
1. Introduction & Context
Healthcare is one of the most critical domains where accuracy and reliability of information are essential. Large Language Models (LLMs) have shown impressive capabilities in generating natural responses, but they often suffer from hallucinations and lack domain-specific grounding.
To address this, Retrieval-Augmented Generation (RAG) provides a practical solution by combining the reasoning ability of LLMs with verified medical or health-related documents. This ensures that users not only receive fluent answers but also answers supported by trusted references.
The goal of this project is to build a Health Q&A Chatbot powered by RAG that can answer user queries with high contextual accuracy while being transparent about its limitations.
2. Problem Statement
Patients and healthcare seekers often need immediate answers to health-related queries. Standard LLMs may generate convincing but unsafe outputs. For example, they may confuse similar symptoms or misinterpret abbreviations. The lack of grounding in reliable references makes them unsuitable for sensitive domains like health.
This project aims to solve this gap by retrieving verified knowledge chunks from trusted sources and using them to augment the chatbot’s responses.
3. Solution Overview
The chatbot uses a retrieval + generation approach:
- User submits a health-related query.
- Retriever searches a vector database of medical knowledge chunks.
- Top-k relevant documents are passed along with the query into an LLM.
- The LLM generates a response that is contextual, accurate, and better grounded.
This architecture improves both reliability and traceability compared to raw LLM outputs.
4. System Architecture
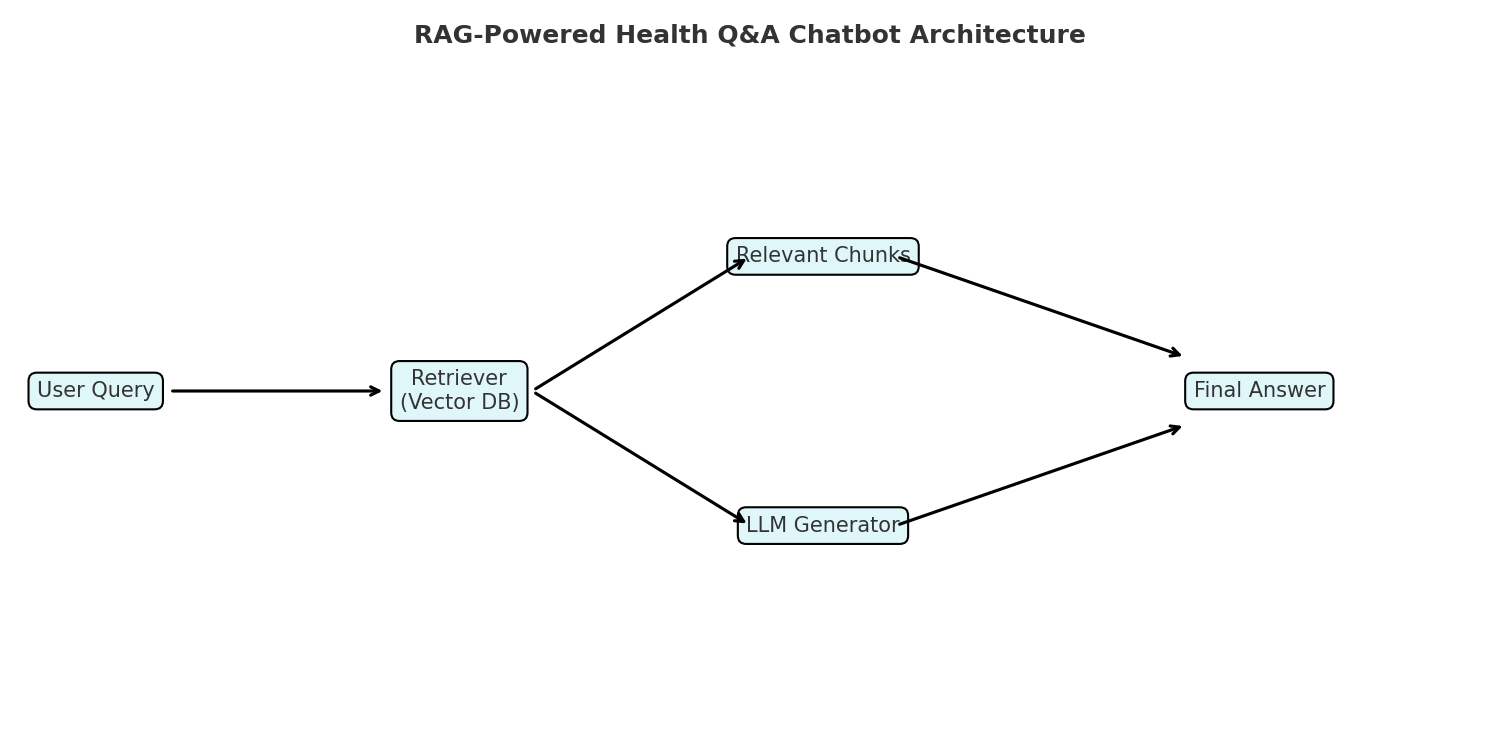
(User Query → Retriever (Vector DB) → Context Documents → Generator (LLM) → Final Answer)
The key components are:
- Vector Database (FAISS/Chroma): Stores embeddings of health knowledge documents.
- Embedding Model: Converts queries and documents into semantic vectors.
- Retriever: Finds the most relevant chunks.
- LLM Generator: Produces the final answer conditioned on retrieved chunks.
5. Chunking & Overlap Strategy
When preparing the knowledge base, raw documents are divided into smaller chunks to make retrieval effective. We used:
- Chunk size: 500 tokens
- Overlap: 50 tokens
This overlap ensures continuity across sentences or medical terms that may otherwise get split between chunks. It reduces the risk of losing important context and increases retrieval accuracy.
6. Query Processing Techniques
Before retrieval, queries undergo lightweight preprocessing:
- Normalization (lowercasing, whitespace cleanup).
- Optional keyword extraction for sharper search.
- Embedding generation for semantic similarity.
- Top-k retrieval with re-ranking to ensure the most relevant results are chosen.
This workflow ensures that even vague user queries map correctly to the right medical context.
7. Evaluation & Metrics
To evaluate the system:
- Retrieval Metrics: Recall@k and Precision@k were used to measure whether relevant documents were being retrieved.
- Qualitative Testing: A set of sample queries were run to check the accuracy of responses.
Initial results showed a marked improvement in context continuity and accuracy compared to a baseline non-overlap retriever.
8. Scope & Limitations
- Scope: This chatbot is designed for health-related queries where verified context is available.
- Limitations: It is not a substitute for professional medical advice and should not be used for emergency or prescriptive scenarios.
Clear disclaimers are provided to ensure safe usage.
9. Installation & Usage
To run this project:
- git clone <repo_url>
cd <repo_name>
pip install -r requirements.txt
Then start the chatbot: - python app.py
10. Future Work
- Expand to multi-domain healthcare support (nutrition, fitness, mental health).
- Experiment with hybrid retrieval techniques (BM25 + embeddings).
- Integrate with a UI framework like Streamlit or Gradio for broader accessibility.
- Add real-time feedback loop for continuous evaluation.
11. Conclusion
This project demonstrates how RAG can transform LLMs into safer, more reliable assistants for the healthcare domain. By carefully designing the chunking strategy, query processing pipeline, and evaluation metrics, we created a system that is both practical and portfolio-worthy.