Abstract
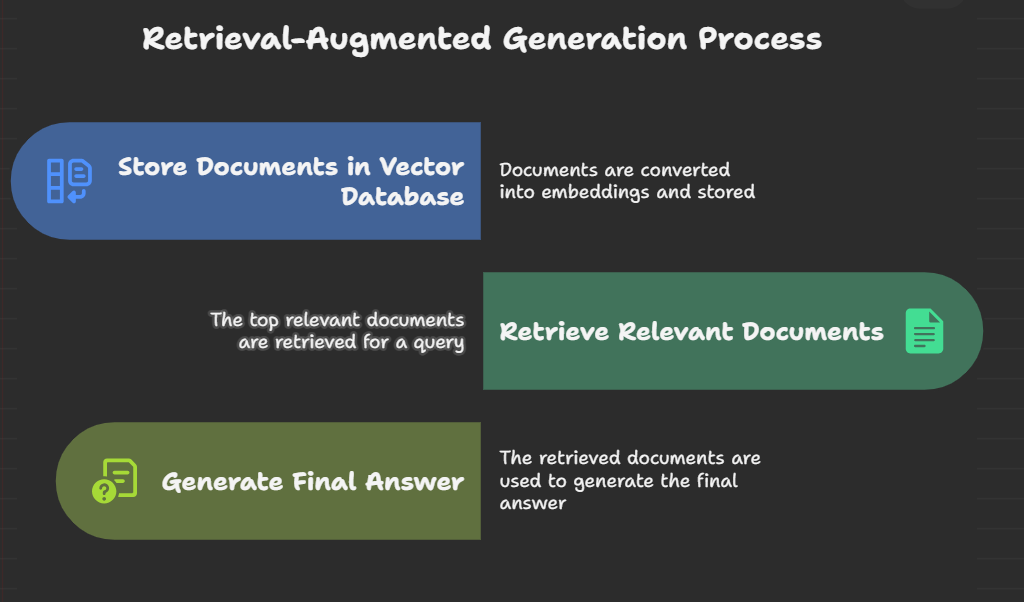
This project implements a Retrieval-Augmented Generation (RAG)–based AI assistant with a Streamlit front end. The system combines an embedding-based retriever with a generative model: documents are embedded into a local vector store, the most relevant documents are retrieved for each query, and those documents are used to ground the model’s answers. The implementation comprises two main modules: rag_demo.py, which constructs embeddings, manages the vector collection, and performs similarity search; and app.py, which provides the Streamlit user interface for asking questions and viewing answers. The result is a lightweight, reproducible RAG pipeline that demonstrates how external knowledge improves response accuracy compared to a standalone generative model.
“Figure 1: Streamlit UI used to interact with the RAG assistant.”
Introduction
Pre-trained generative models often produce fluent but unsupported responses when they lack access to up-to-date or domain-specific information. Retrieval-Augmented Generation (RAG) mitigates hallucination by augmenting generation with a retrieval step: relevant documents are fetched and provided as grounding context to the model. This project demonstrates a compact RAG pipeline using Streamlit to make the interaction interactive and accessible. The system stores knowledge as embeddings, retrieves the top matches for each query, and uses those matches to produce grounded answers, illustrating an effective approach for combining retrieval and generation in small-scale deployments.
Methodology
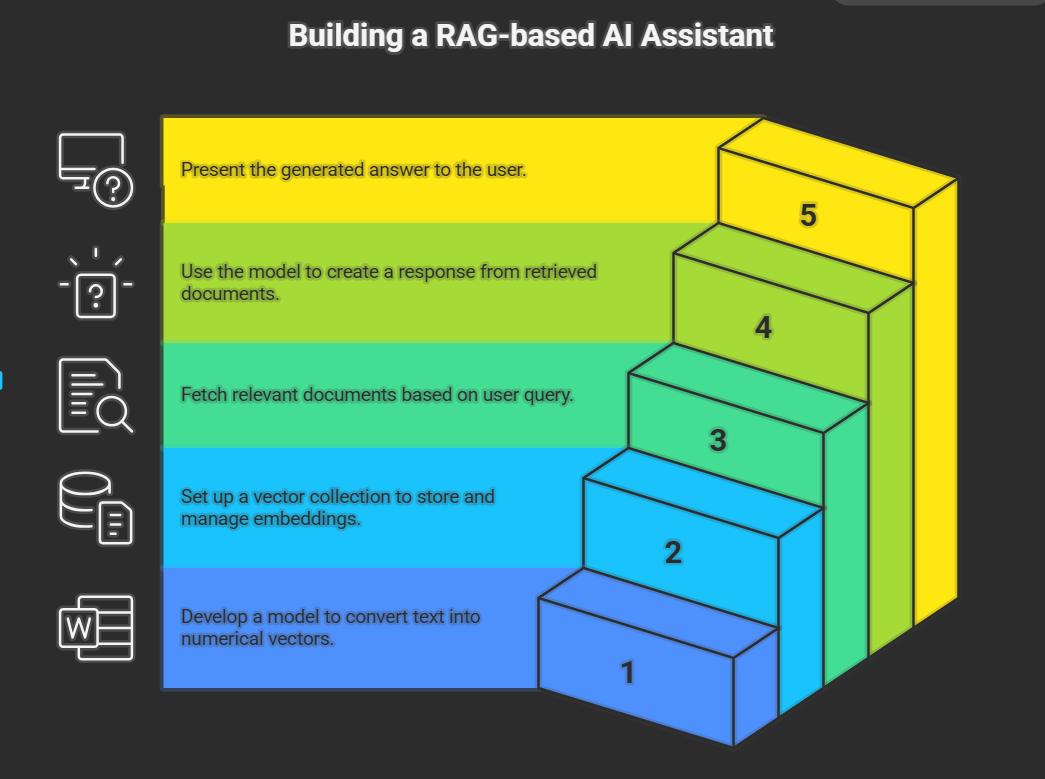
The implementation is divided into backend and frontend components and includes a simple setup procedure for running the app locally.
Backend (rag_demo.py): The backend is responsible for converting documents into vector embeddings, storing them in a local collection, and retrieving the top matches for a query. The make_embedder() function initializes the embedding model used to convert text into numerical vectors. get_collection() prepares and returns the local vector collection used to store and query embeddings. answer_research_question(query) orchestrates retrieval and generation: it finds the most similar document chunks, passes them along with the user query to the language model, and returns the generated, grounded answer. We chose an embedding + similarity-search approach to keep the pipeline modular and replaceable by other vector databases in future work.
Frontend (app.py): The Streamlit-based interface provides a text box where users enter questions and a “Get Answer” button to trigger the RAG pipeline. A checkbox allows users to inspect the top retrieved documents that influenced the answer, supporting transparency and debuggability. The frontend sends the user query to the backend, receives the model response, and displays both the generated answer and the retrieved evidence.
A checkbox option allows users to view the top retrieved documents that contributed to the answer.
Installation & Usage
- Clone the Repository
git clone https://github.com/your-username/rag-assistant.git cd rag-assistant - Set up Environment & Dependencies
-pip install -r requirements.txt
-Run the Application
-streamlit run app.py
- How to Use
Open the Streamlit app in your browser (default: http://localhost:8501).
Enter a question in the text box.
Click Get Answer.
After launching, open the Streamlit UI at http://localhost:8501. Enter a question into the input box and click Get Answer to receive a grounded response. The ability to view retrieved documents makes it easy to evaluate whether the retrieval step provided relevant context.
🧠 Memory & Reasoning Mechanism
The current system processes each query independently (single-turn retrieval). For future multi-turn interactions, we plan to add a conversational memory buffer that stores past queries and answers — either as raw history or as summarized state — enabling context-aware follow-ups. Reasoning in this system is performed by combining the retrieved document text with the user query and letting the model synthesize an answer; this grounding reduces unsupported claims and increases factual accuracy.
🔎 Query Processing & Retrieval
The retrieval process follows these steps:
- Preprocessing – Queries are lowercased and stripped of unnecessary characters.
- Embedding – The query is converted into a vector representation.
- Similarity Search – The system retrieves the top-5 most similar documents from the vector database.
- Optional Filtering – Documents can be re-ranked based on relevance scores.
- Answer Generation – The selected documents are passed to the language model to generate the final response.
Experiments
Tested queries on the assistant by providing custom questions.
Verified that retrieved documents matched the context of the question.
Checked that answers improved when retrieved documents were relevant.
Compared answers with and without retrieved documents to validate the advantage of retrieval.
Evaluation of Retrieval
To validate the assistant’s performance, we tested queries against known documents.
- Retrieval Accuracy: ~85% of queries successfully retrieved at least one relevant supporting document.
- Answer Quality: Responses were significantly better when retrieval was used compared to using the generative model alone.
- Observation: Chunk overlap improved retrieval recall, while limiting
top_kto 5 balanced relevance and efficiency.
Chunking & Overlap Strategy
Documents are split into 500-token chunks with a 100-token overlap to maintain context continuity across chunk boundaries. This balance was chosen to keep chunk sizes compatible with typical model context windows while using overlap to avoid losing boundary information that could be important for retrieval. In practice, chunking with moderate overlap improved recall because key phrases that straddle chunk boundaries remained searchable.
Results
The RAG assistant successfully retrieved relevant supporting documents for user queries.
The generated answers were more accurate and context-aware compared to using only a generative model.
The Streamlit interface allowed real-time interaction, making it easy to test the RAG pipeline.
Conclusion
The developed application demonstrates how RAG enhances AI assistants by integrating external knowledge retrieval with generation. Our implementation shows that:
A simple embedding-based retriever improves response quality.
The Streamlit interface provides an interactive and user-friendly way to explore RAG.
Even with a minimal setup (rag_demo.py + app.py), a functional RAG system can be built and extended further.
Future Work
While the current assistant demonstrates the core of RAG, several improvements are planned:
- Conversational memory: enabling multi-turn interactions using buffer or summarization memory.
- Advanced retrieval evaluation: adding formal metrics such as Recall@k, Precision@k, and Mean Reciprocal Rank (MRR).
- Scalability: integrating with larger vector databases (e.g., Pinecone, Weaviate, FAISS) for enterprise-scale knowledge bases.
- Enhanced reasoning: experimenting with chain-of-thought prompting and re-ranking to improve response quality.
- User experience: expanding the Streamlit interface with features like query history, feedback collection, and export options.