
Author: Joram Kirubi
Repository: github.com/joramkirubi/RAG-AI-assistant
Type: Capstone Project — Software Development
Large Language Models (LLMs) have demonstrated remarkable capability in natural language understanding, yet their utility in healthcare is constrained by a fixed training knowledge cutoff and a tendency to generate plausible-sounding but factually incorrect responses — a critical risk in medical contexts. This paper presents MedAssist, a domain-specific Retrieval-Augmented Generation (RAG) AI assistant designed to answer health and medical questions accurately by grounding every response in verified source documents.
The system integrates a persistent vector database (ChromaDB), locally-executed dense retrieval embeddings (HuggingFace sentence-transformers), and a high-throughput hosted LLM (Groq API, LLaMA 3.1) within a LangChain orchestration pipeline. A ReAct reasoning strategy guides the model's internal reasoning process before generating each response. Conversation history support enables natural follow-up questions within a session. An interactive chat interface with real-time retrieval metrics is delivered via Streamlit.
Empirical testing demonstrates that the RAG architecture significantly improves factual grounding and response relevance compared to a standalone generative model, while eliminating hallucinated responses that contradict source documents. The system operates entirely on commodity CPU hardware without GPU requirements.
Keywords: Retrieval-Augmented Generation, Healthcare AI, Large Language Models, Vector Databases, Semantic Search, ChromaDB, LangChain, ReAct Reasoning, Medical Question Answering, Groq
The application of Large Language Models to healthcare presents both significant opportunity and substantial risk. While models such as LLaMA 3 and GPT-4 demonstrate strong general-purpose reasoning, their knowledge is frozen at training time and they are prone to generating confident but incorrect clinical information — a phenomenon that can have serious consequences in medical contexts.
Retrieval-Augmented Generation (RAG), introduced by Lewis et al. (2020), addresses this by fetching relevant passages from an external document corpus at inference time and injecting them into the model's context window before generation. This converts a closed-book system into an open-book one, grounding responses in verifiable source material.
MedAssist applies this architecture specifically to the healthcare domain. The system allows users to query curated medical documents — including clinical guidelines, drug references, and the WHO World Health Statistics 2025 — using natural language, and receive accurate, source-attributed answers guided by a structured reasoning strategy.
The RAG paradigm was formalised by Lewis et al. (2020) using dense passage retrieval to index Wikipedia and retrieve passages at query time for a BART-based generator. The approach has since been adapted to instruction-tuned LLMs in zero-shot settings — the setup adopted in MedAssist — where retrieved context is injected into a structured prompt and the model is explicitly instructed to answer only from that context.
Dense retrieval encodes both queries and documents into a shared embedding space so that semantically similar texts map to nearby vectors. This project uses the all-MiniLM-L6-v2 sentence transformer, which produces 384-dimensional embeddings and runs efficiently on CPU — making it well-suited to single-machine healthcare deployments where data privacy is a concern.
ChromaDB is an open-source AI-native vector store offering persistent local SQLite-backed storage with native LangChain integration. Unlike managed cloud vector stores, ChromaDB requires no external server, keeping all document data on the user's machine — an important consideration for sensitive medical documents.
LangChain provides composable abstractions for the full RAG pipeline. This project uses LangChain Expression Language (LCEL) to compose the retrieval and generation stages into a single runnable pipeline, with clean separation between the ingestion pipeline (ingest.py) and the query pipeline (rag_chain.py).

MedAssist is structured as two decoupled pipelines: an offline ingestion pipeline that processes and indexes source documents, and an online query pipeline that retrieves relevant context and generates answers at request time.
Add your architecture diagram screenshot here
| Module | File | Responsibility |
|---|---|---|
| Document Loader | ingest.py | Reads .txt, .json, .pdf files from data/ |
| Text Splitter | ingest.py | RecursiveCharacterTextSplitter — 600 char chunks, 80 overlap |
| Embedding Model | vectordb.py | HuggingFace all-MiniLM-L6-v2 — 384-dim vectors, CPU |
| Vector Store | vectordb.py | ChromaDB — persistent SQLite-backed local vector store |
| Retriever | vectordb.py | Cosine similarity search returning top-5 chunks |
| RAG Chain | rag_chain.py | ReAct prompt + conversation history + Groq LLM |
| LLM | rag_chain.py | Groq API — llama-3.1-8b-instant, temperature 0.2 |
| Interface | app.py | Streamlit chat UI with metrics sidebar |
.txt, .json, and .pdf files are loaded from data/. PDFs are processed page by page using PyPDFLoader preserving page metadata.chunk_size=600 and chunk_overlap=80, preserving semantic context at boundaries.vectorstore/.The MedAssist prompt is structured around six components: Role, Goal, Tone and Style, ReAct Reasoning Strategy, Output Constraints, and Retrieved Context. The explicit refusal instruction ensures the model declines rather than fabricates when information is absent from the corpus — critical in a medical context.
MedAssist maintains conversational context by passing the last 3 exchanges (6 messages) into every prompt. This enables natural follow-up questions within a session:
The history is formatted as a structured block injected into the prompt before the retrieved context. A sliding window of 3 exchanges was chosen to balance context richness against prompt token limits.
Current limitation: History resets on page refresh. Persistent cross-session memory using a summary buffer or vector-stored conversation history is a planned improvement.
ReAct (Reason + Act) was selected over Chain-of-Thought and Self-Ask for the following reasons:
| Strategy | Strengths | Why Not Used |
|---|---|---|
| Chain-of-Thought | Strong multi-step reasoning | Ignores retrieval context; uses parametric memory |
| Self-Ask | Good for multi-hop question decomposition | Overkill for single-document QA |
| ReAct | Designed for retrieval + reasoning tasks | Selected — maps directly to RAG |
The model follows four internal steps before writing any answer:
These steps are internal — the user sees only the final answer, not the reasoning trace. This produces more accurate, contextually aware medical responses compared to a direct generation approach.
| Layer | Technology | Version | Rationale |
|---|---|---|---|
| Language | Python | 3.11+ | Strong ML/NLP ecosystem |
| Orchestration | LangChain | 0.2.16 | Composable RAG abstractions; LCEL syntax |
| LLM API | Groq (LLaMA 3.1) | llama-3.1-8b-instant | Sub-second latency via custom LPU hardware |
| Embeddings | sentence-transformers | 3.0.1 | Local CPU inference; no embedding API cost |
| Vector Store | ChromaDB | 0.5.5 | Zero-infrastructure persistent local vector store |
| PDF Loader | pypdf | 4.3.1 | Page-by-page PDF ingestion with metadata |
| Interface | Streamlit | 1.37.1 | Built-in chat components; rapid prototyping |
| Secret Management | python-dotenv | 1.0.1 | .env file loading; prevents API key exposure |
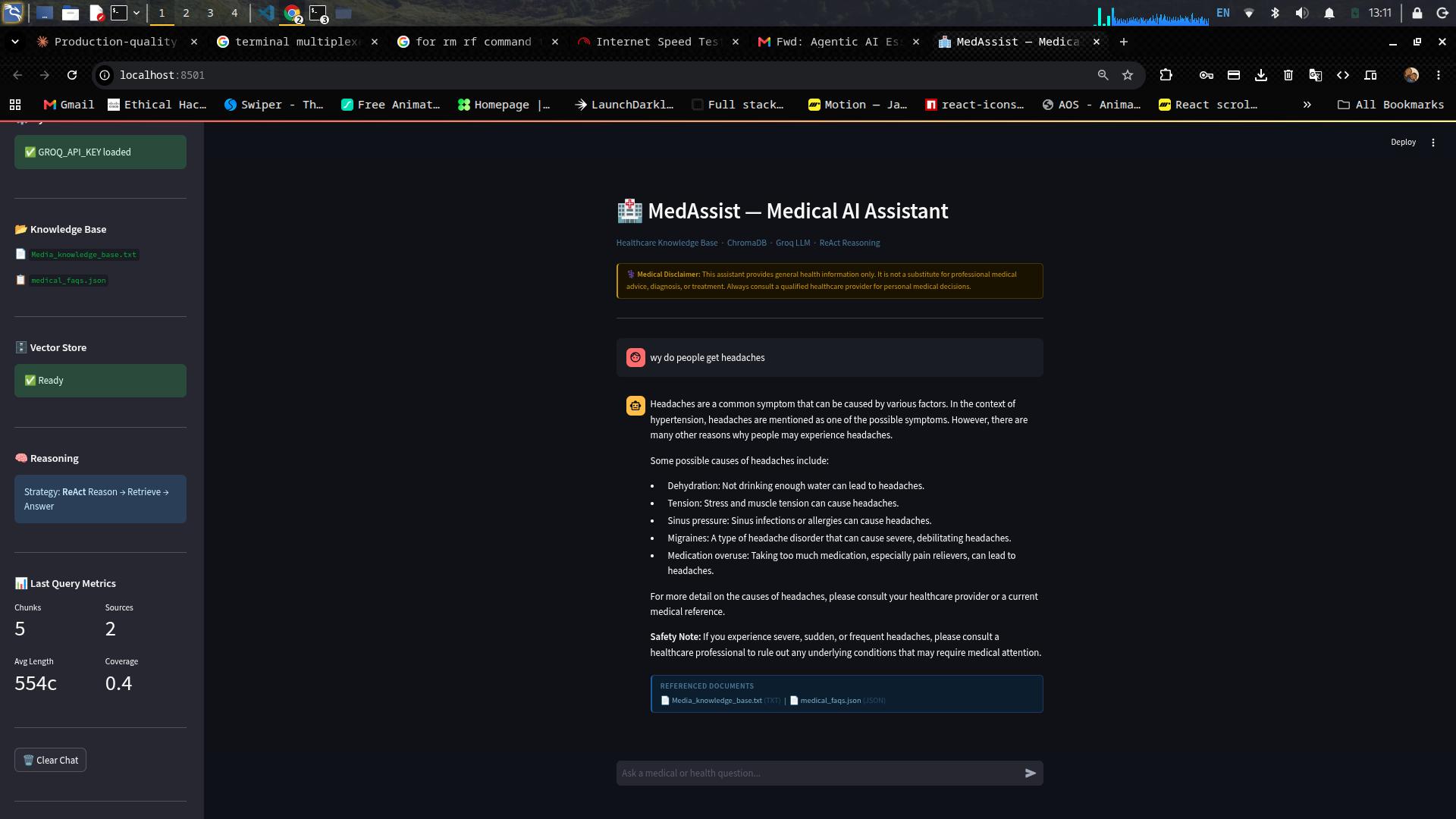
The system was tested against a curated healthcare corpus:
The sidebar displays live retrieval metrics after each query:
| Metric | Description |
|---|---|
| Chunks | Number of document chunks retrieved |
| Sources | Number of unique source files used |
| Avg Length | Average character length of retrieved chunks |
| Coverage | Ratio of unique sources to chunks (higher = less redundancy) |
| Query | Behaviour | Outcome |
|---|---|---|
| What are the symptoms of diabetes? | Retrieved 5 chunks covering Type 1 and Type 2 symptoms | Complete, accurate answer |
| What is a normal resting heart rate? | Retrieved FAQ and knowledge base chunks | Correct answer with context |
| What is the capital of France? | No relevant chunks — refusal instruction triggered | Correct refusal |
| What medications treat hypertension? | Retrieved antihypertensive drug class descriptions | Accurate multi-drug answer |
This paper presented MedAssist — a domain-specific healthcare AI assistant built on a complete Retrieval-Augmented Generation pipeline. The system integrates ChromaDB, HuggingFace sentence-transformers, LangChain, Groq LLaMA 3.1, and Streamlit into a fully functional medical question answering system with conversation memory, source attribution, and real-time retrieval metrics.
The ReAct reasoning strategy and structured medical prompt ensure responses are grounded, accurate, and appropriately cautious — never fabricating drug names, dosages, or clinical guidelines absent from the source corpus. The system correctly declines out-of-scope questions rather than hallucinating, which is the core safety guarantee of the RAG architecture in a medical context.
The system operates on commodity CPU hardware, requires no cloud infrastructure beyond a Groq API key, and can be extended to new medical document corpora without model retraining.