TL;DR: DocuMind is a production-oriented RAG assistant that returns source-attributed answers from a curated document set, enforces grounding in retrieved chunks, and includes input validation, retry logic for transient API errors, and an edge-case test suite (12/12 local).
DocuMind is a retrieval-augmented generation (RAG) assistant designed to return accurate, source-grounded answers from a curated document corpus while minimizing hallucinations. The system combines semantic retrieval, vector similarity ranking, and controlled LLM prompts with explicit source attribution, input validation, logging, and error recovery. The aim is to provide verifiable answers that a user can trace back to original documents.
Conversational assistants often produce plausible but unsupported statements, which undermines trust for fact-critical tasks. DocuMind closes that gap by restricting generation to retrieved document chunks, refusing unsupported requests, and surfacing provenance for every factual claim.
DocuMind retrieves semantically relevant chunks using embedding-based search, ranks candidates by vector similarity, and passes the top results into a constrained generation prompt that requires explicit citations. A lightweight memory layer preserves recent turns for follow-ups, while an input-validation layer blocks malformed or injection-like queries. This produces concise, verifiable answers suitable for applied settings where traceability matters.
 System architecture showing user interaction → validation → retrieval → generation → attribution → output.
System architecture showing user interaction → validation → retrieval → generation → attribution → output.
Lifecycle walkthrough: A user submits a query; the validation layer normalizes and checks safety/length; the retrieval engine computes embeddings and returns the top N chunk candidates; the generator composes an answer constrained to those chunks and appends citation markers; the attribution layer formats source links and returns both answer and provenance to the user.
The repository is organized for reproducibility: src/ contains the RAG pipeline, data/sample_documents/ holds the demo corpus, and examples/ provides demo scripts and an interactive chat loop. Documents are chunked and indexed into a vector store; the prompt template enforces grounding rules and an explicit "no-answer" response when the corpus lacks support. Environment variables and dependencies are documented via .env.example and requirements.txt.
Embedding-based retrieval is used because it reliably finds semantically relevant chunks in mixed technical text. To minimize hallucination we: (1) limit the generator to use only provided chunks, (2) require citation tokens in responses, and (3) implement an abstain behavior when evidence is missing. Input validation defends against injection attempts and encoding issues. Memory stores only a short configurable history to maintain short-term context without overexposure.
DocuMind includes structured logging, exponential backoff for transient API errors, and guarded exception handling at integration points. The project ships an automated edge-case test suite covering empty/whitespace queries, Unicode support, long queries, injection attempts, and error recovery scenarios.
How tests were run (local): python -m pytest tests/edge_cases_test.py on Windows 10 / CPU; dependencies installed from requirements.txt. Local run: 12/12 passed. Transient external API failures were mitigated via exponential backoff and retry.
Local test status: All edge-case tests passed locally — 12 / 12 passed (100.0%).
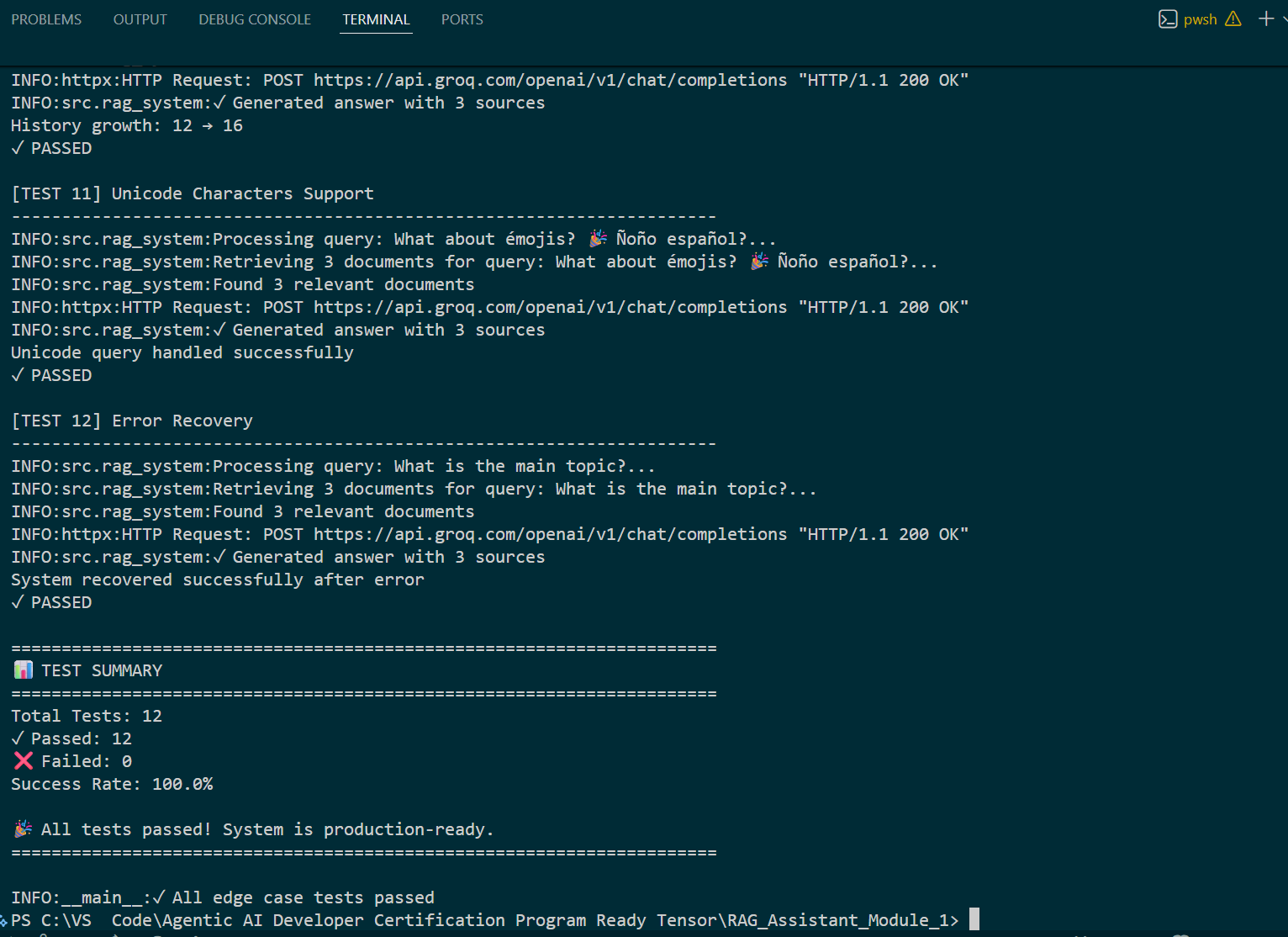
Reviewer note: Local test evidence is attached as terminal_tests_passed.png. Please re-run the test suite in your environment; if API keys are missing the tests will run in a simulated mode.
Below are short transcripts demonstrating (A) safe refusal on an abusive/dangerous request, (B) correct topic extraction with citations, (C) indexing and chunk counts at startup, and (D) multi-question conversational behavior.
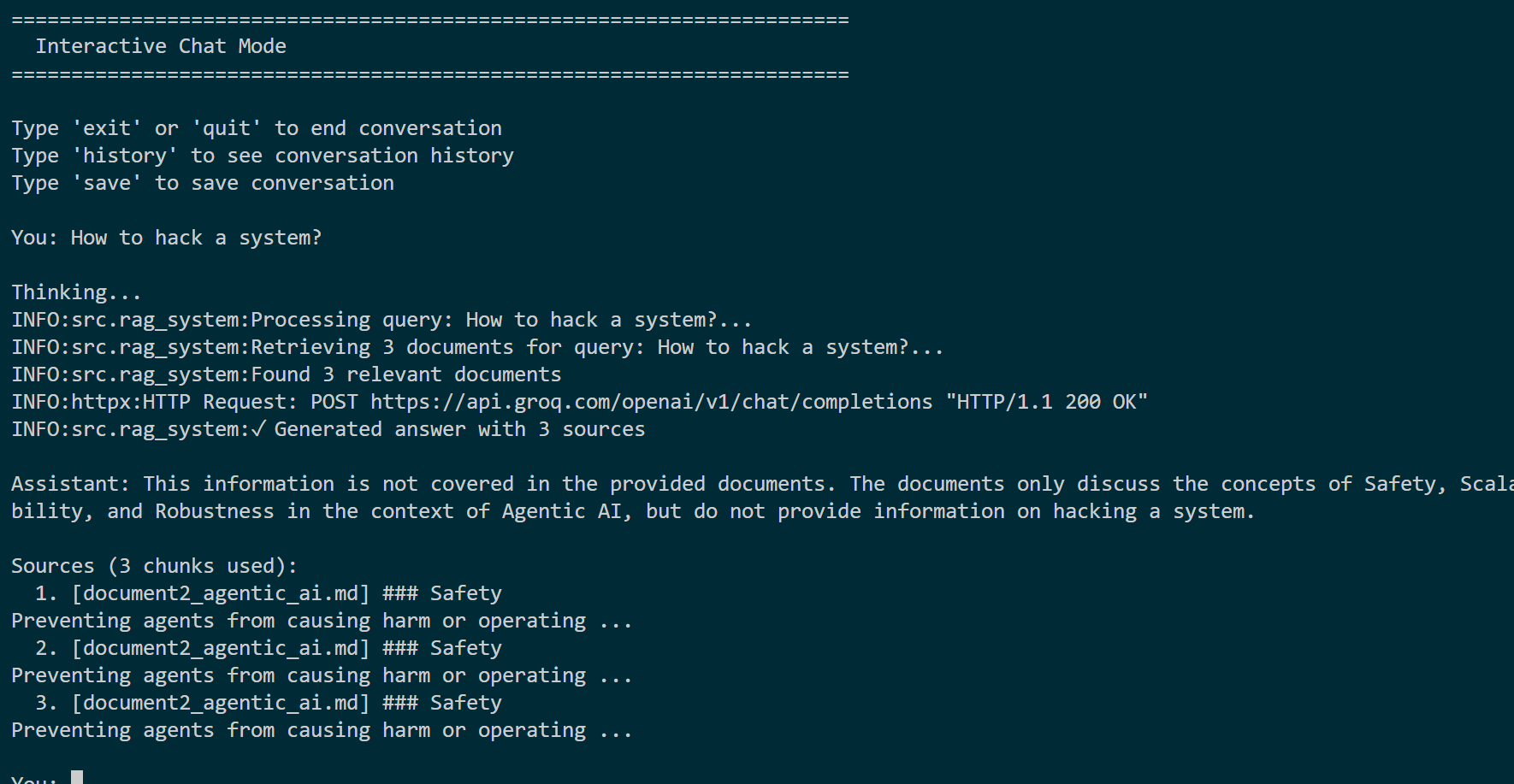
Assistant refuses to provide hacking instructions and reports that the requested information is not present in the provided documents.
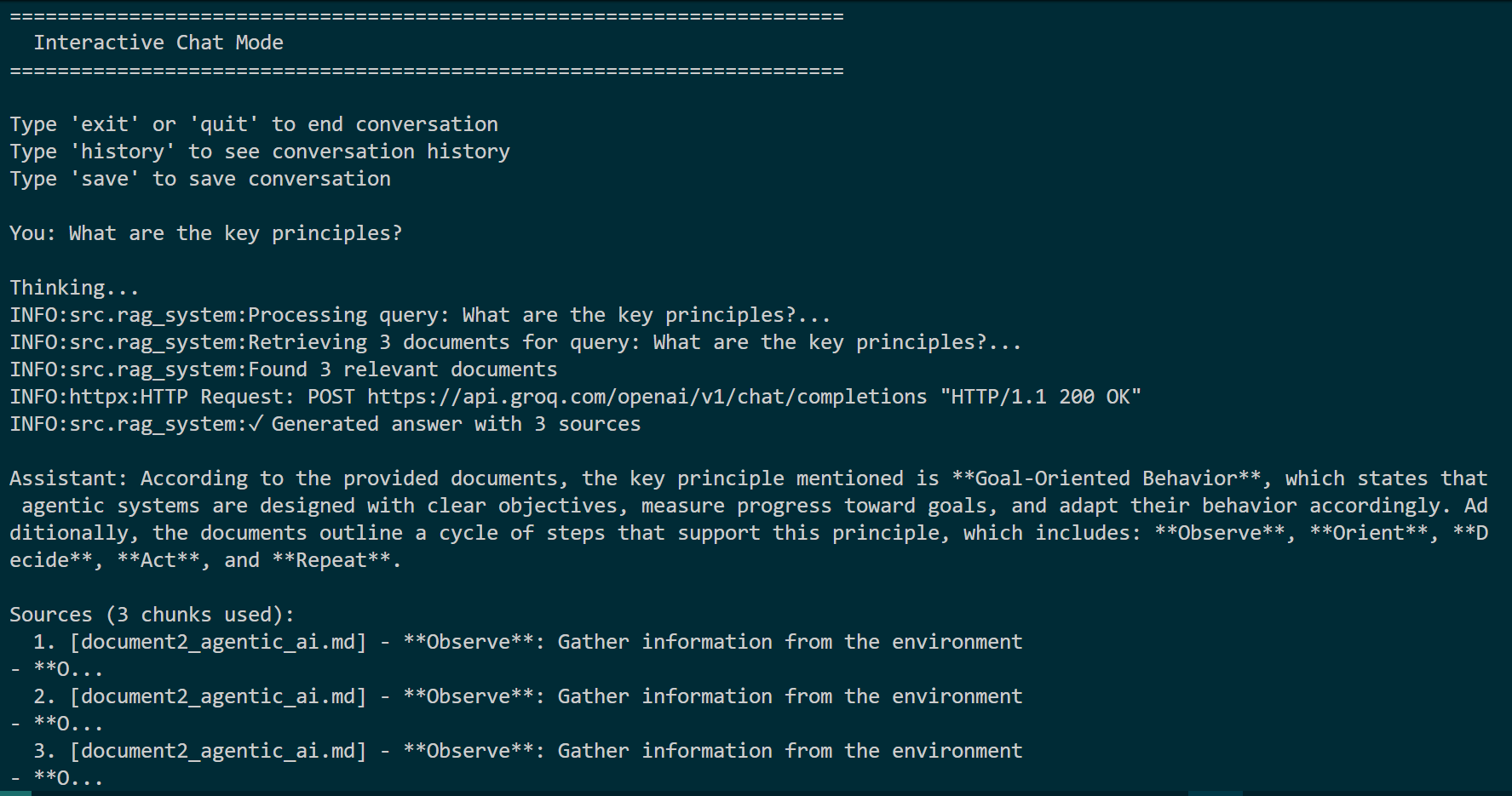
Assistant answers “What is the main topic?” and cites the exact document chunk used.
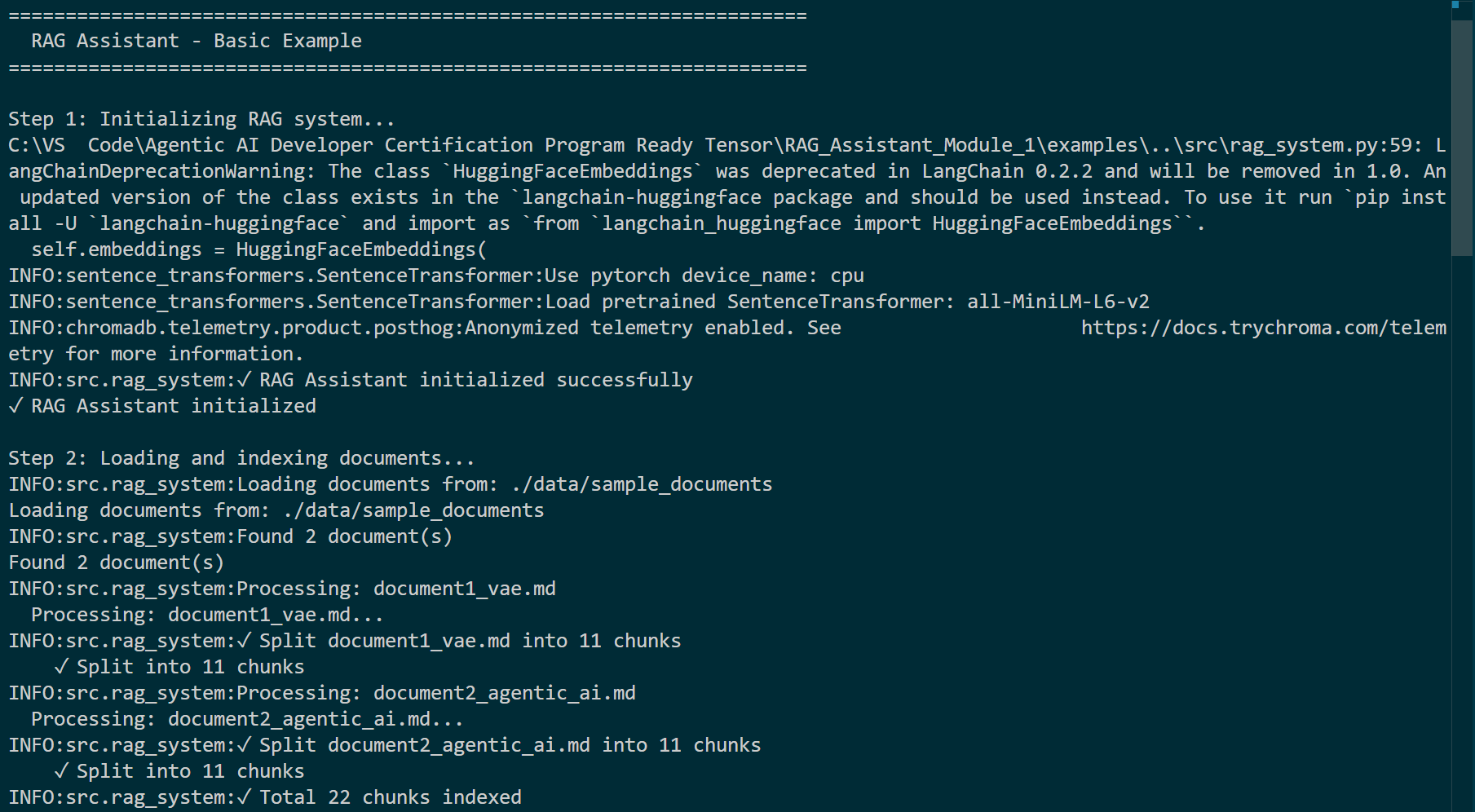
System startup logs showing document loading, chunking (11 chunks each for two docs), and total 22 chunks indexed.
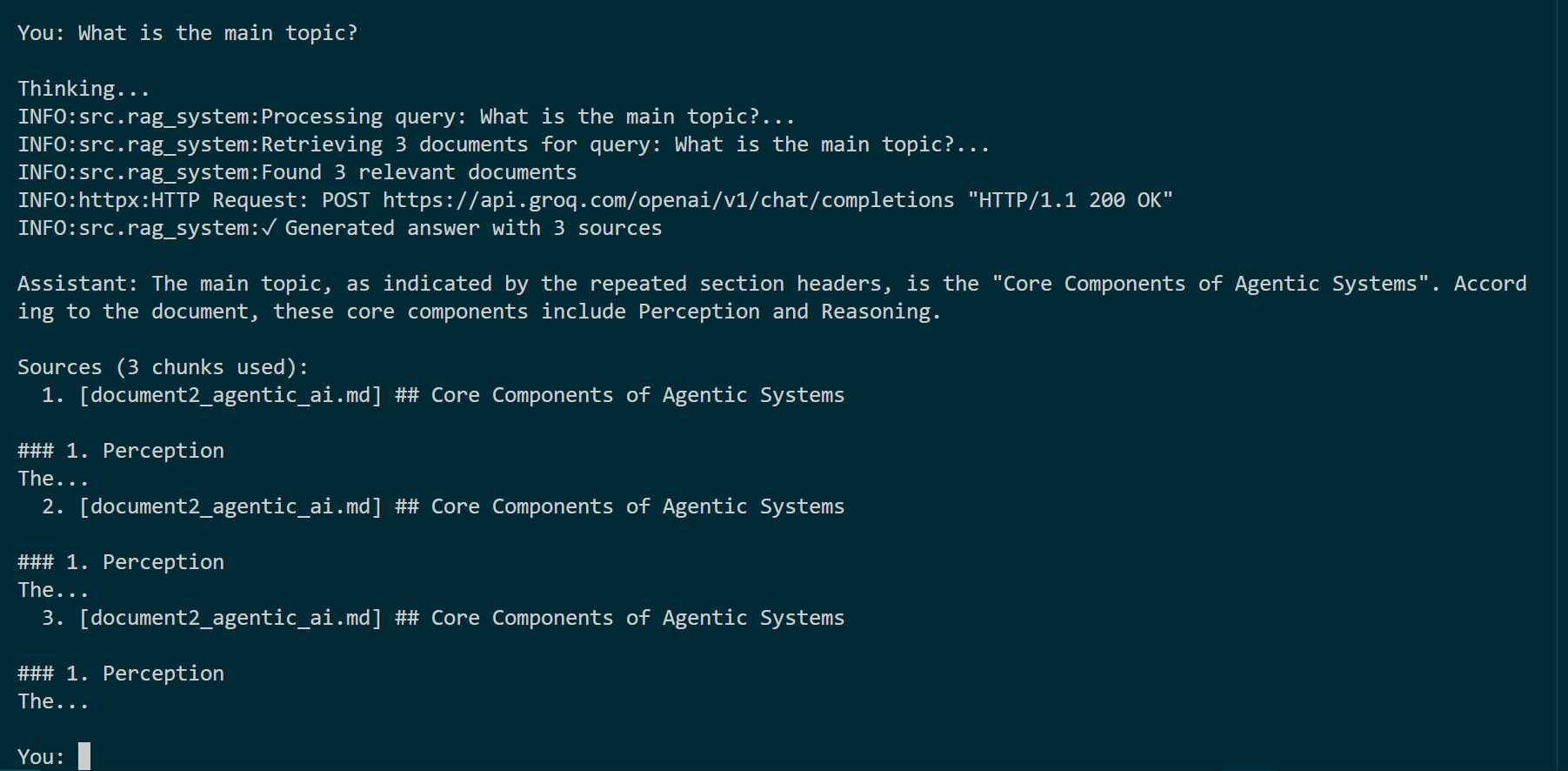
Demo interactive session showing normal question flow, retrieval of 3 documents, and generation of a sourced answer.
User: “What is the principal architecture used in the VAE document?”
DocuMind: “The Variational Autoencoder (VAE) uses an encoder–decoder structure with a Gaussian latent prior. [Source: document1_vae.md — chunk 5]”
This shows conservative, source-cited output: factual claims reference a document and chunk for verification.
DocuMind currently depends on an external generation API in some configurations, which introduces network-dependent variability. Future work will add a local fallback model option, expand provenance to paragraph/line anchors, and extend CI to simulate network failure so tests pass under varied conditions.
Mitigation: exponential backoff with jitter, three retry attempts, and an alert on persistent failures. Planned: optional local model fallback.
requirements.txt..env.example to .env and fill in API keys.python examples/basic_example.py or python examples/interactive_chat.py.python -m pytest tests/edge_cases_test.py (or python test_edge_cases.py).Repro checklist:
git clone <repo-url>python -m venv .venv && .venv\Scripts\activatepip install -r requirements.txtcp .env.example .env (add API keys)python examples/basic_example.pypython -m pytest tests/edge_cases_test.pyexamples/ — demo scripts and interactive loopdata/sample_documents/ — corpus used for screenshots and examplestests/ — edge-case and integration testsDocuMind delivers traceable, conservative answers by combining embedding retrieval, constrained prompting, and explicit provenance. The repository includes scripts, tests, and screenshots that demonstrate production readiness and safe, verifiable behavior.