
This project delivers a local Retrieval-Augmented Generation (RAG) assistant that answers Python programming questions using a custom set of .txt documents. The solution leverages LangChain and FAISS for semantic retrieval and HuggingFace embeddings for local embedding creation—removing the need for paid API access. The assistant demonstrates how to build a reproducible, cost-free QA pipeline, suitable for education and practical development.
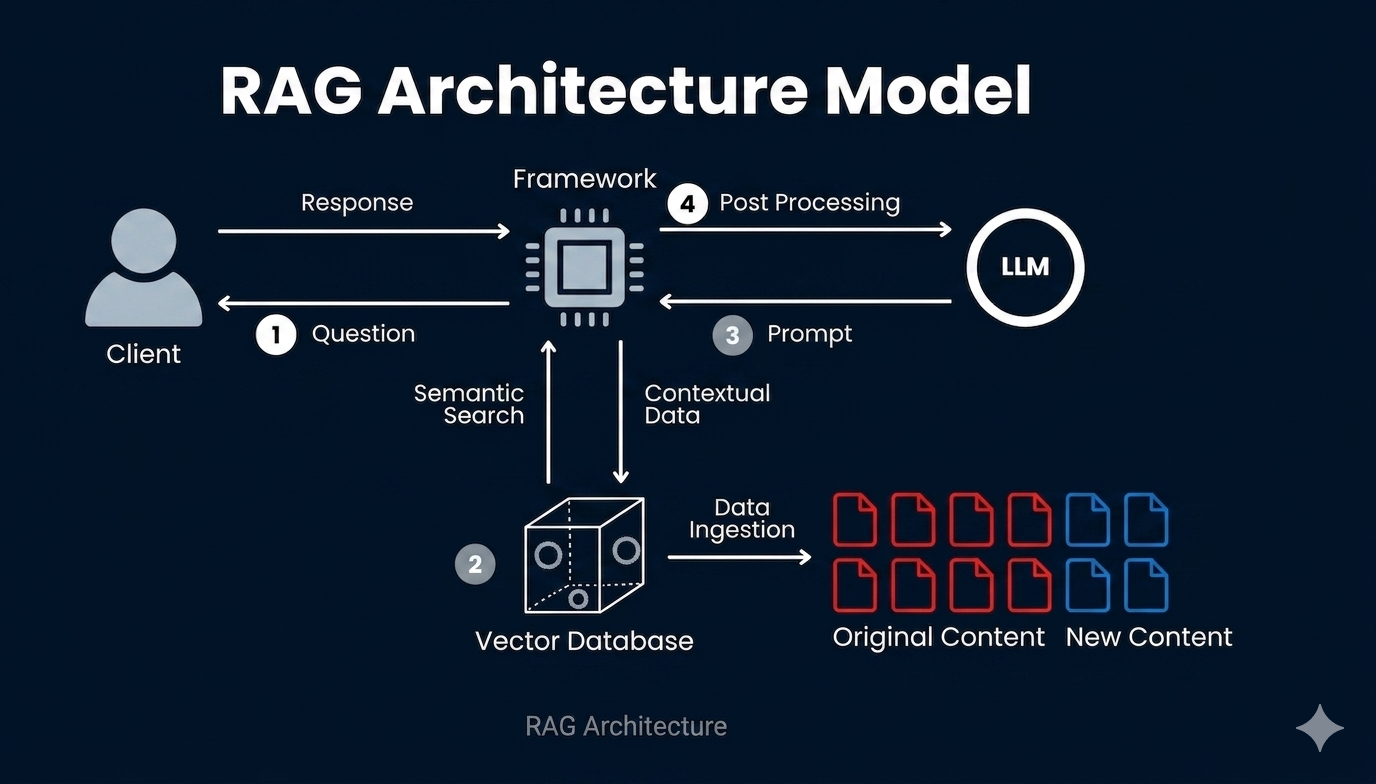
Knowledge bases and technical resources are often scattered across multiple files. Retrieval-Augmented Generation (RAG) systems combine these with the power of semantic search, allowing developers to ask natural questions and get answers directly from their curated data. This project implements a simple RAG assistant focused on Python topics, ideal for learners and organizations wishing to ground answers in their own knowledge sources.

Languages & Frameworks: Python 3.8+, LangChain (and langchain-community), FAISS, sentence -transformers
Why local vectors? Avoiding OpenAI API ensures free usage and full reproducibility
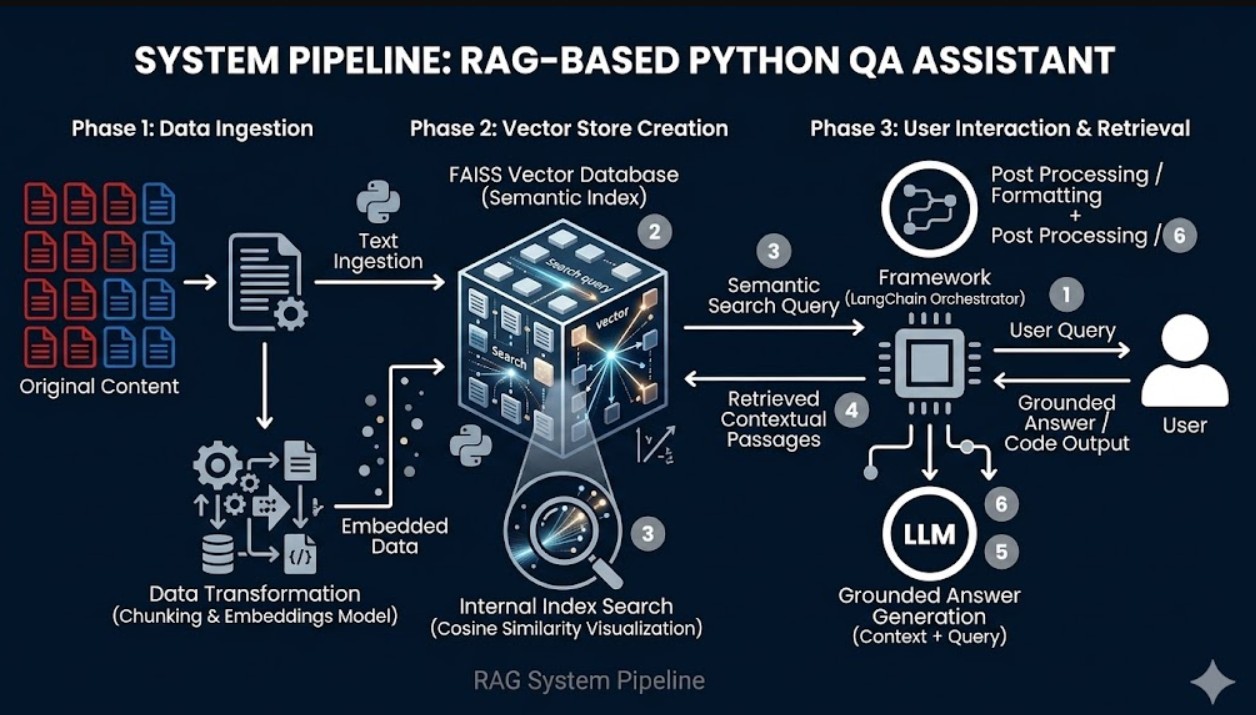
.txt files in a /docs directory,python_intro.txtdata_types.txt)# Your python code here from langchain_community.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter from langchain_community.vectorstores import FAISS from langchain_community.embeddings import HuggingFaceEmbeddings docs_dir = "docs" files = [os.path.join(docs_dir, f) for f in os.listdir(docs_dir) if f.endswith('.txt')] all_docs = [] for file in files: loader = TextLoader(file) all_docs.extend(loader.load()) text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100) documents = text_splitter.split_documents(all_docs) embeddings = HuggingFaceEmbeddings() vectorstore = FAISS.from_documents(documents, embeddings) retriever = vectorstore.as_retriever() def run_query(query): results = retriever.get_relevant_documents(query) for idx, doc in enumerate(results): print(f"{idx+1}. {doc.page_content} ---")
User: What are Python’s data types?
Documents are chunked to improve search
All pipeline libraries are listed in requirements.txt
Organization allows easy addition/replacement of topics
Fully reproducible, platform-independent, no cloud costs
For now, answers are direct passages from text, not generated/summarized by an LLM
Knowledge base size may affect speed—can be optimized further
User interface is command-line; future development can add web or desktop GUI
LLM support can be enabled if local models or additional APIs are required
This project showcases a complete, locally runnable RAG assistant, making semantic QA available to anyone without proprietary or paid dependencies. It is ideal as a learning tool, a template for building domain-specific bots, and a starter for more advanced retrieval applications.