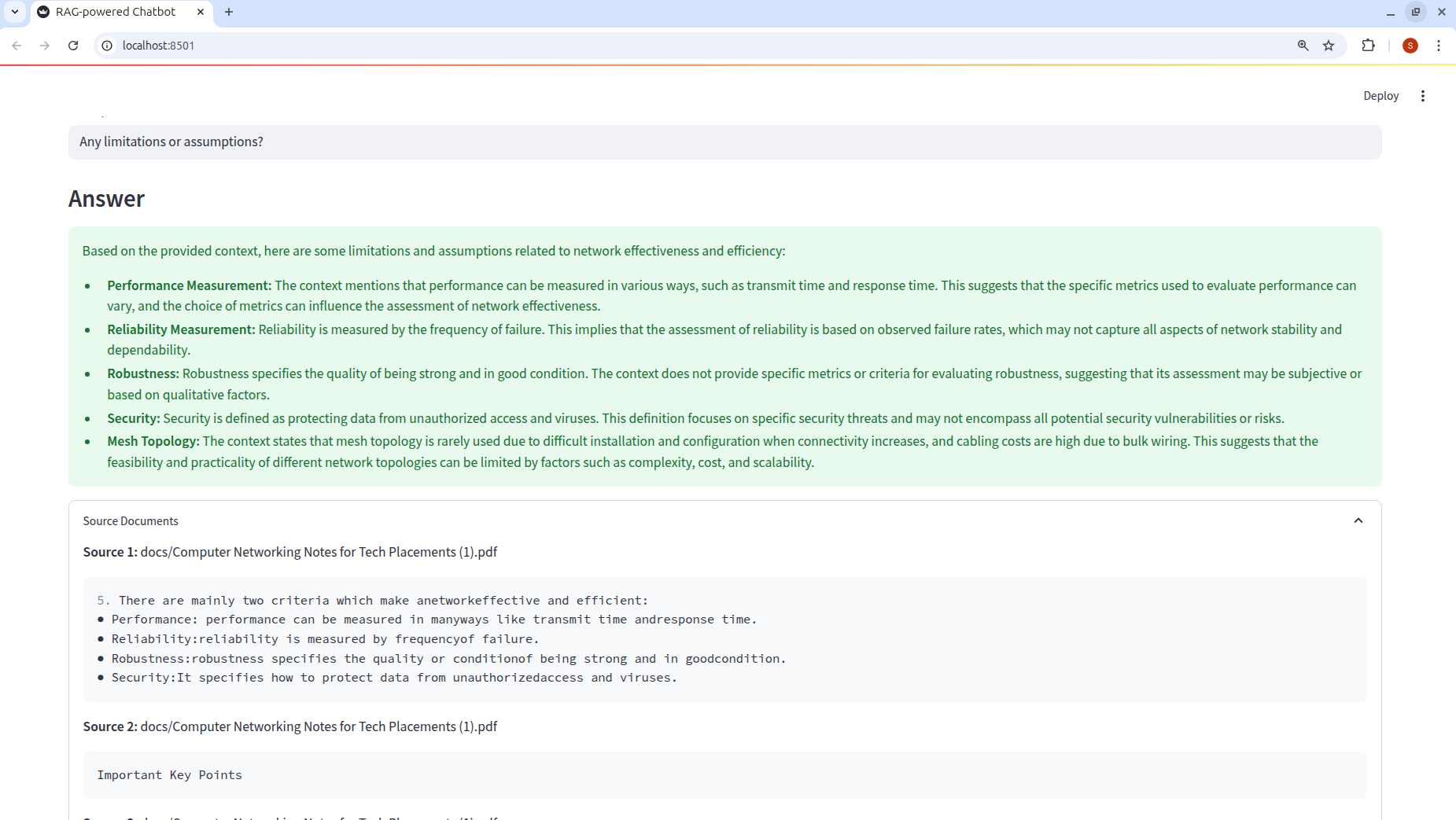
This chatbot is built on well-established libraries like LangChain and ChromaDB, both of which are supported by active developer communities. It also integrates seamlessly with tools such as OpenAI, HuggingFace, and various vector databases like FAISS. Each response is grounded in retrievable source documents, allowing users to verify the information and reducing the likelihood of hallucinations or misinformation.
Displays results in a user-friendly web app
This project is licensed under the Apache 2.0 License. The full license text is in the Apache License file in the repo.
We are interested in your opinion about this project!
If you have any suggestions or want to adapt the bot to your own tasks, please contact us.
