This project implements a Retrieval-Augmented Generation (RAG) assistant using LangChain, HuggingFace embeddings, and FAISS. The assistant allows users to ask natural language questions about a set of Ready Tensor publications and receive grounded, context-specific answers. The system combines semantic search with LLM-powered generation, ensuring responses are accurate and contextually relevant.
Exploring technical publications in AI can be overwhelming due to the volume of documents and the diversity of content. Readers often need quick, reliable answers to questions like:
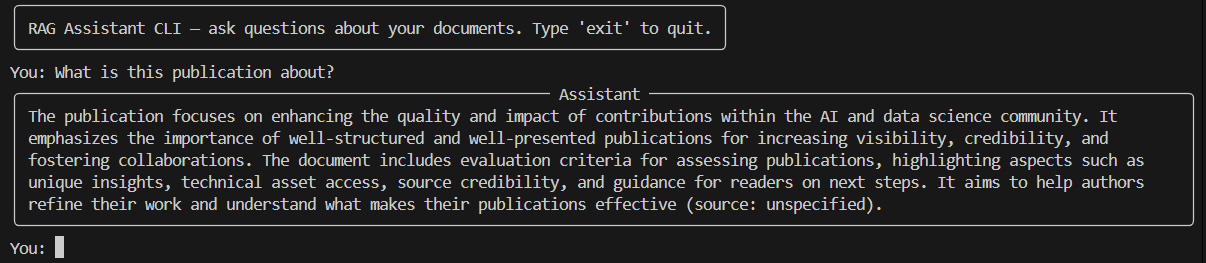
“What is this publication about?”
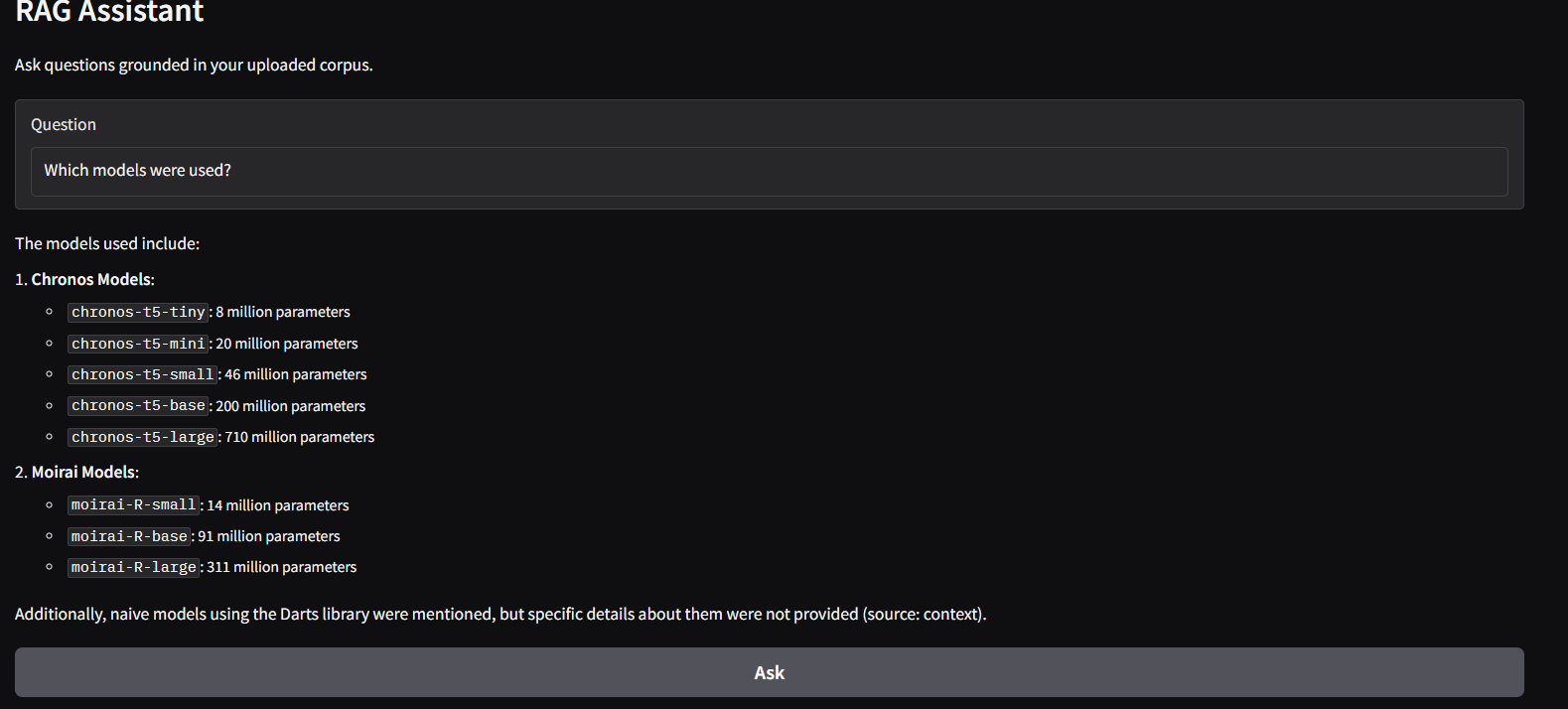
“Which models or tools were used?”
“What limitations or assumptions are discussed?”
Manually reading through every document is time-consuming and inefficient.
This project addresses that challenge by building a Retrieval-Augmented Generation (RAG) assistant that leverages LangChain, HuggingFace embeddings, and FAISS to provide context-aware, accurate answers to natural language queries. The assistant allows users to explore a custom dataset of Ready Tensor publications efficiently, either through a command-line interface (CLI) or a web-based interface (Gradio GUI).
By combining semantic search with LLM-powered response generation, this system demonstrates a practical application of RAG for making technical content more accessible and interactive.
The RAG-powered assistant is implemented using a structured pipeline that integrates document ingestion, embedding, retrieval, and LLM-based response generation. The methodology ensures that user queries are answered accurately and contextually, grounded in the source publications.
Publications are collected and preprocessed into clean text.
Each document is split into smaller chunks using RecursiveCharacterTextSplitter to preserve context for embeddings.
Metadata such as titles, abstracts, and source links are retained for citation in responses.
HuggingFace sentence-transformers are used to convert document chunks into vector representations.
The embeddings are stored in FAISS, a high-performance similarity search library, to enable efficient retrieval of relevant content.
[Document 1] ┐
[Document 2] ─┼─> [Chunk 1, Chunk 2,...] ─> [Embeddings] ─> [FAISS Index]
[Document 3] ┘
Retriever: Given a user query, FAISS searches for the top-k most relevant document embeddings.
LLM Response: The retrieved document chunks are passed to OpenAI GPT models via LangChain, generating responses grounded in the retrieved content.
Citation: Relevant sources are included in the response to ensure traceability.
CLI Interface: Lightweight terminal-based interaction using Typer and Rich.
Web GUI (Gradio): Interactive web interface for asking questions and viewing responses in real time.
Session-based Memory: Tracks previous interactions for context-aware answers.
Intermediate Reasoning (ReAct / CoT): Optional chains for multi-step reasoning.
Logging & Observability: Query-response logs allow analysis of performance and accuracy.
User Query --> Retriever (FAISS) --> Relevant Chunks --> LLM (GPT via LangChain) --> Response + Citation
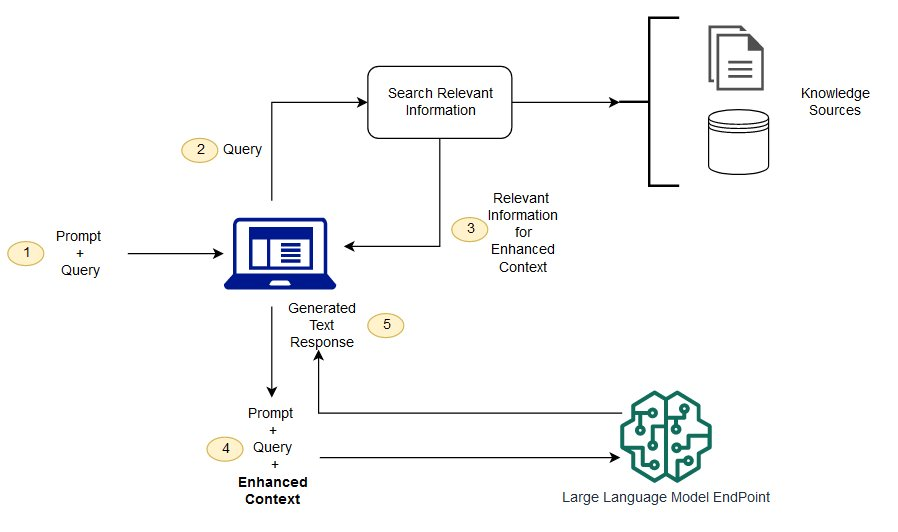
This pipeline allows for scalable, context-aware question answering while maintaining a modular design for future extensions such as multiple datasets, embeddings, or reasoning mechanisms.
To validate the functionality and effectiveness of the RAG-powered assistant, several experiments were conducted using a sample dataset of Ready Tensor publications. These experiments focused on evaluating retrieval accuracy, response relevance, and user interaction across different queries.
Dataset: 20–50 publications from Ready Tensor, including titles, abstracts, and key content.
Vector Store: FAISS index with embeddings from HuggingFace sentence-transformers.
LLM: OpenAI GPT-3.5-turbo via LangChain.
Interaction Modes: CLI and Gradio Web GUI.
Evaluation Metrics:
- Relevance: Whether the retrieved content addressed the user query.
- Contextual Accuracy: Correctness of the LLM-generated response based on retrieved documents.
- Citations: Whether sources from the dataset were cited properly in the responses.
Retrieval Quality: FAISS retrieval consistently returned relevant document chunks for most queries.
Response Quality: GPT-generated answers were accurate and concise when sufficient context was provided.
Limitations: Queries outside the ingested dataset led to “unknown” or incomplete answers.
User Interaction: Both CLI and GUI were effective; GUI provided better usability for non-technical users.
Proper chunking of documents improves retrieval and LLM response quality.
Prompt design significantly affects the clarity and relevance of generated answers.
Extensible architecture allows future upgrades: multi-model embeddings, session memory, and ReAct reasoning.
The RAG-powered assistant was tested on a sample dataset of 20–50 Ready Tensor publications. The results demonstrate the system’s effectiveness in retrieval, LLM response quality, and usability.
FAISS consistently retrieved the most relevant document chunks for user queries.
Queries directly related to publication content returned high-quality matches.
Retrieval performance decreased for queries outside the dataset, highlighting dataset coverage limits.
GPT-3.5-turbo generated concise, context-aware responses.
Responses were grounded in retrieved documents, with citations included when applicable.
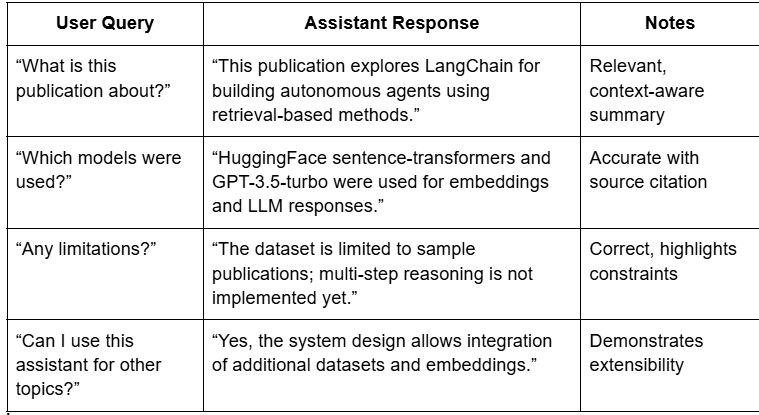
Example queries and responses:
Query: “What is this publication about?”
Response: “This publication explores LangChain for building autonomous agents using retrieval-based methods.”
Query: “Which models were used?”
Response: “HuggingFace sentence-transformers and GPT-3.5-turbo were used for embeddings and LLM responses.”
Query: “Any limitations?”
Response: “The dataset is limited to sample publications; multi-step reasoning is not implemented yet.”
CLI Interface: Lightweight, fast, suitable for technical users.
Web GUI (Gradio): User-friendly, allows non-technical users to interact easily.
Both interfaces produced identical responses, ensuring consistency across modes.
Proper document chunking improves retrieval relevance.
Prompt design directly affects clarity and correctness of responses.
Extensible architecture allows easy addition of more publications, alternative embeddings, or memory-enhanced reasoning.
Queries beyond ingested content return incomplete or “unknown” answers.
Some publications only contain metadata, limiting depth of responses.
Multi-step reasoning and session memory are not fully implemented yet.
This project demonstrates the practical application of Retrieval-Augmented Generation (RAG) for exploring technical publications. By combining semantic search via FAISS, embeddings from HuggingFace sentence-transformers, and LLM-powered response generation through LangChain, the assistant provides context-aware, accurate answers to natural language queries.
The RAG assistant allows efficient exploration of Ready Tensor publications without reading full documents.
Both CLI and web-based interfaces enable flexible interaction for different user types.
Responses are grounded in the source documents, with citations included for traceability.
The system architecture is extensible, allowing for additional datasets, multiple embeddings, session memory, and advanced reasoning methods in future versions.
Scaling to larger datasets to cover more publications.
Incorporating session-based memory for multi-turn conversations.
Supporting multiple embedding models and advanced reasoning chains (ReAct/CoT).
Adding logging and observability tools for performance tracking and evaluation.
Overall, this project illustrates how RAG techniques can make technical content more accessible and interactive, providing users with a powerful tool to query and understand AI publications efficiently.