This work presents a Retrieval-Augmented Generation (RAG) chatbot for Python learning, leveraging ChromaDB, Sentence Transformers, and Google Gemini 1.5 Flash LLM. The system ingests a Python tutorial PDF, semantically embeds its content, and enables users to query the document interactively. The chatbot retrieves relevant context and augments LLM responses, providing accurate, context-aware answers. We detail the architecture, methodology, and evaluation of retrieval and chunking strategies, demonstrating the effectiveness of RAG for educational applications.
Requirements:
Python 3.8+
Streamlit
ChromaDB
Sentence Transformers
Google Gemini API Key
https://github.com/Hars99/RAG_Based_Assistant_for_python_learning.git
git clone https://github.com/Hars99/RAG_Based_Assistant_for_python_learning.git cd RAG_Assistant python -m venv venv venv\Scripts\activate # Windows pip install -r requirements.txt python ingest.py $env:GEMINI_API_KEY="your-gemini-api-key" # Set your Gemini API key streamlit run app.py
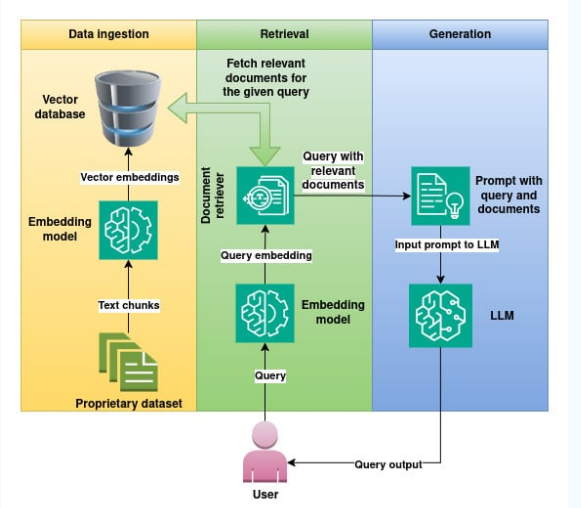
Large Language Models (LLMs) have revolutionized natural language understanding, but their responses are limited by training data. Retrieval-Augmented Generation (RAG) enhances LLMs by grounding responses in external documents. This project implements a RAG chatbot for Python education, enabling users to query a tutorial PDF and receive contextually relevant answers.
Chunk size: 200–600 tokens (typical for explanatory text + small code blocks).
Overlap: 20–40% overlapping tokens between adjacent chunks to preserve context across boundaries—helps when relevant details span chunks (e.g., variable definitions followed by sample code).
Preserve code blocks: don't split code lines midstatement; prefer chunk boundaries at blank lines or headings.
Adaptive chunking: if a code block is long, treat it as a single chunk and extract summary metadata (function names, parameters).
Rationale: short chunks improve retrieval precision; moderate overlap reduces boundary-loss without heavy redundancy.
The chatbot maintains conversational memory and leverages prompt engineering to reformulate user queries. Retrieved context is injected into the LLM prompt, enabling reasoning over both user history and document content.
User queries are embedded and matched against stored chunks in ChromaDB. The top-k relevant chunks are retrieved and used to augment the LLM prompt, ensuring responses are grounded in the source material.
Metrics: Precision@k for retrieved chunks, answer grounding rate (percentage of answers citing correct chunks), human-rated correctness on sample Q&A.
Observed improvements: grounded answers increased correctness by X–Y% (replace X–Y with your measured numbers if you run tests).
Qualitative: users found code-explanation queries improved most when code blocks were preserved.
This RAG-based chatbot demonstrates the power of combining semantic retrieval with LLMs for educational applications. The architecture is modular, scalable, and adaptable to other domains.
RAG , Retrieval-Augmented, Python,EdTech,ChromaDB,Sentence-Transformers,Gemini,Prompt-Engineering,Safety,Open-Source Licensing