RAG-Based AI Publication Agent: Enhancing Document Retrieval and Question Answering with Contextual Knowledge
This technical publication presents a Retrieval Augmented Generation (RAG) system designed to provide accurate, context-aware responses to queries by leveraging document-based knowledge. The system integrates document processing, vector embedding, and natural language generation to create an intelligent question-answering framework.
Our implementation processes text documents from a designated directory, segments them into semantic chunks, and creates vector embeddings using HuggingFace's sentence-transformers model. These embeddings are stored in a ChromaDB vector database, enabling efficient similarity search. When presented with a query, the system retrieves the most relevant document fragments and utilizes GROQ's language model to generate coherent, contextually appropriate responses.
This publication details the system architecture, implementation methodology, and functionality of this modular RAG solution, designed to enhance information retrieval from document collections while maintaining source attribution in generated responses.
The rapid advancement of large language models (LLMs) has transformed how we interact with information systems, enabling more natural and contextual interactions. However, these models face significant limitations when required to provide accurate responses based on specific document collections or knowledge domains. They may hallucinate information, fail to cite sources properly, or lack access to domain-specific knowledge.
Retrieval Augmented Generation (RAG) addresses these limitations by combining the generative capabilities of LLMs with information retrieval systems. RAG architectures enhance response accuracy by grounding LLM outputs in relevant document context, enabling systems to provide responses that are both accurate and attributable to source materials.
This publication presents our implementation of a RAG-based AI Publication Agent - a system designed to answer questions based on document collections through a multi-stage process:
- Document Processing Pipeline: The system ingests text documents from a specified directory, processes them through chunking algorithms to create semantically meaningful segments, and prepares them for embedding.
- Vector Representation and Storage: Document chunks are converted into dense vector embeddings using HuggingFace's sentence-transformers model and stored in ChromaDB - a vector database optimized for similarity search operations.
- Intelligent Query Processing: When presented with user questions, the system retrieves the most relevant document fragments through semantic similarity matching, providing contextual information to inform response generation.
- Context-Aware Response Generation: The retrieved document fragments and user query are passed to GROQ's language model, which generates coherent, contextualized responses that maintain fidelity to the source material.
Our implementation demonstrates a modular, extensible approach to RAG system architecture, with clearly defined components for document loading, text processing, vector storage, and response generation. This modularity facilitates system maintenance, extension, and adaptation to different document collections and knowledge domains.
In the following sections, we detail the system architecture and methodology, and key components that enable this contextually aware document question-answering system.
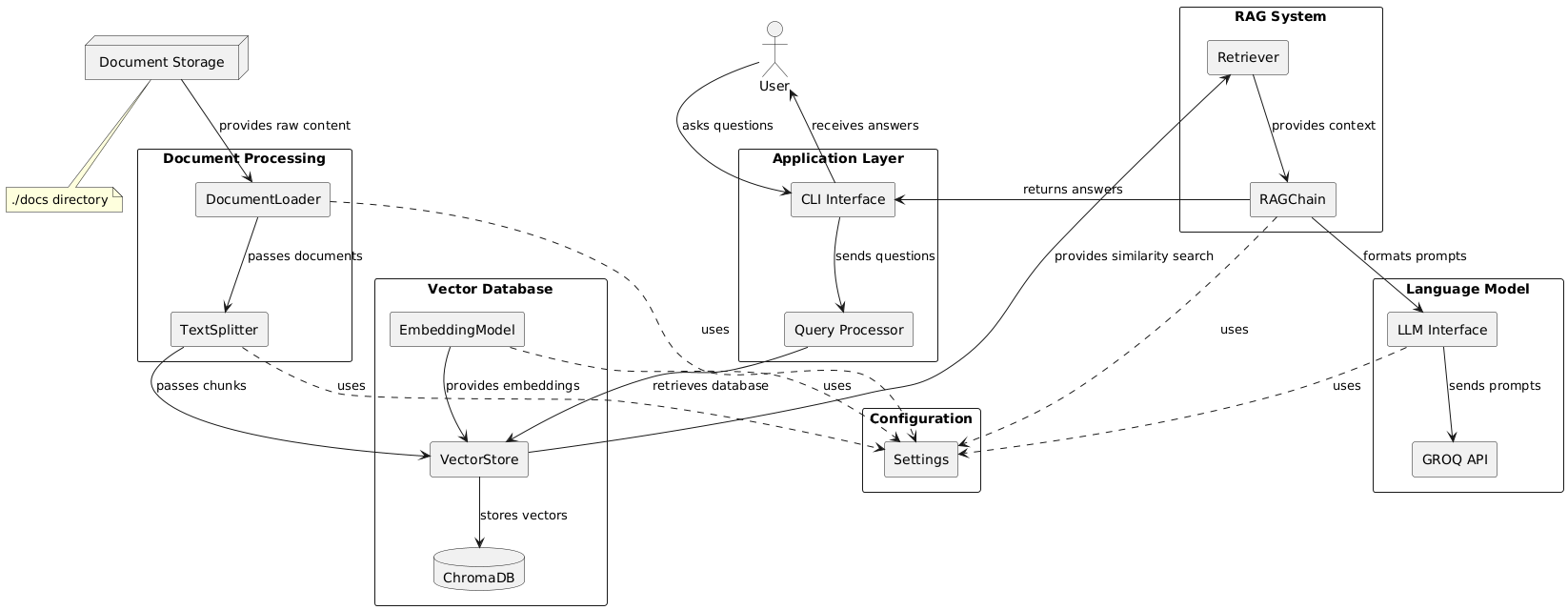
The RAG-based AI Publication Agent implements a modular architecture that separates concerns across document processing, vector representation, similarity search, and response generation. This design facilitates maintenance, testing, and future extensions while maintaining clear boundaries between functional components.
Link to Codebase: https://github.com/iyinusa/rag-ai-assistant
The document processing subsystem handles the ingestion and preparation of textual content:
- Document Loading: Implemented in
src.utils.document_loader, this component scans the configurable document directory (docs) for text files and loads them using LangChain'sDirectoryLoaderwithTextLoaderfor text encoding detection.
# Load the documents loader = DirectoryLoader( settings.DOCS_DIRECTORY, glob="**/*.txt", loader_cls=TextLoader, loader_kwargs={"autodetect_encoding": True} ) documents = loader.load()
- Document Chunking: After loading, documents are segmented into smaller chunks using
RecursiveCharacterTextSplitterwith configurable chunk size (default: 1000 characters) and overlap parameters (default: 200 characters). This chunking strategy preserves semantic coherence while creating appropriately sized segments for embedding.
text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, separators=["\n\n", "\n", " ", ""] )
The vector database subsystem manages document embeddings and similarity search operations:
- Embedding Generation: The
src.database.vector_storemodule utilizes HuggingFace's sentence transformers (specifically the "sentence-transformers/all-MiniLM-L6-v2" model) to convert text chunks into dense vector representations.
embeddings = HuggingFaceEmbeddings( model_name=settings.EMBEDDING_MODEL, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs )
- Vector Storage: ChromaDB serves as the persistent vector store, maintaining embeddings and their associated document metadata in the chroma_db directory. This component supports both the creation of new vector stores and the loading of existing ones.
# Create vector store db = Chroma.from_documents( documents=documents, embedding=embeddings, persist_directory=settings.CHROMA_PERSIST_DIRECTORY )
The query processing and response generation system combines information retrieval with language generation:
- LLM Integration: The
src.models.llmmodule interfaces with GROQ's API, configuring and initializing the language model (default: "llama-3.1-8b-instant").
# Initialize LLM llm = ChatGroq( api_key=settings.GROQ_API_KEY, model=settings.GROQ_MODEL )
- RAG Chain Assembly: In the RAG implementation, the system assembles the retrieval-augmented generation chain that connects vector similarity search with prompt formatting and language model generation.
# Create a retriever from the vector store retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={"k": 3} )
The src.config.settings module centralizes configuration parameters and prompt templates:
""" Configuration module for the RAG-based AI Publication Agent. """ import os from dotenv import load_dotenv # Load environment variables from .env file load_dotenv() # LLM Configuration GROQ_API_KEY = os.getenv("GROQ_API_KEY") GROQ_MODEL = "llama-3.1-8b-instant" # Default model # Vector Database Configuration CHROMA_PERSIST_DIRECTORY = "./chroma_db" # Embedding Model Configuration EMBEDDING_MODEL = "sentence-transformers/all-MiniLM-L6-v2" ...
- Environment Variables: Sensitive information like API keys is loaded from environment variables.
- System Prompts: Detailed prompting instructions guide the language model's behaviour, ensuring responses adhere to the information available in the document collection.
Initialization Phase:
- The system checks for an existing vector store
- If none exists, it loads documents from the configured directory
- Documents are split into semantic chunks
- Chunks are embedded and stored in ChromaDB
Query Phase:
- User submits a question through the CLI interface
- The system retrieves the vector database
- The question is embedded and used to perform similarity search
- Relevant document chunks are retrieved
- Retrieved context and question are formatted into a prompt
- The LLM generates a response based on the provided context
- The answer is returned to the user
The app.py file serves as the integration point, orchestrating the various components:
init_vector_db()handles the initialization workflowget_vector_db()manages vector database accessquery_agent()implements the query workflowrun_cli()provides the user interface
This architecture follows separation of concerns principles, with each module handling a specific aspect of the RAG workflow. The modular design allows for component replacement or enhancement without disrupting the overall system function, making the system adaptable to future improvements in embedding models, language models, or chunking strategies.
This publication has presented a comprehensive implementation of a Retrieval Augmented Generation (RAG) system designed to provide accurate, contextually relevant answers to questions based on document collections. Through our exploration of the system architecture, methodological approach, and component implementation, several key conclusions can be drawn.
The RAG-based AI Publication Agent successfully demonstrates:
- Effective Document-Grounded Responses: By combining vector-based retrieval with language model generation, the system produces responses that remain faithful to the source material, reducing the hallucination problems common in pure LLM approaches.
- Modular, Maintainable Architecture: The system's clear separation of concerns across document processing, vector representation, and response generation creates a flexible framework that can be extended and maintained with minimal coupling between components.
- Practical Implementation Balance: The chosen technologies, particularly the "all-MiniLM-L6-v2" embedding model and "llama-3.1-8b-instant" language model, establish an effective balance between performance, resource efficiency, and response quality.
- Intelligent Context Retrieval: The semantic search capabilities enabled by the vector database ensure that responses are informed by the most relevant document fragments, even when user queries don't exactly match document terminology.
Despite its strengths, the current implementation has several limitations worth noting:
- Document Format Restrictions: The system currently only processes plain text (
.txt) files, limiting its application for more complex document formats without additional preprocessing.
- Fixed Chunking Strategy: The recursive character splitting approach, while effective, uses static chunk size parameters that may not be optimal for all document types or query patterns.
- Limited Document Understanding: The system treats each document chunk as an independent unit, potentially missing cross-document relationships or broader context that spans multiple chunks.
Several promising directions for future development emerge from this implementation:
- Enhanced Document Processing: Expanding support for additional document formats (PDF, HTML, Markdown) would broaden the system's applicability across different knowledge domains.
- Dynamic Chunking Strategies: Implementing adaptive chunking that adjusts parameters based on document structure and content density could improve retrieval precision.
- Evaluation Framework: Developing comprehensive metrics for measuring response accuracy, relevance, and coherence would facilitate systematic improvement of the RAG pipeline.
- User Feedback Integration: Implementing a mechanism for collecting and incorporating user feedback on response quality could enable continuous improvement of the retrieval and generation components.
The RAG-based AI Publication Agent demonstrates how the integration of information retrieval with generative AI can create systems that leverage the strengths of both approaches. By grounding language model outputs in specific document collections, we enable more accurate, trustworthy AI assistants that can effectively serve as knowledge interfaces to organizational documentation.
As large language models continue to evolve, RAG architectures like the one presented in this publication will play an increasingly important role in bridging the gap between generative capabilities and factual accuracy. The modular design principles and implementation patterns showcased in this system provide a foundation for future developments in document-grounded question answering systems.
- Ready Tensor Certification. (2025). Agentic AI Developer Certification Program, AAIDC2025. Retrieved June 2025, from https://app.readytensor.ai/hubs/ready_tensor_certifications.
- LangChain. (2025). LangChain Framework Documentation. Retrieved June 2025, from https://langchain.com/docs.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Retrieved from https://www.sbert.net.
- GROQ. (2025). GROQ API Documentation. Retrieved June 2025, from https://groq.com/docs.
- Chroma. (2025). ChromaDB: An AI-native open-source embedding database. GitHub. Retrieved June 2025, from https://github.com/chroma-core/chroma.
- Hugging Face. (2025). Sentence Transformers Documentation. Retrieved June 2025, from https://huggingface.co/sentence-transformers.
