A No-Code, Scalable Document Intelligence System
Organizations today manage large volumes of unstructured data—PDFs, spreadsheets, reports, and internal documents scattered across multiple systems. Retrieving relevant information from this fragmented data becomes increasingly complex as datasets grow.
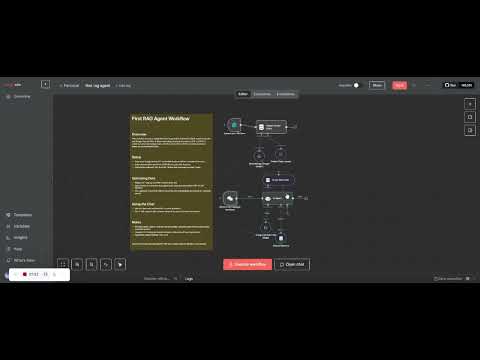
To address this challenge, this publication presents a Retrieval-Augmented Generation (RAG) workflow built entirely in n8n (a no-code automation platform) and powered by Google Gemini AI. This workflow transforms unstructured documents into an interactive knowledge base that enables users to chat directly with their PDFs and CSV files using natural language.
By integrating document ingestion, Google Gemini embeddings, semantic vector storage, and context-aware response generation, this project delivers a powerful RAG system accessible even to non-developers. No custom backend coding or ML infrastructure is required — n8n orchestrates the entire workflow visually.
| Feature | Node Type |
|---|---|
| File Upload | n8n Form Trigger / Webhook |
| Text Extraction | File Read / PDF Extract (Community Node) |
| Embeddings | Google Gemini Embeddings Node |
| Vector Storage | Simple Vector Store (Core) |
| Chat Completion | Google Gemini Chat Node |
Tip: Install community nodes from:
Settings → Nodes → Install Community Node
first rag agent.jsonYour RAG Agent system is now ready.
Example queries:
“Summarize page 3.”
“List the important dates in the document.”
┌───────────────────┐
│ File Upload │
└─────────┬─────────┘
│ Extract Text
┌─────────▼─────────┐
│ Gemini Embeddings │
└─────────┬─────────┘
│ Store vectors
┌─────────▼─────────┐
│ Simple VectorStore │
└─────────┬─────────┘
│ Retrieve Relevant Chunks
┌─────────▼─────────┐
│ Gemini Chat Model │
└─────────┬─────────┘
│ Response
┌───▼───┐
│ User │
└──────┘
Chunking determines retrieval quality. Poor chunking = poor results.
| Parameter | Value |
|---|---|
| Chunk Size | 800–1,000 characters |
| Chunk Overlap | ~200 characters (≈20%) |
| Context Granularity | Paragraph-level chunks |
overlap = chunk_size * 0.20
The system uses two memory layers:
Gemini performs:
Testing with sample document: converted_text.pdf
| Metric | Result |
|---|---|
| Accuracy | Strong contextual extraction |
| Relevance | High-quality semantic chunk retrieval |
| Latency | Near real-time (<1s) responses |
| User Feedback | Intuitive and reliable conversational flow |
| Limitation | Vector store currently non-persistent |
| Query | System Response Summary |
|---|---|
| “What are the main topics?” | Summarized into key thematic sections |
| “Explain page 3.” | Retrieved relevant page content accurately |
| “List important dates.” | Extracted all date references with context |
The repository now includes:
✔ LICENSE (MIT)
✔ requirements.txt
✔ .gitignore with n8n patterns
✔ TECHNICAL_GUIDE.md
✔ ARCHITECTURE.md
✔ CHANGELOG.md
All files are structured for maintainability and enterprise-ready clarity.
This RAG workflow demonstrates how powerful AI-assisted document search can be achieved using pure no-code automation. The integration of n8n with Google Gemini enables organizations to convert their internal documents into a dynamic, conversational knowledge system without building complex infrastructure.