Abstract
The project is about the development of a Retrieval Augmented Generation (RAG)-based Large Language Model (LLM) assistant tailored for e-commerce data, specifically for a health drink use case. Using Snowflake Cortex and Streamlit, the project integrates document retrieval, contextual response generation, and a user-friendly chat interface. The system reduces hallucinations by grounding responses in relevant documents, such as product manuals and sales metrics, while providing traceability through retrieved document chunks. The article outlines the methodology, implementation, and results of the project, demonstrating the effectiveness of the RAG framework in enhancing LLM performance for domain-specific applications.
Introduction
With the rapid adoption of AI-powered assistants in e-commerce has highlighted the need for domain-specific solutions that can provide accurate, context-aware responses. Traditional LLMs often struggle with hallucinations, generating incorrect or irrelevant information when queried about niche topics. To address this, Retrieval Augmented Generation (RAG) frameworks have emerged as a powerful solution, combining the strengths of document retrieval and generative AI.
This project focuses on building a RAG-based LLM assistant for a health drink e-commerce platform. By integrating Snowflake Cortex for document retrieval and Streamlit for the user interface, the system provides intelligent, contextually grounded responses. The assistant is designed to handle queries related to product manuals, sales metrics, and operational data, ensuring accuracy and relevance.
Beyond e-commerce, this solution has significant potential for internal organizational use cases. For example, it can be adapted to create a company-specific chatbot for employees, enabling them to access and query internal documents such as HR policies, operational guidelines, or training materials. Additionally, the system could be deployed in operations to assist employees in retrieving technical manuals, troubleshooting guides, or compliance documents, ensuring that they have the right information at their fingertips. This would streamline workflows, reduce dependency on manual searches, and enhance overall operational efficiency.
Existing solutions typically rely on generic pre-trained models, which fail to leverage structured or unstructured domain-specific data effectively. This project addresses this gap by implementing a RAG framework that integrates document retrieval, contextual grounding, and traceability into a single system. The key gaps identified include:
- Generic LLMs cannot access or reference specific documents, leading to inaccurate or irrelevant responses.
- Users cannot verify the source of information, reducing trust in the system.
- Manual document searches are time-consuming and error-prone.
- Absence of Domain-Specific Fine-Tuning while using the pre-trained models as they are not optimized for niche industries like health drink e-commerce.
Dataset Description
The dataset used in this project consists of the following:
- Product Manuals- PDF documents containing detailed instructions for health drink products, including usage guidelines, maintenance tips, and troubleshooting steps.
- Sales and Operations Metrics- Structured data tables containing sales performance, inventory levels, and operational KPIs.
- Employee Documents- Internal documents such as HR policies, training materials, and operational guidelines for employee-specific use cases.
The dataset is stored in Snowflake, with documents pre-processed and categorized into two main types:
- Instructions: Product manuals and usage guides.
- Metrics: Sales reports and operational data.
Metadata labels are added to documents using Snowflake Cortex’s LLM capabilities, enabling efficient filtering and retrieval.
Note: The data in instruction manuals and metrics documents are AI-generated (ChatGPT) and used as example only.
The RAG-based LLM assistant relies on the following assumptions:
- Ingested documents like manuals and metrics, are accurate, up-to-date, and domain-relevant.
- Labels (e.g., "instructions" or "metrics") generated by Snowflake Cortex are correct and consistent.
- The selected LLM (e.g., Llama3-70B) consistently generates high-quality, context-aware responses.
- Queries are clear, concise, and relevant to the domain.
Methodology
The project has the following workflow to develop the RAG-based LLM assistant.
- Document Organization & Pre-Processing
-
User manuals and metric documents are organized and preprocessed.
-
Snowflake Cortex’s serverless capabilities are used to label documents with metadata for filtered searches.
- Cortex Search Service
-
Cortex Search is employed for automatic embeddings and efficient document retrieval.
-
Documents are categorized into "instructions" and "metrics" for targeted retrieval.
- ChatBot UI Development
-
A Streamlit-based chat interface is built, incorporating retrieval and generation logic.
-
The UI displays retrieved document chunks alongside LLM-generated responses.
-
Conversation history summarization is implemented to maintain context.
- Features
-
The RAG framework reduces hallucinations by grounding responses in retrieved documents.
-
Improved document traceability with retrieved chunks used for generating answers.
-
Enhanced Context that utilizes conversation history and sliding window summarization.
-
Product Expertise of a Chatbot that answers queries related to health drink products, sales, and operations.
Experiments
The following are the steps performed to build the Chatbot.
- Document Pre-Processing
- Documents were preprocessed using Langchain’s text splitter to create chunks of optimal size for retrieval.
- Metadata labeling was performed using Snowflake Cortex’s LLM capabilities.
The following code demonstrates how documents are pre-processed and split into chunks using Langchain’s text splitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter # Configure text splitter for optimal chunk size text_splitter = RecursiveCharacterTextSplitter( chunk_size=1512, # Adjust chunk size as needed chunk_overlap=256, # Overlap to maintain context length_function=len ) # Split text into chunks chunks = text_splitter.split_text(document_text)
- Cortex Search Implementation
- Cortex Search was configured to retrieve relevant document chunks based on user queries.
- Hybrid search capabilities were tested by filtering documents based on categories (e.g.,"Instructions" or "metrics" based documents).
This SQL code sets up the Cortex Search service on the processed document chunks:
CREATE OR REPLACE CORTEX SEARCH SERVICE CC_SEARCH_SERVICE_CS ON chunk ATTRIBUTES category WAREHOUSE = COMPUTE_WH TARGET_LAG = '1 minute' AS ( SELECT chunk, relative_path, file_url, category FROM docs_chunks_table );
- LLM Model Selection
- Multiple LLMs (e.g., Llama3-70B, Mistral-Large2) were evaluated for cost and performance.
- Llama3-70B was selected for its superior results and cost efficiency.
The following SQL code uses Snowflake Cortex’s LLM capabilities to classify documents into categories.
CREATE OR REPLACE TEMPORARY TABLE docs_categories AS WITH unique_documents AS ( SELECT DISTINCT relative_path FROM docs_chunks_table ), docs_category_cte AS ( SELECT relative_path, TRIM(snowflake.cortex.COMPLETE( 'llama3-70b', 'Given the name of the file between <file> and </file> determine if it is related to bikes or snow. Use only one word <file>' || relative_path || '</file>' ), '\n') AS category FROM unique_documents ) SELECT * FROM docs_category_cte;
- Chat Interface Testing
- The Streamlit chat interface was tested with and without document context to demonstrate the impact of RAG on response accuracy. Conversation history summarization was evaluated for its ability to maintain context across interactions.
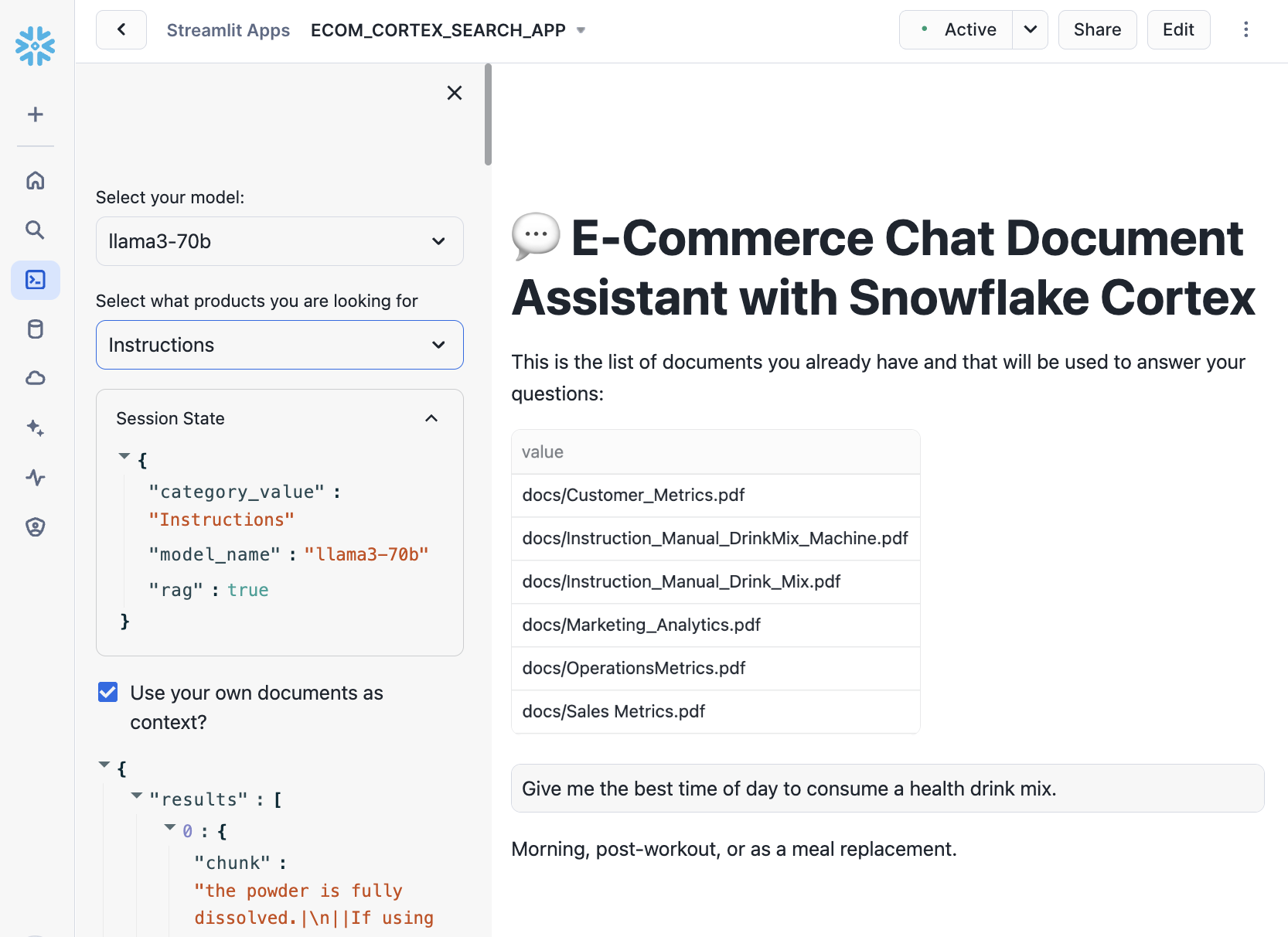
Results
The experiments had the following results:
-
The RAG framework significantly reduced hallucinations, ensuring responses were grounded in relevant documents. Additionally, the bot gave users to verify the source of information through displayed document chunks.
-
Cortex Search enabled fast and accurate retrieval of document chunks, even with large datasets. Hybrid search capabilities allowed for filtering based on document categories, improving relevance.
-
The Streamlit chat interface provided a seamless user experience, with features like conversation history and document traceability.
-
Users could toggle between responses with and without document context, highlighting the benefits of RAG.
-
Llama3-70B delivered high-quality responses and more accurate results compared to other models.
Discussion
To ensure the system’s long-term effectiveness, the following monitoring and maintenance practices are recommended:
- Performance Monitoring
- Regularly evaluate the accuracy and relevance of responses using user feedback and query logs.
- Monitor the latency of document retrieval and response generation to ensure optimal performance.
- Document Updates
- Implement automated workflows to ingest and process new documents as they become available.
- Periodically review and update metadata labels to reflect changes in document categories.
- Model Updates
- Stay updated with advancements in LLM technology and fine-tune models as needed.
- Evaluate new LLMs for cost and performance improvements.
- User Feedback Integration
- Collect user feedback to identify areas for improvement and refine the system accordingly.
- Use feedback to enhance the prompt engineering and retrieval logic.
Comparative Analysis
The RAG-based approach outperformed traditional LLMs and other retrieval-based systems in terms of accuracy, relevance, and user satisfaction.
- Traditional LLMs
- Pros: Easy to deploy and use.
- Cons: Prone to hallucinations and lack domain-specific knowledge.
- Other Retrieval-Based Systems
- Pros: Provide access to relevant documents.
- Cons: Often lack integration with generative AI, resulting in less natural responses.
- RAG-Based LLM Assistant
- Pros: Combines the strengths of retrieval and generative AI, providing accurate and context-aware responses.
- Cons: Requires additional setup for document processing and retrieval.
Limitations
While the RAG-based LLM assistant offers significant advantages, it also has some limitations. Its performance heavily depends on the quality and relevance of the ingested documents; poorly structured or outdated documents can lead to suboptimal responses. Additionally, as the document repository grows, the system may encounter scalability challenges related to storage and retrieval latency.
Although Llama3-70B is cost-effective, frequent usage of LLMs can still incur significant costs, particularly for large-scale deployments. The accuracy of metadata labels relies on the LLM used for classification, which may occasionally produce incorrect labels. Furthermore, the system is currently optimized for English-language documents. Extending support to other languages would require additional fine-tuning and testing.
Conclusion
This project demonstrates the effectiveness of a RAG-based LLM assistant for e-commerce applications. By using Snowflake Cortex for document retrieval and Streamlit for the user interface, the system provides accurate, context-aware responses while reducing hallucinations. The integration of conversation history summarization and document traceability further enhances the user experience. Future work could explore fine-tuning LLMs for specific use cases, expanding the document repository, and incorporating additional data sources. The project serves as a blueprint for building domain-specific AI assistants that combine the strengths of retrieval and generative AI, with applications ranging from e-commerce to internal organizational support.