This project presents a modular, Retrieval-Augmented Generation (RAG) assistant tailored for legal professionals. Built with LangChain, ChromaDB, and Groq, the assistant ingests custom legal documents and delivers citation-backed, context-aware responses. It supports multi-format ingestion, vector-based retrieval, and layered prompting to ensure precision and traceability. Designed for legal research, academic analysis, and courtroom-grade reliability, the assistant features a scalable Python architecture with session-level memory simulation and hallucination mitigation. Future enhancements include UI modularization, multilingual support, and jurisdiction-specific fine-tuning.
Legal professionals face increasing pressure to process vast volumes of case law, statutes, and legal commentary under tight deadlines. Traditional research methods—while thorough—can be time-consuming and cognitively demanding. The Legal Brief Companion addresses this challenge by combining Retrieval-Augmented Generation (RAG) with modular AI tooling to deliver fast, context-aware, and citation-backed answers grounded in custom legal documents.
Built with LangChain, ChromaDB, and Groq-hosted LLMs, the assistant ingests legal texts, semantically indexes them, and retrieves relevant passages in response to user queries. It then formulates structured prompts and generates responses using high-performance language models. The system is designed for transparency, reproducibility, and teachability—making it suitable for courtroom preparation, legal education, and collaborative research.
This document outlines the architecture, components, and deployment strategy of the Legal Brief Companion, with a focus on modular design, semantic retrieval, and prompt engineering best practices. It also highlights a real-world use case involving Tinker v. Des Moines, demonstrating the assistant’s ability to extract precedent, summarize arguments, and support legal reasoning.
Here's a visual breakdown of a typical Retrieval-Augmented Generation (RAG) architecture,
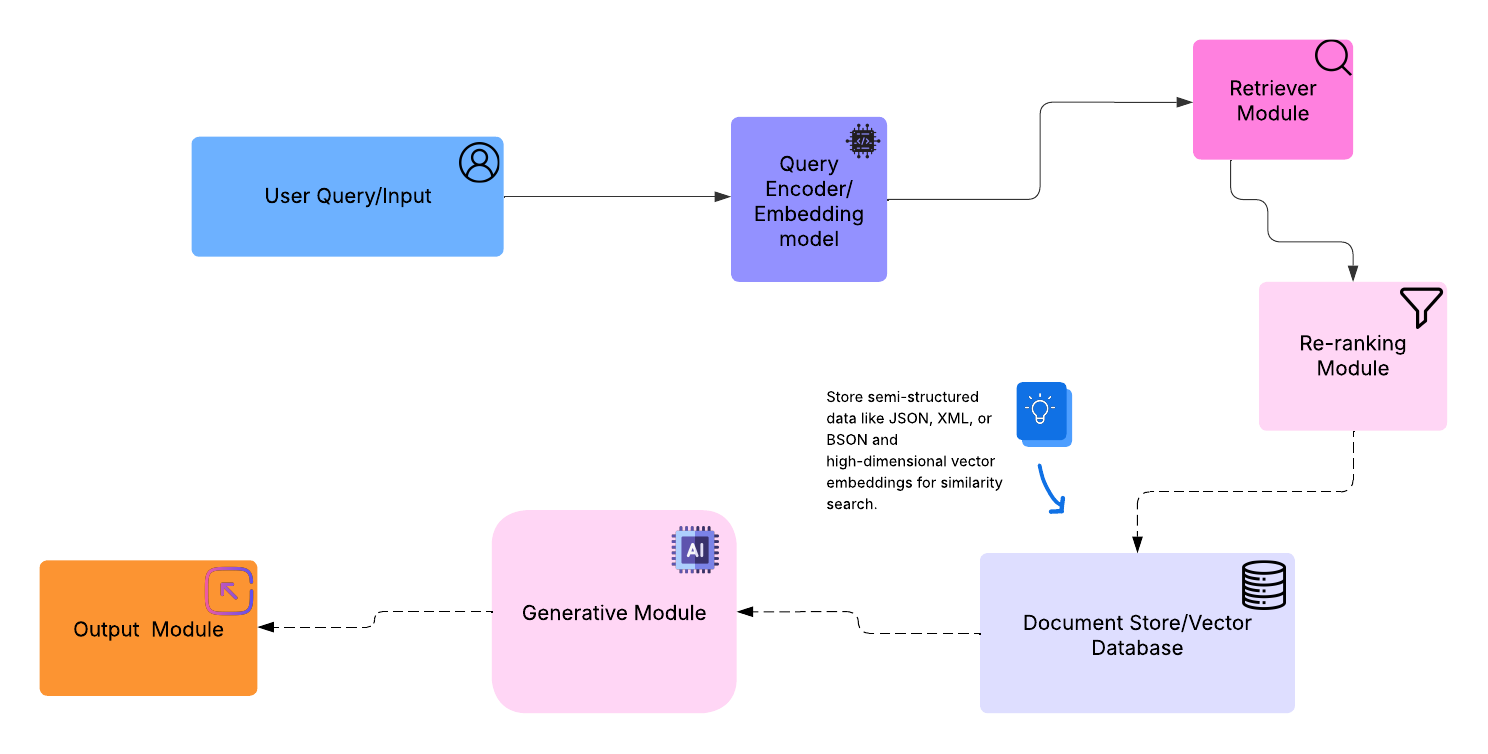
Legal Brief Companion supports ingestion of multiple document formats including .pdf, .docx, .txt, and .md. The ingestion pipeline is modular, transparent, and optimized for legal workflows.
Ingestion Workflow
Purpose: Convert legal documents into semantically structured plain text.
Supported Formats: .pdf, .docx, .txt, .md
Loaders Used:
- UnstructuredFileLoader (general)
- PyMuPDFLoader (PDFs)
- TextLoader (plain text)
Modular Tip: Swap in PDFMinerLoader for scanned rulings or OCR-heavy documents.
Purpose: Break text into manageable, semantically coherent chunks.
-Tool: RecursiveCharacterTextSplitter
-Defaults: 500 characters per chunk with 50-character overlap
-Why It Matters: Overlap ensures semantic continuity across chunk boundaries, improving retrieval accuracy.
Uses sentence-transformers/all-MiniLM-L6-v2 to convert chunks into dense vector representations.
Embeddings are cached and stored in ChromaDB for fast, persistent retrieval.
Purpose: Convert chunks into dense vector representations for semantic search.
-Model: sentence-transformers/all-MiniLM-L6-v2
-Storage: Embeddings cached and stored in ChromaDB
-Modular Tip: Swap embedding models based on domain specificity or multilingual needs.
Purpose: Enable traceability and citation toggling.
-Tags Added:
-Source filename
-Page number (if applicable)
-Timestamp
-Use Case: Supports courtroom-grade citation and audit trails.
Purpose: Store embeddings for reuse across sessions.
- Location: chroma_db/
- Features:
- Incremental ingestion
- Re-indexing without full reprocessing
- Modular Tip: Add ingestion logging for auditability in sensitive workflows.
{
"chunk_id": "doc_001_chunk_03",
"source": "case_law_ethiopia_2022.pdf",
"text": "The court held that...",
"embedding": [0.123, -0.456, ...],
"metadata": {
"page": 3,
"timestamp": "2025-10-21T09:00
Legal Brief Companion uses a layered prompting approach to ensure responses are accurate, grounded, and context-aware. This is especially important in legal workflows, where hallucinations can lead to misinformation or misinterpretation.
You are a legal assistant. Answer the following question using only the provided context.
If the context is insufficient, say so. Cite sources when possible.
Context:
[retrieved_chunks]
Question:
[user_query]
This structure discourages unsupported speculation and encourages citation-backed responses.
| Technique | Description |
|---|---|
| Context-only grounding | LLM is instructed to answer only from retrieved chunks. |
| Chunk relevance filtering | Top-k chunks are scored for semantic similarity before inclusion. |
| Citation toggles | Metadata (filename, page) is optionally surfaced in the response. |
| Fallback logic | Python, Streamlit(UI) |
| Model selection | Groq is preferred for deterministic, low-latency responses. Gemini fallback planned. |
Query: “What precedent did the court rely on?” Retrieved Context: Includes case summary from page 4 of case_law_ethiopia_2022.pdf Response: “The court relied on the precedent established in State v. Abebe, as noted on page 4 of the uploaded document.”
If no relevant precedent is found:
“The provided context does not include any cited precedent.”
Legal Brief Companion is designed to reason over domain-specific content with contextual precision. While it does not persist long-term memory across sessions, it uses session-level memory and retrieval-based reasoning to simulate continuity and support multi-turn interactions.
The assistant uses a retrieval-augmented reasoning loop that combines semantic search with prompt-based logic:
1.Query Embedding
Turn 1 “Summarize the ruling in case A.” → Retrieves ruling from page 3 of case_A.pdf → Generates summary.
Turn 2 “Did the court cite precedent?” → Uses cached context from Turn 1 + new retrieval → Responds with citation details.
Modularization Tips
Core Components
| Component | Tool used |
|---|---|
| Embeddings | sentence-transformers/all-miniLM-L6-V2 |
| Vector Database | ChromaDB |
| Language Model | Groq |
| Development | Python, Streamlit(UI) |
6.Generator: Combines the query and retrieved chunks.
Sends them to Groq to generate a coherent, fact-grounded response.
User Query: “Could you summarize this case?”
Response: A concise, context-aware summary grounded in the uploaded legal document.
Requirements:
Python 3.8+
Streamlit
ChromaDB
Sentence Transformers
Groq API Key
Legal Brief Companion demonstrates the power of modular design in building domain-specific AI assistants. By integrating Retrieval-Augmented Generation (RAG) with LangChain, ChromaDB, and Groq, the assistant delivers context-aware, citation-ready responses tailored to legal workflows. This project showcases:
A reproducible ingestion pipeline for multi-format legal documents
Vector-based retrieval for precision and traceability
Prompt engineering and hallucination mitigation for courtroom-grade reliability
Session-level memory and reasoning mechanisms for multi-turn interactions
UI modularization plans for user-driven document selection and citation toggling
For future reference, I’ll share updates and feedback requests in the
Build Share Connect – project-feedback channel as suggested. Thanks for the guidance — looking forward to engaging more there!
MIT License — free to use and modify and extended