
The development of artificial intelligence systems capable of understanding and responding to complex queries has become increasingly crucial in our data-driven world. This project demonstrates the creation of a sophisticated Retrieval Augmented Generation (RAG) assistant specifically designed to unlock the potential of custom knowledge bases. Rather than relying on generic, pre-trained knowledge, this system enables organizations and researchers to create intelligent assistants that can answer questions based on their specific datasets and documentation.
The RAG Assistant addresses a fundamental challenge in information management: how to efficiently query and utilize information that exists within specialized datasets. In this implementation, we focus on a collection of publication details stored in project_1_publications.json, creating a system that can understand natural language questions and provide contextually relevant answers drawn from this custom knowledge base.
This project serves as both a practical implementation and an educational resource, developed as part of the Agentic AI Developer Certification Program. It demonstrates how modern AI technologies can be combined to create powerful, domain-specific intelligence systems.
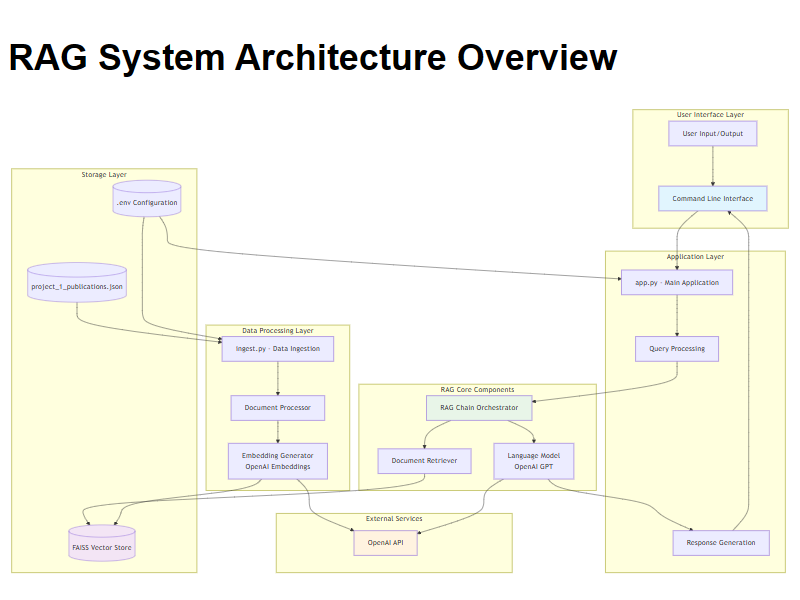
The assistant leverages cutting-edge technologies to create a robust and scalable solution. LangChain provides the orchestration framework for the RAG pipeline, offering sophisticated tools for document processing, embedding generation, and chain management. FAISS (Facebook AI Similarity Search) serves as the vector storage and retrieval engine, enabling lightning-fast similarity searches across high-dimensional embedding spaces.
The system architecture follows five primary objectives that guide its development and implementation:
Robust Data Ingestion Pipeline Development
The system implements a comprehensive data processing pipeline that transforms raw JSON publication data into optimized vector representations. This pipeline handles data validation, metadata extraction, text preprocessing, and embedding generation with built-in error handling and logging capabilities.
High-Performance Vector Storage Implementation
Utilizing FAISS for vector storage ensures efficient similarity search operations across publication data. The implementation includes optimization strategies for index creation, persistence, and retrieval performance tuning.
Advanced Question-Answering Architecture
The system employs LangChain's RAG architecture to create a sophisticated question-answering pipeline. This includes intelligent retrieval strategies, context optimization, and response generation using state-of-the-art language models.
Intuitive User Interface Design
A well-designed command-line interface provides users with seamless interaction capabilities. The interface includes helpful prompts, error messages, and response formatting that enhances the user experience.
Comprehensive Documentation and Example Implementation
The project serves as a reference implementation for building RAG systems, complete with detailed documentation, code comments, and best practices that enable others to understand and extend the system.
The data ingestion phase transforms raw publication data into a queryable knowledge base through a sophisticated multi-step process. This phase is implemented in ingest.py and handles the complete transformation from source data to vector index.
Data Loading and Validation
The system begins by loading publication records from the project_1_publications.json file with comprehensive error handling and data validation. Each publication record is verified for completeness and structural integrity before processing.
def load_and_validate_publications(json_file_path: str) -> List[Dict]: """Load and validate publication data with comprehensive error handling.""" try: with open(json_file_path, 'r', encoding='utf-8') as file: publications = json.load(file) validated_publications = [] for pub in publications: if validate_publication_structure(pub): validated_publications.append(pub) else: logger.warning(f"Skipping invalid publication: {pub.get('id', 'unknown')}") return validated_publications except Exception as e: logger.error(f"Failed to load publications: {e}") raise
Content Enhancement and Optimization
For each publication, the system extracts crucial metadata including publication ID, title, description, author username, and licensing information. To enhance retrieval accuracy for specific queries, the system employs an intelligent content enhancement strategy where publication IDs and titles are strategically prepended to the main content before embedding generation.
Advanced Embedding Generation
The system generates dense vector embeddings using OpenAI's advanced embedding models. These embeddings capture semantic relationships within the publication content, enabling sophisticated similarity searches that go beyond simple keyword matching.
Persistent Vector Store Creation
The processed embeddings and their corresponding documents are organized into a FAISS vector store optimized for fast retrieval. This index is persisted to the local faiss_index directory, enabling quick loading for subsequent query operations.
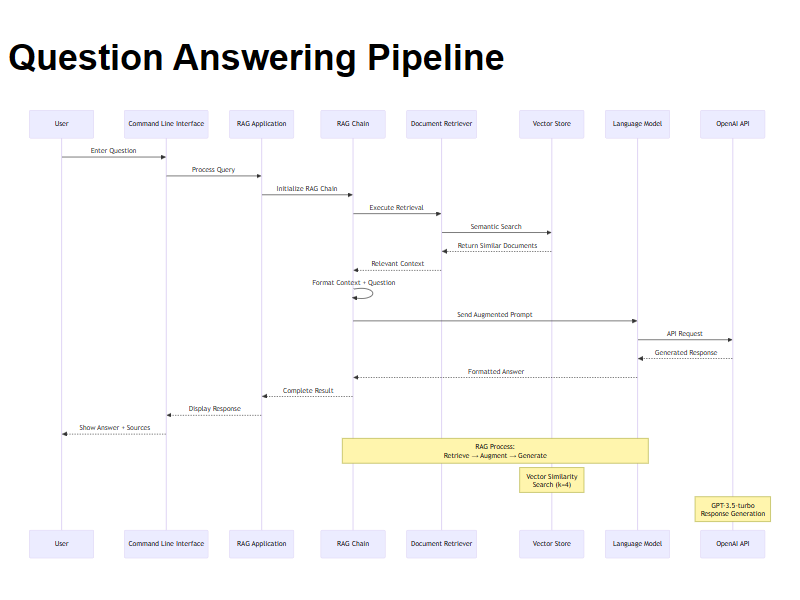
The question-answering phase implements the core RAG functionality, transforming user queries into contextual responses through a sophisticated retrieval and generation pipeline implemented in app.py.
System Initialization and Index Loading
The application initializes by loading the pre-built FAISS vector store and establishing connections to the OpenAI API. This initialization includes validation of all required components and graceful error handling for missing dependencies.
Query Processing and Understanding
User questions are processed through advanced natural language understanding capabilities. The system handles various query types, from specific information requests to complex analytical questions requiring synthesis across multiple publications.
Semantic Retrieval and Context Assembly
The user's question undergoes embedding generation using the same model employed during ingestion. The system then performs semantic similarity search against the vector store to identify the most relevant publication content. Retrieved documents are intelligently ranked and filtered to provide optimal context for response generation.
Augmented Response Generation
Retrieved document chunks are formatted and combined with the original user question to create a comprehensive prompt for the language model. This augmentation process ensures that the AI has sufficient context to generate accurate, well-grounded responses.
def generate_contextual_response(query: str, retrieved_docs: List[Document]) -> str: """Generate contextually aware responses using retrieved documents.""" context = format_documents_for_prompt(retrieved_docs) prompt_template = """ Based on the following publication information, provide a comprehensive answer to the user's question. Context from Publications: {context} User Question: {question} Please provide a detailed answer based solely on the information provided above. """ response = llm.invoke(prompt_template.format(context=context, question=query)) return response
Response Presentation and User Interaction
Generated responses are presented to users with clear formatting and source attribution. The system maintains conversation context and provides options for follow-up questions or clarifications.
The project follows a clean, modular architecture that promotes maintainability and extensibility. Each component has well-defined responsibilities and clear interfaces with other system parts.
Data Ingestion Module (ingest.py)
This foundational script handles the complete transformation of raw publication data into a queryable vector store. It implements robust error handling, progress tracking, and optimization strategies for efficient processing of large datasets.
Main Application Interface (app.py)
The primary application provides an intuitive command-line interface for interacting with the RAG assistant. It manages the complete query lifecycle from user input to response presentation, including session management and error recovery.
Dependency Management (requirements.txt)
Comprehensive dependency specification ensures consistent deployment across different environments. The file includes version constraints and compatibility information for all required packages.
Vector Store Persistence (faiss_index)
This directory contains the generated FAISS vector store files, enabling quick application startup and consistent performance across sessions. The structure includes both index files and metadata for complete store reconstruction.
Configuration Management (.env)
Environment-specific configuration management keeps sensitive information like API keys separate from source code. This approach supports different deployment environments and enhances security practices.
Development Tools (.gitignore, README.md)
Comprehensive development support files ensure clean version control practices and provide detailed documentation for setup, usage, and contribution guidelines.
The RAG Assistant requires Python 3.8 or higher to ensure compatibility with modern AI libraries and frameworks. An active OpenAI API key provides access to embedding and language model services essential for system operation.
Repository Acquisition and Environment Preparation
Begin by cloning the project repository and establishing a clean Python environment for dependency management:
git clone https://github.com/AmmarAhmedl200961/simple-rag.git cd simple-rag
Virtual Environment Configuration
Create an isolated Python environment to prevent dependency conflicts and ensure consistent operation:
# Windows Environment python -m venv venv .\venv\Scripts\activate # macOS/Linux Environment python3 -m venv venv source venv/bin/activate
Dependency Installation and Verification
Install all required packages and verify successful installation:
pip install -r requirements.txt pip list # Verify installation success
API Configuration and Security Setup
Configure the OpenAI API key through environment variables for secure access:
# Create .env file with your API key echo "OPENAI_API_KEY='your_actual_openai_api_key'" > .env
Data Source Preparation and Validation
Ensure the publication data file is correctly positioned and accessible to the ingestion script. Verify data integrity and format compliance before processing.
Vector Store Creation Process
Execute the data ingestion pipeline to transform raw publication data into a queryable vector store:
python ingest.py
Expected output demonstrates successful processing:
Loading publications from project_1_publications.json...
Processing 150 publications for embedding generation...
Creating FAISS vector store with optimized parameters...
Vector store successfully created and saved to faiss_index/
Interactive Assistant Activation
Launch the RAG assistant for interactive question-answering sessions:
python app.py
The system provides immediate feedback and guidance:
RAG Assistant initialized successfully!
Vector store loaded with 150 publications
Type your questions below (type 'exit' to quit):
The system excels at answering precise questions about publication details, demonstrating its ability to locate and extract specific information from the knowledge base:
Query Example: Publication Identification
User: What is the title of the publication with ID 6652f47f792e787411011179?User: What is the title of the publication with ID 6652f47f792e787411011179?
This project successfully demonstrates the design and implementation of a robust Retrieval Augmented Generation assistant. By leveraging LangChain for orchestration and FAISS for high-speed vector search, we have created a powerful tool capable of transforming a static JSON dataset into an interactive and intelligent knowledge base. The modular architecture not only ensures maintainability and scalability but also establishes this project as a valuable, practical blueprint for developers looking to build their own domain-specific AI applications. The RAG Assistant effectively bridges the gap between raw data and actionable insights, showcasing the immense potential of combining large language models with custom information retrieval systems.
While the current implementation provides a strong foundation, there are several exciting avenues for future development that could further enhance its capabilities:
Advanced Retrieval Strategies: Implement more sophisticated retrieval techniques such as hybrid search (combining semantic and keyword-based methods), re-ranking models to improve context relevance, and parent document retrieval for better contextual understanding.
Enhanced User Interface: Transition from the command-line interface to a graphical user interface (GUI) using frameworks like Streamlit or Flask. This would provide a more intuitive user experience, enabling features like chat history, source document visualization, and user feedback mechanisms.
Scalability and Production Deployment: Adapt the system for larger-scale use by integrating with cloud-native vector databases (e.g., Pinecone, Weaviate) and deploying the application within a containerized environment (e.g., Docker) for improved scalability and portability.
Agentic Capabilities: Evolve the assistant into a more autonomous agent. This could involve enabling it to perform multi-step reasoning, ask clarifying questions when a query is ambiguous, or even suggest relevant topics based on the user's line of questioning.
Continuous Evaluation and Monitoring: Integrate a robust evaluation framework, such as RAGAs, to continuously monitor the quality and accuracy of the assistant's responses. This would allow for ongoing fine-tuning and improvement of the retrieval and generation components.