
The project presents a Retrieval-Augmented Generation (RAG) chatbot specializing in U.S. history, developed as the part of Ready Tensor Agentic AI certification, Module1 project. The system combines Google's Gemini 2.5 Flash model with ChromaDB vector storage to deliver precise, source-backed answers to history queries. Our implementation features dynamic document ingestion, context-aware response generation, and conversation thread management through a Streamlit interface. The architecture prioritizes accuracy by retrieving relevant document chunks before generating responses, ensuring answers are grounded in provided source materials. This approach demonstrates how RAG systems can enhance information retrieval in specialized knowledge domains, offering a practical application of contemporary LLM technology for educational contexts.
The exponential growth in unstructured information demands increasingly sophisticated methods to extract and deliver knowledge efficiently. Our Retrieval-Augmented Generation (RAG) Chatbot represents a novel approach to specialized knowledge retrieval focused on U.S. history. This system addresses the limitations of traditional Large Language Models by grounding responses in verified source materials rather than relying solely on parametric knowledge.
This implementation integrates Google's Gemini 2.5 Flash model with ChromaDB vector storage and LangChain orchestration to create a context-aware conversational interface. We have used the book called "Outline of U.S. History" by Bureau of International Information Programs - U.S. Department of State, which is then processed, chunked, and embedded to form a searchable knowledge base. When queries are submitted, the system retrieves relevant document fragments before generating responses, ensuring factual accuracy while maintaining conversational fluency.
The architecture prioritizes user experience through a Streamlit interface with thread management capabilities, allowing for persistent, multi-session interactions. This work demonstrates how specialized RAG systems can enhance information access in educational environments by combining the strengths of retrieval-based and generative approaches to deliver historically accurate, source-backed responses.
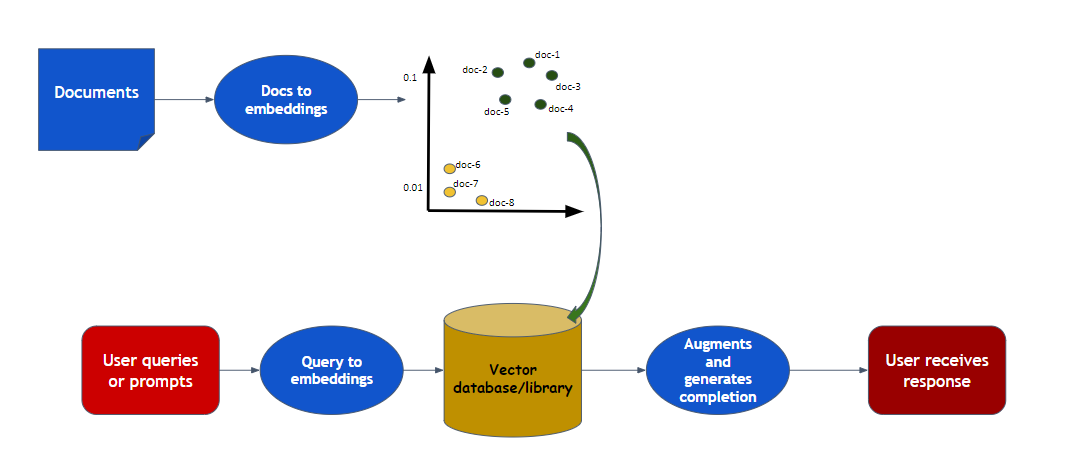
fig(i) RAG architecture followed in the project
The architecture of our RAG-based U.S. history chatbot involves a systematic process that contains a book as an knowledge base, advanced embedding techniques, and a powerful language model. First of all, the primary knowledge source, the book "Outline of U.S. History", is processed to generate vector embeddings using the Google Gemini 2.5 model, which is then combined with the text-embedding-004 technique. These embeddings are stored in a vector database called ChromaDB, enabling fast retrieval of relevant information.
When a user submits a question about U.S. history, the query is similarly converted into an embedding using the same text-embedding-004 model. This query embedding is then used to perform a similarity search within ChromaDB, retrieving the most relevant documents based on their relevance to the query. The retrieved documents, along with the user's question, are then sent to the Google Gemini 2.5 language model, which synthesizes the information and generates a comprehensive, accurate response.
Finally, this generated answer is presented to the user, ensuring they receive precise and contextually relevant information about U.S. history. This integrated approach effectively combines document retrieval and language understanding to enhance the quality and accuracy of the chatbot’s responses.
RAG_APP/
├── core/
│ ├── config.py
│ ├── generation.py
│ ├── prompt.py
│ ├── retrieval.py
│ └── services.py
├── processing/
│ ├── doc_processor.py
│ ├── embeddings.py
├── ui/
│ ├── app.py
│ ├── chat_histories/
│ └── uploads/
├── documents/
├── requirements.txt
└── README.MD
We have evaluated the final response with multiple set of question and here is what we got:
1. You: Who is tallest person on earth?
Bot: I am sorry, but the context provided does not contain information about the tallest person on Earth.
2. You: What happened in 9/11 attack?
Bot: On 9/11, four planes were hijacked. Two planes struck the twin towers of the World Trade Center in lower Manhattan. Another plane struck the Department headquarters just outside of Washington, D.C. The fourth plane, believed to be aimed at the U.S. Capitol, crashed in the Pennsylvania countryside as passengers fought the hijackers. The death toll was approximately 3,000, most of whom were civilians at the Trade Center. Several other buildings near the Trade Center were also destroyed, shutting down the financial markets for several days, prolonging the already developing recession
3. You: What is the role of USA on vietnam war?
Bot: According to the text, in 1965 a U.S. Army unit was searching for snipers while on patrol in South Vietnam. U.S. forces grew from 60,000 troops in 1965 to more than 540,000 by 1969. The last U.S. combat forces left Vietnam in 1973.
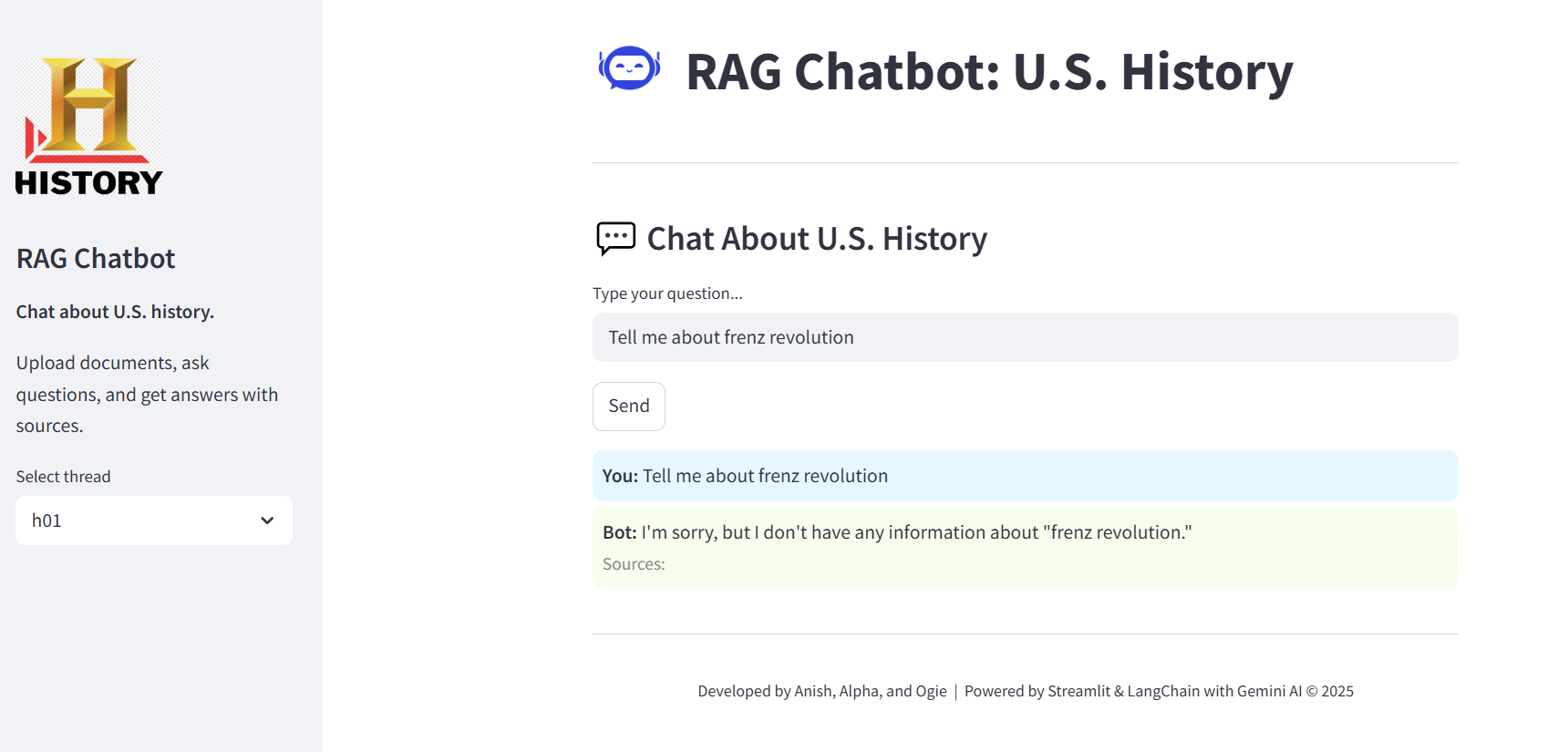
fig(ii) Final Application
We have attached the code repository along with the publication, You can feel free to test it.
This project lays a good foundation for a knowledge-grounded U.S. history chatbot, with several paths for further enhancement. Several avenues for future development can be pursued to enhance its capabilities, scalability, and educational impact:
Advanced Retrieval and Re-ranking Strategies
Future work can adopt multi-hop retrieval and re-ranking models to better handle complex questions that require connecting multiple sources, improving answer accuracy.
Multi-Modal and Visual Integration
Incorporating images, maps, and other multimedia content can make responses more engaging and help users better understand historical contexts.
Enhanced Context Management
Improving dialogue systems to retain longer conversation histories will allow for deeper, more coherent interactions and personalized learning experiences.
Real-Time Data Updates and Content Expansion
Linking the system to live databases and news sources will ensure that the knowledge base stays current with recent developments and discoveries.
Customization and Domain Adaptation
Allowing educators or users to customize retrieval settings or fine-tune the model will enable tailored experiences for different educational levels and topics.
Evaluation and User Feedback Integration
Regularly collecting user feedback and performance metrics will help identify strengths and areas for improvement to enhance the system's educational value.
Deployment and Accessibility
Expanding deployment options to mobile devices and supporting multiple languages will make the tool accessible to a broader, diverse audience.
This project successfully demonstrates the effectiveness of Retrieval-Augmented Generation (RAG) in enhancing domain-specific knowledge retrieval, particularly in the field of U.S. history. By integrating Google’s Gemini 2.5 Flash for response generation and ChromaDB for efficient document retrieval, we developed a chatbot that delivers accurate, contextually grounded answers while maintaining traceability to source materials.
Key achievements include:
Getting started with chroma db
https://docs.trychroma.com/docs/overview/architecture
Google Embedding
https://ai.google.dev/gemini-api/docs/embeddings
Knowledge base of U.S. history
https://time.com/wp-content/uploads/2015/01/history_outline.pdf
Medium Blog
https://medium.com/@himanshuit3036/day-2-understanding-core-components-of-rag-pipeline-71e4b8bf6466
Learn more about Streamlit
https://docs.streamlit.io/get-started/fundamentals

