RAG_Assistant_for_Travel_Advisory is a Python-based Retrieval-Augmented Generation assistant that provides evidence-backed travel guidance. It combines semantic retrieval over curated travel documents with an LLM-based response generator to produce accurate, source-cited answers on visas, health advisories, regulations, and itineraries. The project includes ingestion, indexing, retrieval, generation modules, and evaluation tools for relevance and factuality. This RAG assistant is intended to aid travelers and travel advisors by delivering up-to-date, verifiable information while enabling further extension to additional domains and sources using
OpenWeather Map data.
This project addresses a common challenge in conversational AI for travel: providing up-to-date, verifiable, and context-aware answers while minimizing hallucinations.
The system integrates real-time environmental signals (for example, OpenWeatherMap for current weather conditions) with a Retrieval-Augmented Generation (RAG) pipeline that grounds responses in a curated knowledge base of travel documents (health advisories, local regulations, destination guides, transit alerts, and more). By combining live data and retrieved source passages, the assistant tailors travel suggestions to the user’s immediate context — e.g., recommending indoor itinerary alternatives, clothing and packing tips, transit adjustments, or health precautions when the weather indicates heavy rain, heatwaves, or poor air quality.
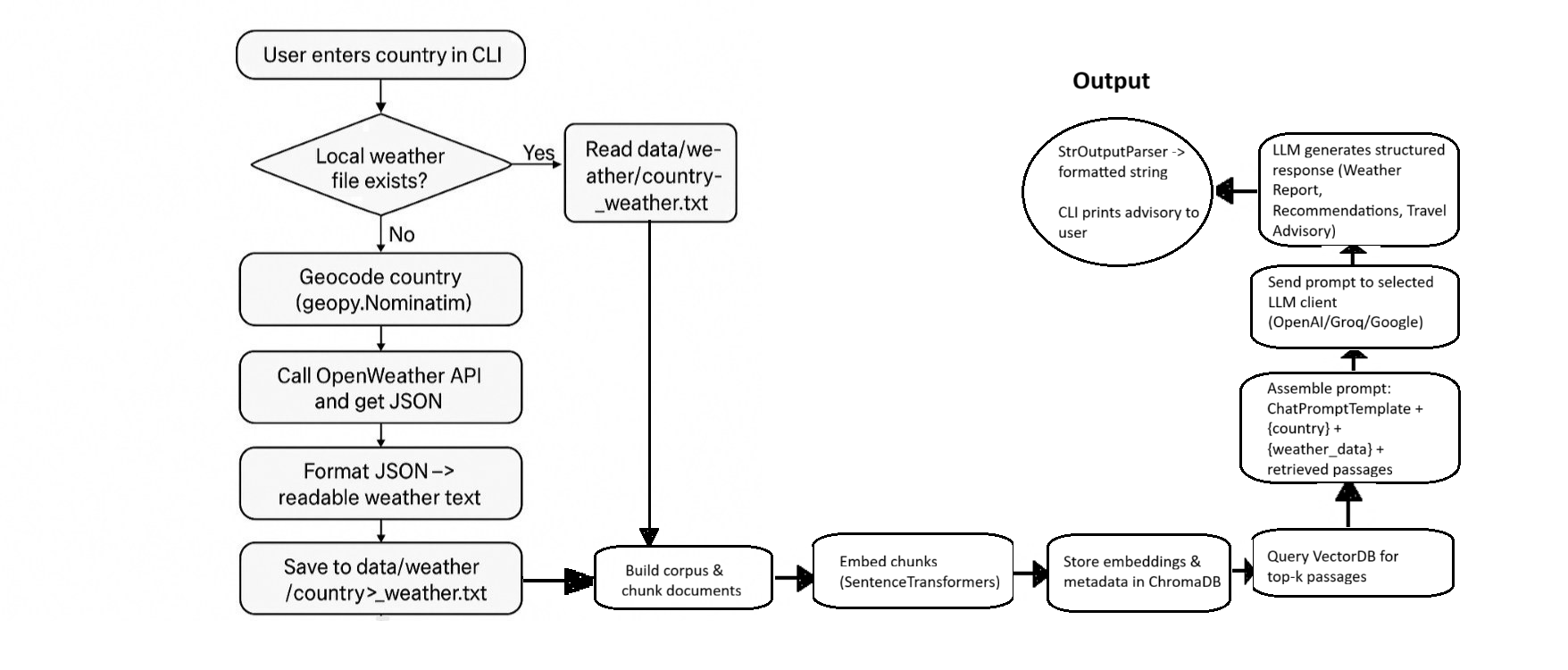
This project implements a weather-aware Retrieval-Augmented Generation (RAG) travel assistant: it gathers and indexes travel/weather documents, fetches live weather via OpenWeather, retrieves relevant context from a vector store, and uses an LLM (OpenAI / Groq / Google Gemini) with a structured prompt chain to produce evidence‑based travel recommendations.
RAG_Assistant_for_Travel_Advisory ├── src/vectordb.py Vector DB wrapper and embedding pipeline (ChromaDB + SentenceTransformers). ├── src/weather_app.py The RAG assistant orchestration: loads LLM, constructs prompt template/chain, invokes generation using both retrieved context and live/historical weather data. ├── src/weather_forecast.py Fetches and stores weather data for many countries using OpenWeather and geocoding; writes files under data/weather/. ├── requirements.txt project dependencies. Data ingestion and preparation (methods) ├── README.md Project documentation ├── chroma_db/ Persistent ChromaDB storage created by the VectorDB wrapper. │ └── ... ├── data/ │ ├── weather/ Persisted weather text files used as the local RAG corpus. └── .gitignore # Excludes .env, venv, etc.
Live-data integration and normalization (methods)
Multi-provider support: the assistant checks environment variables in order and initializes whichever API key is found first:
Initialization helper: RAGAssistant._initialize_llm encapsulates provider selection and client creation.
Structured prompt template: ChatPromptTemplate is used to create a fixed-format prompt that instructs the model to:
Analyze provided weather data for a specified country.
Provide Current Weather Conditions, Weather-based Recommendations, and Travel Advisory sections.
Base recommendations strictly on provided data and avoid adding unsupported assumptions.
Chain composition: the prompt template is combined with the LLM and an output parser (StrOutputParser) into a chain (prompt_template | llm | StrOutputParser) for invocation.
Determinism and safety: explicit instructions in the template and low temperature reduce hallucinations; retrieval constrains the model to context.
User enters a country name in the CLI (weather_app.py main loop).
The assistant obtains weather data for that country:
If live fetch is used: get_weather_data calls OpenWeather and may persist file.
If local data exists: reads the appropriate file from data/weather/.
Retrieval: the vector DB (via VectorDB) is queried for relevant passages related to the country and topic (weather/travel).
Prompt assembly: the retrieved context and the specific weather data for the country are injected into the prompt template.
LLM generation: the assembled prompt is passed to the selected LLM through the chain; the output parser formats the response.
The assistant returns a structured advisory including conditions, specific recommendations (e.g., indoor alternatives, packing advice), and travel advisories based on the weather.