This project presents the design and implementation of a Retrieval-Augmented Generation (RAG) Research Assistant that integrates Large Language Models (LLMs) with vector-based semantic retrieval to provide accurate, context-grounded responses to research queries. Unlike traditional question-answering systems that rely solely on pretrained model knowledge, the proposed assistant grounds its answers in user-provided documents. The system performs document ingestion, text chunking, embedding generation, and similarity-based retrieval to identify relevant information, which is then synthesized by a Large Language Model. By combining retrieval and generative reasoning, the solution enhances the research workflow by enabling efficient exploration, summarization, and querying of large collections of unstructured text.
Modern research involves navigating vast amounts of unstructured text, making it difficult to efficiently extract relevant information. While Large Language Models can generate high-quality responses, they often hallucinate information that is not grounded in real data. Retrieval-Augmented Generation (RAG) addresses this limitation by combining vector-based retrieval with generative models, ensuring factual accuracy through traceable sources.
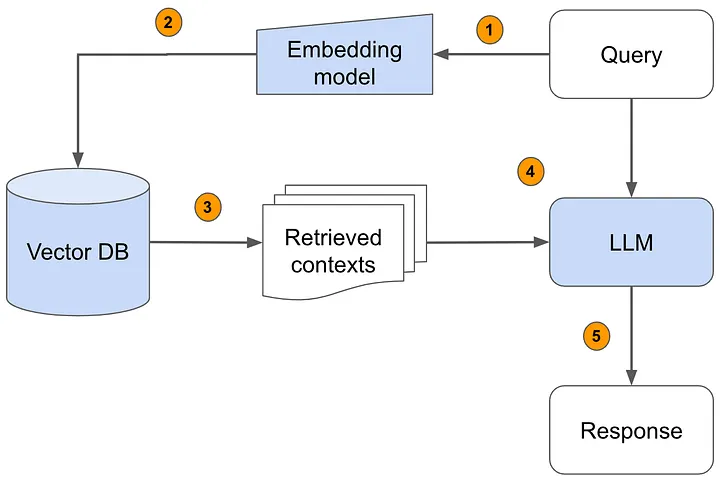
This project develops a specialized RAG-based Research Assistant capable of answering research questions using only the documents provided by the user. The system enables researchers to explore large text corpora, retrieve relevant evidence, and obtain synthesized explanations with source citations.
The overall system is composed of three major components:
answer, sources = answer_research_question( "Types of learning in AI", collection, embeddings_model, llm )
The system can be installed and run locally using the following steps:
git clone https://github.com/Achala-Elijah/Agentic_module_1.git
pip install -r requirements.txt
Add your knowledge base to the /documents folder
python main.py
The system successfully integrated document retrieval with LLM-based text generation, creating a research assistant capable of answering queries with supporting sources.
Types of learning in AI
Based on the research findings, there are three main types of learning in Artificial Intelligence (AI), specifically in the subfield of Machine Learning (ML):
Supervised Learning: In this type of learning, the model is trained on a labeled dataset, where each input example is associated with a desired output (label). The goal is to learn a mapping between inputs and outputs, enabling the model to make predictions on unseen examples. Common applications of supervised learning include spam detection, medical diagnosis, and predicting house prices. Algorithms used in supervised learning include Linear Regression, Logistic Regression, Support Vector Machines (SVM), Decision Trees, Random Forests, and Neural Networks.
Unsupervised Learning: This type of learning involves training a model on an unlabeled dataset, with the goal of discovering hidden patterns, structures, or groupings within the data. Unsupervised learning is used for tasks such as clustering (customer segmentation, document categorization) and dimensionality reduction (PCA, t-SNE). Algorithms used in unsupervised learning include K-Means, Hierarchical Clustering, Gaussian Mixture Models, and Autoencoders.
Reinforcement Learning: In reinforcement learning, a model learns to make a sequence of decisions by interacting with an environment. The model receives feedback in the form of rewards or penalties, which guides its learning process. Reinforcement learning is used in applications where an agent needs to learn to make decisions in a complex, dynamic environment.
These three types of learning form the foundation of Machine Learning, enabling machines to improve their performance on a given task through experience and data-driven decision making.
Types of Machine Learning
Supervised Learning
In supervised learning, the model is trained on a labeled dataset, meaning that for every input example, the desired output (label) is provided.
Example tasks: classification (spam detection, disease diagnosis) and regression (predicting house prices, forecasting stock values).
Algorithms: Linear Regression, Logistic Regression, Support Vector Machines (SVM), Decision Trees, Random Forests, Neural Networks.
Unsupervised Learning
Here, the dataset has no labels. The goal is to uncover hidden structures or groupings within the data.
Example tasks: clustering (customer segmentation, document categorization) and dimensionality reduction (PCA, t-SNE).
Algorithms: K-Means, Hierarchical Clustering, Gaussian Mixture Models, Autoencoders.
Reinforcement Learning
A model learns to make a sequence of decisions by interacting with an environment.
At its core, machine learning can be divided into three main categories: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning relies on labeled datasets where each input has a corresponding output. The system learns to map inputs to outputs, and after training, it can generalize to predict unseen examples. Common applications of supervised learning include spam email detection, medical diagnosis, and predicting house prices. Algorithms such as linear regression, logistic regression, support vector machines, and neural networks are widely used in this domain.
This project demonstrates the effectiveness of combining vector-based retrieval with generative AI to create a reliable, research-oriented assistant. By grounding responses in source documents and providing transparent citations, the system enhances research workflows and reduces the risk of hallucination. Future enhancements include implementing multi-turn memory, incorporating advanced retrieval evaluation metrics, and expanding visualization tools to provide deeper insights into retrieval quality and document structure.