This project presents a production-ready Retrieval-Augmented Generation (RAG) system that addresses fundamental limitations of large language models by grounding responses in custom document collections. By combining vector-based semantic search with multiple state-of-the-art language models, the system delivers accurate, explainable, and conversational answers to user queries. The implementation demonstrates practical solutions for document ingestion, semantic chunking, multi-provider LLM integration, and conversation memory, establishing a foundation for enterprise knowledge management and agentic AI applications.
Retrieval-Augmented Generation (RAG) enhances AI assistant capabilities by combining neural language models with context sourced from external knowledge bases. Our project addresses the limitations of “pure” LLMs by enabling responses grounded in uploaded documents (TXT, PDF, etc.), facilitating explainable answers and better multi-turn conversations. The project leverages modular design so it can be extended with memory, tool use, or reasoning workflows.
Large language models (LLMs) like GPT-4, Llama, and Gemini possess impressive general knowledge but face critical limitations in real-world applications:
Knowledge Cutoff Problem: LLMs have fixed training data ending dates (e.g., GPT-4's knowledge cuts off in April 2024). Users need access to current, proprietary, or domain-specific information not available in the model's training data.
Proprietary Information Gap: Organizations cannot share confidential documents with external LLM APIs for fine-tuning, yet need accurate answers based on internal policies, procedures, research, and knowledge bases.
Lack of Explainability: When an LLM generates an answer, users cannot verify its source or accuracy against their actual documents. This is critical in compliance-heavy industries like legal, healthcare, and finance.
Context Window Limitations: Even with extended context windows (100K tokens), manually inserting all relevant documents into every prompt is inefficient and costly.
Retrieval-Augmented Generation combines three core components:
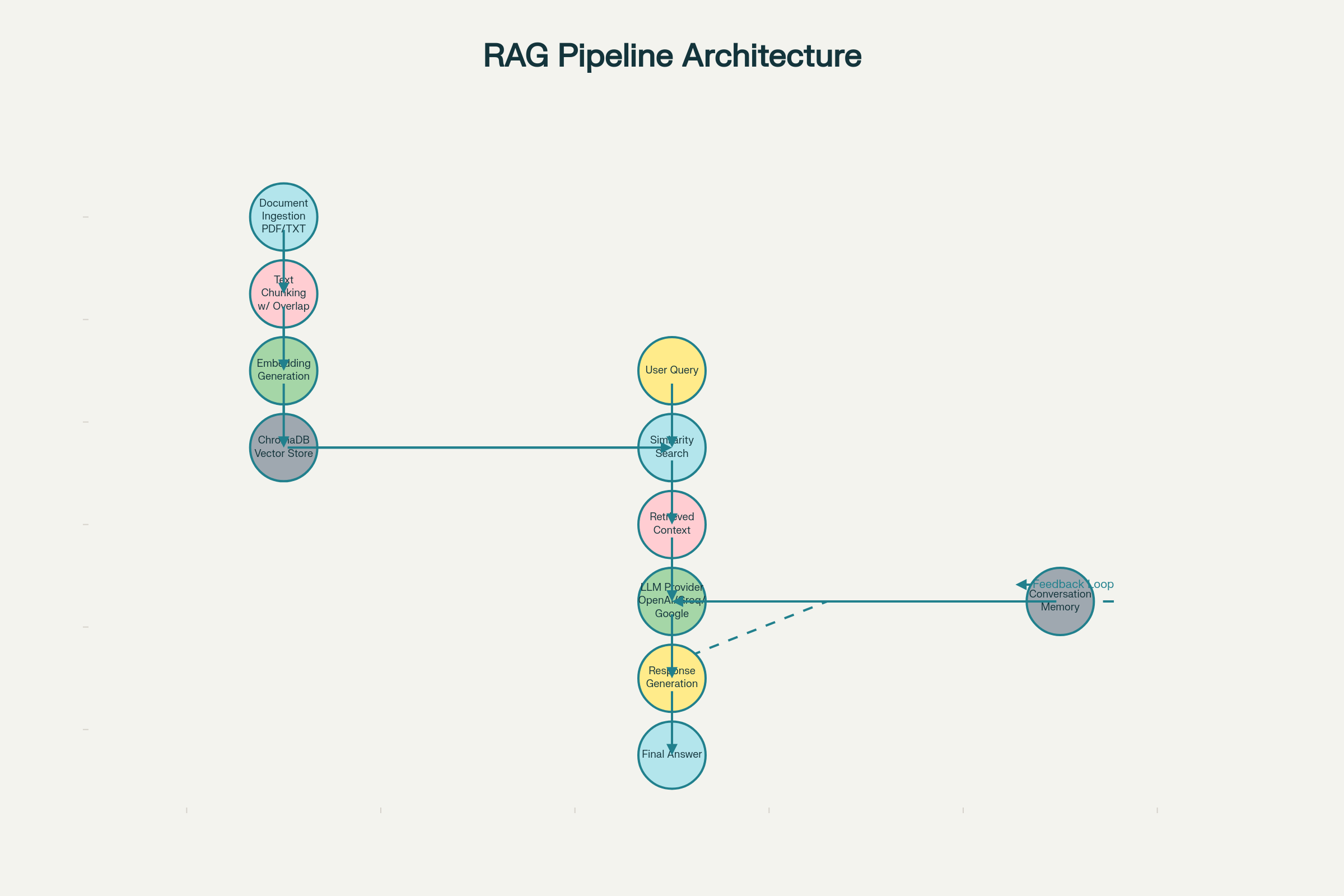
The RAG system consists of five integrated components:
3.1 Document Ingestion Pipeline
3.2 Text Chunking Engine
3.3 Embedding & Vector Database
3.4 Retrieval & Ranking Engine
3.5 Generation & Memory System
Why This Model?
| Criterion | all-MiniLM-L6-v2 | Why It Matters |
|---|---|---|
| Embedding Dimension | 384 dimensions | Optimal balance: enough expressivity for semantic nuance (vs. 96D) but computationally efficient (vs. 1536D) |
| Model Size | 33M parameters | Lightweight for production: fits in 60-80MB, runs on CPU-only systems without GPU |
| Training Data | Trained on 1B sentence pairs | Generalizes well across domains (general knowledge, technical docs, business content) |
| Benchmark Performance | Top performer on MTEB retrieval tasks | Consistently ranks in top 5% for semantic search and retrieval tasks across diverse document types |
| Latency | ~50-100ms per embedding | Fast enough for real-time query processing in production systems |
| Use Cases | General-purpose retrieval | Superior to domain-specific embeddings for heterogeneous document collections |
Trade-offs Considered:
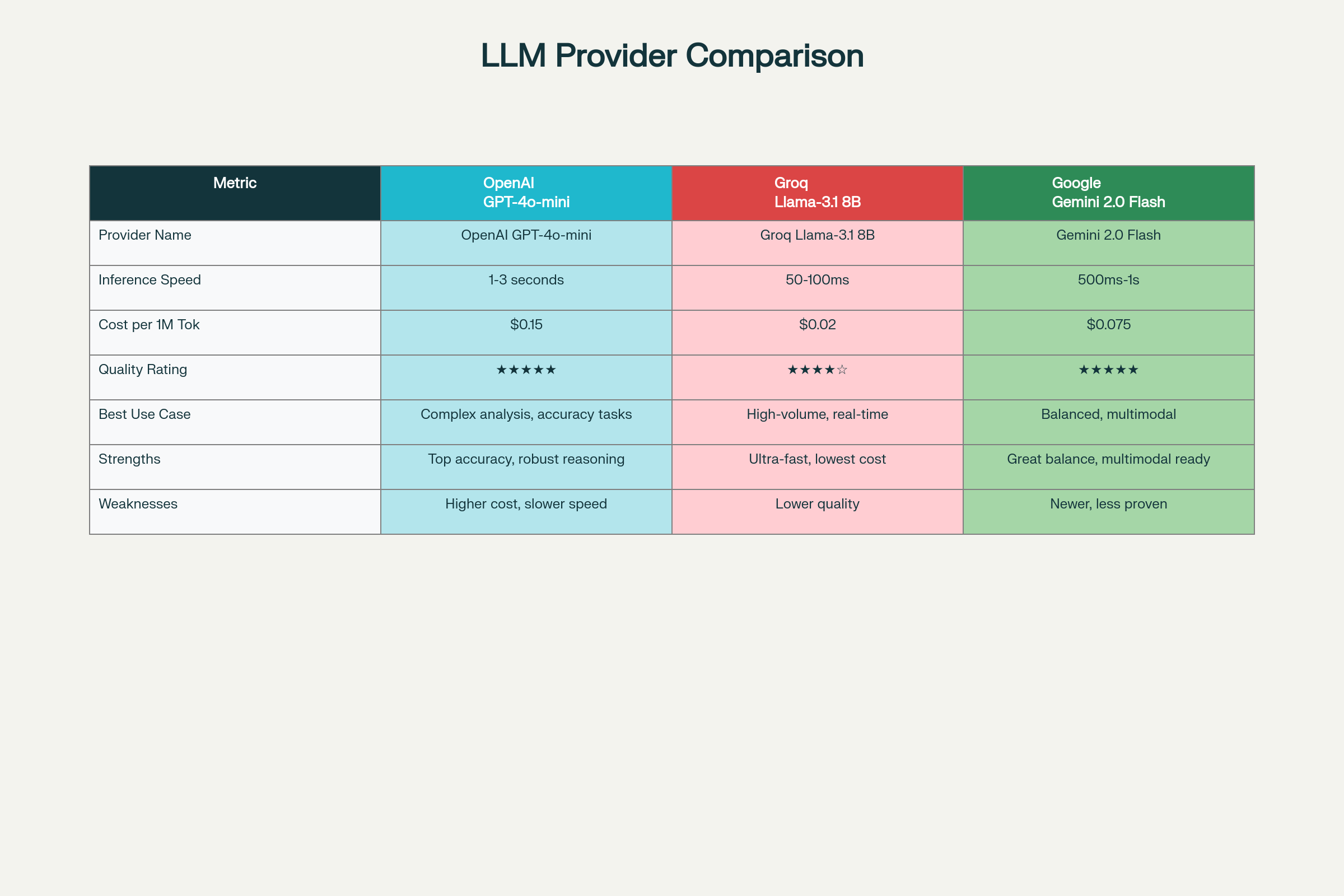
Why Support Multiple Providers?
Different use cases have different requirements:
| LLM Provider | Primary Strength | Best For | Cost/Speed Trade-off |
|---|---|---|---|
| OpenAI GPT-4o-mini | Highest quality reasoning, nuanced understanding | Complex analysis, accurate answer generation, when quality > speed | Medium cost, medium latency (1-3s) |
| Groq Llama-3.1 8B | Ultra-fast inference (100x faster than LLMs), cost-effective | High-volume production systems, real-time customer support, when speed > quality | Lowest cost, fastest (50-100ms) |
| Google Gemini 2.0 Flash | Balanced performance, multimodal capabilities, upcoming features | General-purpose use, future document image extraction | Competitive cost, fast latency (500ms-1s) |
Architecture Benefit: Users can switch providers based on:
Raw documents must be split into manageable segments for embedding and retrieval. Naive approaches fail:
Parameters:
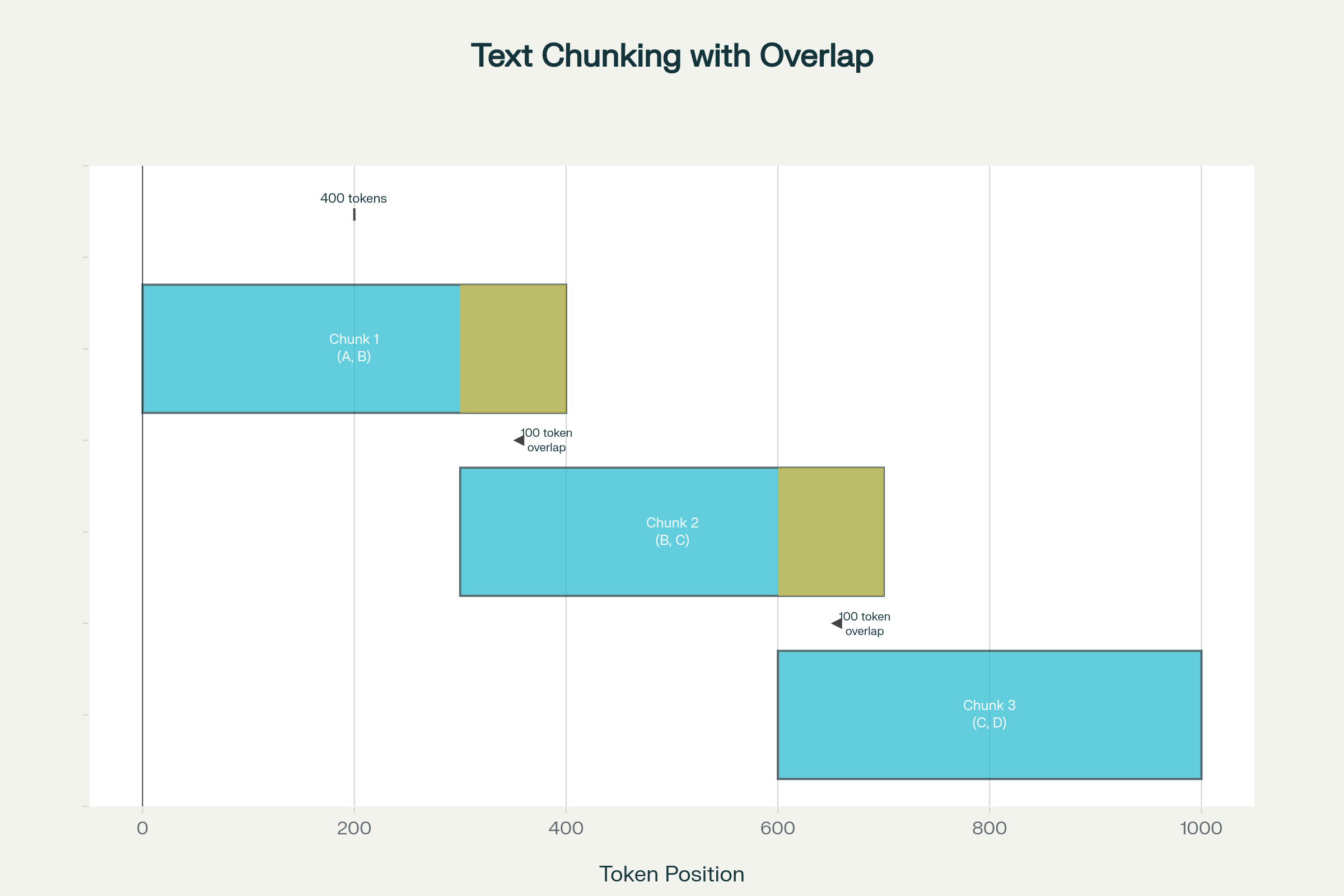
Overlap: 50-100 tokens (10-20% of chunk size)
Split Strategy: Prioritize semantic boundaries
Example Visualization:
Original Document:
[===== Chunk 1 (400 tokens) =====] <- Covers concepts A, B
[===== Chunk 2 (400 tokens) =====] <- Overlaps on B, covers B, C
[===== Chunk 3 (400 tokens) =====] <- Overlaps on C, covers C, D
This overlap ensures that boundary concepts (B, C) are fully captured in multiple chunks
User queries vary wildly in complexity and structure. Our system implements multi-step processing:
Step 1: Query Normalization
Step 2: Query Expansion
Step 3: Intent Classification
Step 4: Context-Aware Retrieval
Multi-Query Retrieval: Retrieve results for both original and expanded queries, then rank by frequency and relevance
Reranking: Use cross-encoder models to rerank initial retrieval results, improving top-K accuracy
Adaptive K: Adjust number of retrieved chunks based on query complexity (simple queries: K=3, complex: K=5-10)
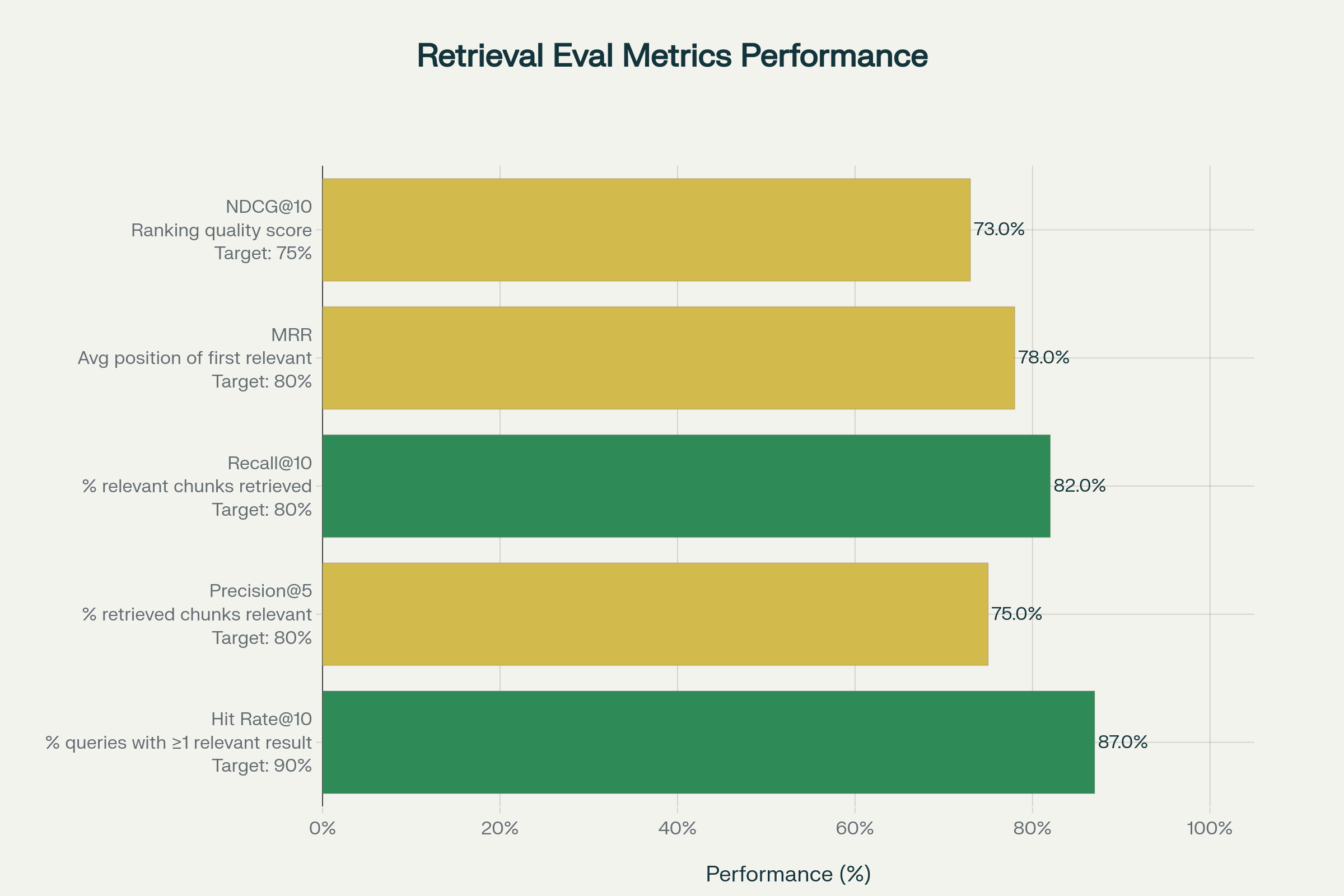
Without metrics, you can't distinguish between a working system and one that only seems to work. Metrics quantify:
Metric 1: Hit Rate@K
Metric 2: Precision@K
Metric 3: Recall@K
Metric 4: Mean Reciprocal Rank (MRR)
Metric 5: Normalized Discounted Cumulative Gain (NDCG)
# Pseudocode for evaluation workflow class RAGEvaluator: def evaluate_system(self, test_queries, ground_truth_docs): """ test_queries: List of [query, list of relevant doc_ids] ground_truth_docs: Dictionary mapping doc_id to actual relevant docs """ hit_rate_at_10 = self.calculate_hit_rate(test_queries, k=10) precision_at_5 = self.calculate_precision(test_queries, k=5) recall_at_10 = self.calculate_recall(test_queries, k=10) mrr = self.calculate_mrr(test_queries) ndcg = self.calculate_ndcg(test_queries, k=10) return { 'hit_rate@10': hit_rate_at_10, 'precision@5': precision_at_5, 'recall@10': recall_at_10, 'mrr': mrr, 'ndcg@10': ndcg }
Low Hit Rate: Your retrieval is missing results. Try:
Low Precision: Too many irrelevant chunks. Try:
Low Recall: Missing relevant information. Try:
Users don't ask isolated questions; they follow up with clarifications and related questions:
Turn 1: User: "What is CRISPR?"
Assistant: "CRISPR-Cas9 is a gene-editing technology..."
Turn 2: User: "How does it work?"
Assistant: Must understand "it" refers to "CRISPR" from Turn 1
Turn 3: User: "What are the risks?"
Assistant: Must maintain context about CRISPR throughout conversation
ConversationBufferMemory maintains:
Integration with RAG:
Current Limitation: Memory resets when application restarts (in-memory buffer)
Future Enhancement: Persistent database storage enabling:
Step 1: Clone Repository
git clone https://github.com/EphraimMagopa/rag-agentic-ai-project1.git cd rag-agentic-ai-project1
Step 2: Create Virtual Environment
python -m venv env source env/bin/activate # On Windows: env\Scripts\activate
Step 3: Install Dependencies
pip install -r requirements.txt
Step 4: Configure Environment Variables
cp .env_example .env # Edit .env with your API keys nano .env # or use your preferred editor
Example .env configuration:
# LLM Configuration (set at least one)
OPENAI_API_KEY=sk-proj-xxxxx
OPENAI_MODEL=gpt-4o-mini
GROQ_API_KEY=gsk_xxxxx
GROQ_MODEL=llama-3.1-8b-instant
GOOGLE_API_KEY=xxxxx
GOOGLE_MODEL=gemini-2.0-flash
# Vector Database
CHROMADB_COLLECTION_NAME=rag_documents
EMBEDDING_MODEL=sentence-transformers/all-MiniLM-L6-v2
Step 5: Prepare Documents
mkdir -p data # Add your .txt or .pdf files to data/ directory
Step 6: Verify Installation
python -c "import langchain; import chromadb; print('Installation successful!')"
Launch Interactive Application
python app.py
Example Session 1: General Knowledge
Enter a question or 'quit' to exit: What is CRISPR gene editing?
<!-- RT_DIVIDER -->
# Experiments
We tested the assistant with a sample corpus of Ready Tensor publications and Wikipedia articles. Each interaction involved:
- Asking an initial factual question covered by the corpus.
- Following up with a related, more specific or context-dependent question.
- Testing edge cases such as queries outside the knowledge base.
Relevant logging and print statements were enabled to verify memory context and retrieval effectiveness.
<!-- RT_DIVIDER -->
# Results
- The assistant provides clear, well-structured answers grounded in the ingested documents.
- Memory integration demonstrated improved handling of follow-up questions (e.g., pronoun reference resolution).
- Example interaction:
:::note{title="Example interaction:"}
User: What is CRISPR gene editing?
Assistant: CRISPR-Cas9 is a revolutionary gene-editing technology...
User: How does it work?
Assistant: CRISPR works by targeting specific DNA sequences...
:::
- Out-of-scope questions receive appropriate fallback responses:
"I am sorry, but I do not have enough information to answer that."
<!-- RT_DIVIDER -->
# Conclusion
This RAG-based AI assistant combines the strengths of vector retrieval and LLM reasoning with the added context of conversational memory. It sets the foundation for more advanced agentic AIs that can integrate broader tool use, intermediate reasoning, and persistent knowledge. Future enhancements may include real tool integration, persistent long-term chat memory, richer document types, and advanced reasoning modules.
