
Abstract
RAG-Bot is an open-source project that implements a Retrieval-Augmented Generation (RAG) system with an interactive terminal interface. This project addresses the common challenge of LLM hallucinations by grounding responses in a knowledge base of documents. By combining the power of vector databases with modern language models, RAG-Bot enables accurate, contextual responses to natural language queries across multiple LLM providers including OpenAI, Ollama, Google, and Groq. This blog post details the implementation, architecture, and performance of the RAG-Bot system, demonstrating its effectiveness as a flexible and powerful tool for document-based question answering.
Methodology
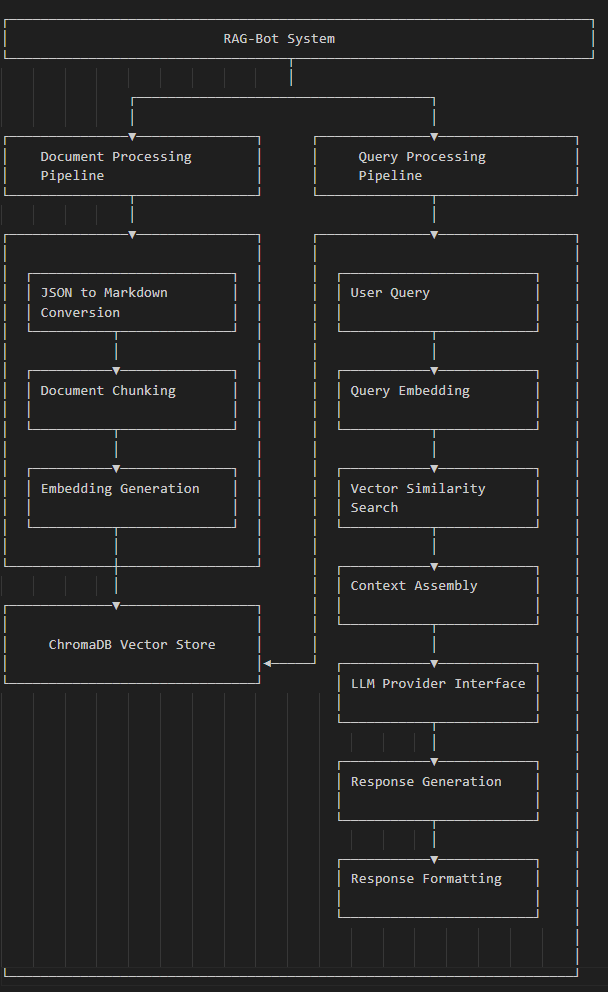
System Architecture
RAG-Bot follows a modular architecture with several key components:
- Document Processing Pipeline: Converts various document formats (starting with JSON) into markdown files that can be chunked and embedded.
- Vector Database Integration: Uses ChromaDB as the vector store for document embeddings, enabling semantic search capabilities.
- Embedding Generation: Implements sentence transformers via Huggingface embeddings(specifically all-MiniLM-L6-v2) to create high-quality document embeddings.
- LLM Provider Interface: Provides a unified interface to multiple LLM providers (OpenAI, Ollama, Google, Groq) with configurable parameters.
- RAG Query Engine: Combines document retrieval with LLM generation to produce contextually relevant answers.
- Interactive Terminal: Offers a user-friendly command-line interface for system interaction.
Implementation Details
The implementation uses Python with several key libraries:
- ChromaDB: For vector storage and retrieval
- LangChain: For RAG pipeline components
- Sentence Transformers(huggingface): For document embedding generation
- Various LLM APIs: For text generation capabilities
- ReadyTensor: For some code reference
The document ingestion process follows these steps:
- Convert JSON documents to markdown format (optional) provided the markdown files included in the data directory
- Split documents into chunks of appropriate size
- Generate embeddings for each chunk
- Store documents and embeddings in ChromaDB
The query process involves:
- Embedding the user query
- Retrieving relevant document chunks from ChromaDB
- Constructing a prompt with retrieved context
- Sending the prompt to the selected LLM
- Returning the generated response to the user
Challenges and Solutions
Several technical challenges were addressed during development:
- ChromaDB File Access Issues: Implemented a robust database manager with proper shutdown procedures and process management to prevent file access conflicts.
- LLM Provider Abstraction: Designed a flexible provider interface that allows easy switching between different LLM backends without changing the core application logic.
Installation
Prerequisites
- Python 3.9+
- Git
Setup
- Clone the repository
git clone https://github.com/yourusername/rag-bot.git cd rag-bot
- Create and activate a virtual environment
# Windows python -m venv .venv .\.venv\Scripts\Activate.ps1 # macOS/Linux python -m venv .venv source .venv/bin/activate
- Install dependencies
pip install -r requirements.txt
- Set up API keys
Create a .env file in the root directory with your API keys:
OPENAI_API_KEY=your_openai_api_key
GROQ_API_KEY=your_groq_api_key
GOOGLE_API_KEY=your_google_api_key
Usage
Running the Application
Navigate to the src directory and run the main script:
cd src python -m main
Interactive Commands
Once the application is running, you'll be presented with an interactive terminal:
-
Data Ingestion:
- Choose whether to convert JSON files to markdown
- The system will ingest documents into the vector database
-
LLM Provider Selection:
- Choose from OpenAI, Ollama, Google, or Groq
- Configure model parameters like temperature
-
Querying:
- Enter natural language questions to query your documents
- Type
configto change parameters - Type
exitto quit
JSON File Format for Conversion
The system can convert JSON files to markdown format. Place your JSON files in the source directory with the following structure:
[ { "id": "unique_identifier", "username": "author_name", "license": "license_type", "title": "Document Title", "publication_description": "The main content of your document. You can use --DIVIDER-- to separate sections." }, { "id": "another_identifier", "username": "another_author", "license": "license_type", "title": "Another Document Title", "publication_description": "Content of the second document." } ]
Required Fields:
id: A unique identifier for the documentusername: Author or creator namelicense: License type (e.g., "cc-by", "none")title: Document titlepublication_description: The main content of your document
Example:
[ { "id": "0CBAR8U8FakE", "username": "3rdson", "license": "none", "title": "How to Add Memory to RAG Applications and AI Agents", "publication_description": "# Introduction\n\nThis document explains how to add memory to RAG applications.\n--DIVIDER--\n## Implementation Details\n\nHere are the technical details..." } ]
When prompted during application startup, you can specify:
- The JSON file name (default:
project_1_publications.json) - The number of entries to process (default: 5)
Example Session
INFO: Welcome to the Interactive LLM Terminal!
INFO: Let us first ingest some data.
Do you want to convert a JSON file to markdown files? (y/n) [default: y]: n
INFO: Skipping JSON to markdown conversion.
INFO: Data ingestion completed.
INFO: Let us initialize the LLM.
INFO: Supported LLM Providers:
1. Openai
2. Ollama
3. Google
4. Groq
Choose provider [default: groq]: 4
INFO: Selected provider: groq
Enter model name for 'Groq' llm [default: llama-3.1-8b-instant]:
Enter temperature [default: 0.0]:
INFO: Success! Instantiated 'Groq' LLM with model 'llama-3.1-8b-instant' and temperature 0.0.
Enter a question, 'config' to change the parameters, or 'exit' to quit: what is uv?
INFO: Querying collection...
INFO: LLM response:
UV is a Python package installer and resolver that:
* Offers fast, reliable, and reproducible builds.
* Generates and updates a `uv.lock` file to capture the exact version of all installed dependencies.
* Minimizes the risk of "dependency hell" by maintaining consistent package versions.
* Speeds up installation since UV can use the locked versions instead of solving the dependencies again.
Choosing LLM
This projects provides provision to switch between multiple LLM provider with easy plugin and switch whenever required. It requires user to provide the LLM in which they want to work and enter the model name and other LLM parameters aligning their response.
It currently supports OpenAI. Gemini, Groq and Ollama providers and need to include others just edit the llm provider by adding the required one and start the application again.
Supported Providers and its interaction
INFO: Let us initialize the LLM.
INFO: Supported LLM Providers:
1. Openai
2. Ollama
3. Google
4. Groq
Choose provider [default: groq]: 4
INFO: Selected provider: groq
Enter model name for 'Groq' llm [default: llama-3.1-8b-instant]:
Enter temperature [default: 0.0]:
INFO: Success! Instantiated 'Groq' LLM with model 'llama-3.1-8b-instant' and temperature 0.0.
Results
User Experience
The interactive terminal interface provides several advantages:
- Ease of Use: Simple commands for configuration and querying
- Flexibility: On-the-fly switching between different LLM providers
- Transparency: Clear logging of each step in the RAG process
Future Work
Several enhancements are planned for future versions:
- Web Interface: Developing a browser-based UI for broader accessibility
- Additional Document Formats: Supporting PDF, HTML, and other formats directly
- Improved Context Handling: Implementing hierarchical retrieval for better handling of complex queries
- Memory Features: Adding conversation history to maintain context across multiple queries
- Evaluation Framework: Building automated testing to measure RAG performance across different domains
Conclusion
RAG-Bot demonstrates the power of combining vector databases with language models to create an effective document querying system. The project provides a solid foundation for building domain-specific assistants that can accurately answer questions based on a corpus of documents. By supporting multiple LLM providers and focusing on modularity, RAG-Bot offers flexibility for various use cases and deployment scenarios.
The open-source nature of this project invites collaboration and extension, potentially leading to more sophisticated RAG implementations in the future. As language models continue to evolve, the RAG approach will remain valuable for grounding responses in factual information and reducing hallucinations.