.png?Expires=1783136742&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=Q7CWn-2ZZDQO2WRSb9~W12aWcjnRq34bbwv7hAvMib4Sq0I6w9ATW0vuzxbDhbJC3vzBrW3dD6r0w20E3J9w2RFjskW-VXnlUOWlN4TWe9A46HwBv-yRjygbt-ojRCOdX7EK2QddiSV~wrLp0mlAa18kJiDUtxcEqNJSfzHgn84oIEg0ha0kx6H5dJQJvj8U3ucEqiQYvBHRwYc761tQJ76FOdW5-kCwhg6Wc4axLNSfj6TFfxgu4aSAX9x30Y4h0YkoiQ5p0BRFt9WDdYbqy5rvD4hPmFwj2APrkbHREBKYQN1a4RTWkbLv6eOX~r7IserB86AK1yDyT7lre6h7OQ__)
Built with LangGraph, integrated with Cohere LLM, MiniLM, and Qdrant vector database the system is designed to allow the intelligent, automated analysis of INGV seismic data. The goal is to enable agents to collaborate tra loro by analysing the datasets dei terremoti, processing, and enriching them to generate explanations, reports, and answers to questions about seismic phenomena.
This system is based on advanced multi-agent architectures:
cd quake-knowledge-graph
python -m venv venv
venv\Scripts\activate
pip install -r requirements.txt
Qdrant Cloud
DRANT_URL = http://localhost:6333
QDRANT_API_KEY = admin-key
QDRANT_COLLECTION = earthquake_events
EMBEDDING_DIM = 384
Cohere
COHERE_API_KEY=your_api_key
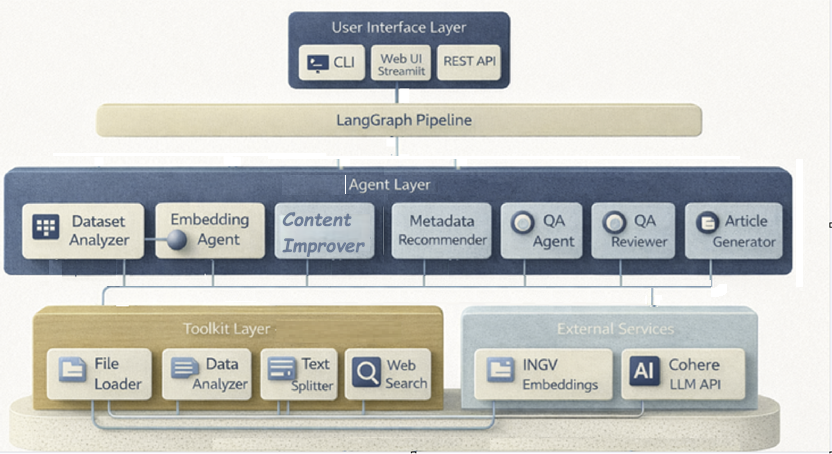
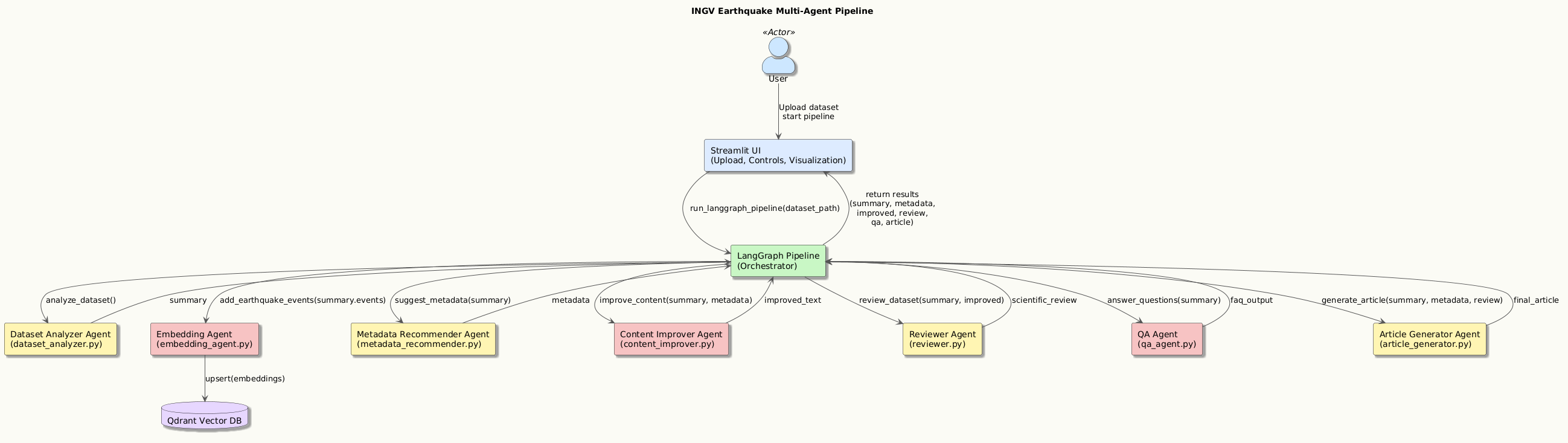
The Dataset Analyser Agent is the entry point of the entire seismological pipeline. It is responsible for examining an INGV dataset, managing both directories and ZIP archives, and automatically identifying the files in TXT format of the official seismic catalogues. Once the files have been extracted, the agent reads the contents line by line, recognises the standard INGV columns, and filters out invalid or incomplete rows. Transform each event into a structured record with geophysical fields, including magnitude, depth, coordinates, event type, and authorial metadata. During processing, it verifies data consistency and identifies anomalies. When finished, it produces a complete statistical summary, including the minimum, maximum, and average magnitude; min/max/avg depth; and the total number of valid events. It also returns the entire list of extracted events, the number of files processed, and the path of the normalised dataset. Its output becomes the solid foundation on which the other agents in the multi-agent pipeline are grafted.
The Embedding Agent is responsible for transforming each INGV seismic event into a semantic vector representation for intelligent search. Upon launch, the agent verifies that the Qdrant collection dedicated to events exists; if it does not, it automatically creates it with the correct carrier size. Each event is converted into short, informative text that summarises magnitude, location, depth, event type, and essential metadata. These texts are then processed locally through the MiniLM model of SentenceTransformers, a fast and effective solution even in an offline environment. The generated embeddings are grouped into small batches to avoid exceeding payload limits and optimise memory usage. Next, the agent constructs vector points complete with descriptive payloads and inserts them into Qdrant in controlled micro-batches. Once the collection is populated, the agent allows you to perform semantic searches of similar events, either based on another event or on a free-text query. This enables exploratory analysis, clustering, and intelligent queries on earthquake characteristics.
The Metadata Recommender Agent analyses the already processed seismic dataset and generates intelligent metadata that enriches the geophysical content provided by INGV. Starting from the list of events and the statistical values extracted from the Dataset Analyser, the agent builds a series of synthetic titles that best represent the extent and intensity of the seismic sequence. It then produces a one-sentence summary, useful for compact descriptions in reports or information systems. In parallel, it generates thematic tags based on magnitude, average depth, and characteristic locations such as Campi Flegrei, Etna, or the Apennines, allowing rapid classification of the dataset. The agent also elaborates reasoning, i.e., a textual explanation of the choices made and the seismological classification of the data. The goal is to provide a set of metadata that is clear, consistent, and immediately usable by Content Improver, Reviewer, and Article Generator in the multi-agent pipeline. In this way, the agent contributes to the scientific and narrative contextualization of seismic information.
The Content Improver Agent intervenes after the seismic dataset has been analysed and enriched with metadata, aiming to transform raw numbers and values into clear, readable, and technically accurate text. Starting from the statistical summary (min/max/average magnitude, min/max/average depth, number of events) and the metadata suggested by the Metadata Recommender, the agent builds a concise description that presents the entire dataset in a fluid, understandable way. It integrates the main information into a coherent paragraph, explaining the variability in magnitude, the distribution of hypocentral depths, and the geographical spread of the INGV-recorded events. The result is improved text that is ready to be used in reports, UI panels, or as the basis for the introductory section of the final seismological article. The agent also returns a summary of metadata usage and the number of events processed, enabling subsequent steps in the pipeline to track context.
The Reviewer Agent serves as the scientific validator for the entire INGV seismic dataset, assessing its quality, reliability, and completeness. After receiving the events processed by the Dataset Analyzer and any enhanced text from the Content Improver, it performs a series of structured checks to identify critical errors, missing fields, and inconsistencies in geophysical values. In particular, it analyses the presence of fundamental fields such as time of origin, coordinates, magnitude, and depth, verifying that they are always available and correctly formatted. It also identifies numerical anomalies such as out-of-range depth or unrealistic magnitude, and produces targeted alerts to be submitted to the user or to the next steps in the pipeline. In addition to checks, it calculates a dataset health score by penalising serious problems, warnings, and missing fields. The Reviewer also produces recommendations and potential improvement actions, ranks them by priority, and facilitates the dataset review. This assessment is the foundation for the QA Agent and for generating the final report.
The QA Agent is the agent dedicated to answering questions about INGV seismic data, integrating semantic search and LLM generation. When the agent receives a question from the user, it first performs a vector search in Qdrant using the Embedding Agent to identify the most relevant events based on the query's semantic content. Starting from the results, it builds a synthetic scientific context, reporting key information such as magnitude, depth, coordinates, location, and type of event for each event. This context is then transformed into a specialised geophysical prompt, designed to guide the LLM model towards precise answers consistent with real data. The agent then uses the Cohere model to generate a concise, scientific, evidence-based response from the dataset. The QA Agent thus allows you to query the entire seismic archive in natural language, obtaining explanations, summaries, and targeted information on the most significant events. It is a fundamental component to make the dataset searchable intelligently and immediately.
The Article Generator Agent is the component of the pipeline responsible for producing complete seismological articles, scientific reports, and other informative content based on INGV data. Use an advanced LLM model to transform the results generated by other agents — dataset analysis, metadata, reviews, and summaries — into structured, clear, publish-ready text. The agent receives context consisting of seismic statistics, magnitude ranges, spatial distributions, and any user inputs, such as requests for weekly reports or analysis of specific areas. Based on these elements, it builds a detailed prompt that guides the LLM model towards a formal and scientific style, dividing the content into coherent sections and subsections.
Unlike traditional monolithic seismic data pipelines, which combine parsing, analysis,
and reporting in a single workflow, this system adopts a modular multi-agent design.
Each agent is responsible for a specific cognitive task (analysis, validation, embedding,
reasoning), allowing independent evolution and substitution.
| Feature | Traditional Pipeline | This Multi-Agent System |
| --- | --- |
| Modular agents | ❌ | ✅ |
| Semantic search | ❌ | ✅ (Qdrant + MiniLM) |
| Human-in-the-loop Limited | ✅ | Explicit agents |
| Avg. dataset parsing | ~100–300 ms | 22 ms|
| Explainable reasoning | ❌ | ✅ Metadata + Reviewer |
| Component / Operation | Measured Value | Interpretation |
| --- | --- |
| Dataset Analysis | ~22 ms (mean) | Confirms highly optimised I/O and parsing logic for INGV TXT catalogues, enabling fast ingestion and interactive usage. |
| Embedding Generation | ~37 s (mean) | Expected computational cost due to MiniLM inference and batched Qdrant insertions executed in a virtualised Podman environment. |
| Metadata Recommendation | ~0 ms | Lightweight statistical processing implemented as pure functional transformations without heavy inference. |
| Content Improvement | ~0 ms |Text generation based on precomputed statistics and metadata, requiring negligible computation time. |
| Dataset Review | ~6 ms (mean) |Fast validation and consistency checks performed through deterministic rule-based analysis. |
| Vector Search (Qdrant) | ~3.3 s (mean) | Normal latency for semantic similarity search considering MiniLM inference and virtualised network overhead. |
| Peak Memory Usage (Embeddings) | < 11 MB | Demonstrates efficient memory footprint of MiniLM in CPU-only configuration. |
| Steady-State Memory Usage |~4 MB |Confirms low persistent RAM consumption once the pipeline is initialised. |
| Hardware Requirements | CPU-only | Suitable for edge or constrained environments without GPU acceleration. |
| Operation | Mean Time | Std Dev | P95 |
|---|---|---|---|
| Dataset Analysis | 0.0227 s | 0.0114 s | 0.0189 s |
| Embedding Generation | 37.52 s | 40.55 s | 18.34 s |
| Metadata Recommendation | 0.00028 s | 0.00015 s | 0.00024 s |
| Content Improver | 0.00002 s | 0.00001 s | 0.000015 s |
| Reviewer | 0.00615 s | 0.00138 s | 0.00616 s |
| Vector Search (Qdrant) | 3.30 s | 0.27 s | 3.57 s |
| Metric | Value | Comment |
|---|---|---|
| Dataset Memory (peak) | ~1.47 MB | Lightweight INGV TXT parsing |
| Embedding Memory (peak) | ~10.33 MB | Expected footprint for MiniLM (sentence-transformers) |
| Embedding Memory (current) | ~4.25 MB | Model in RAM without GPU overhead |
The INGV multi‑agent seismic analysis pipeline demonstrates robust performance and stable execution across all stages. Dataset parsing is extremely fast (22 ms on average), confirming that the INGV TXT loader is well-optimised for structured seismic catalogues. The most computationally expensive operation is embedding generation, which takes approximately 37 seconds due to the combination of MiniLM inference and Qdrant insertions running inside a Podman virtualised environment. Metadata generation, content improvement, and dataset review modules are highly efficient, with execution times close to zero, as they rely on lightweight transformations and statistical summarisation. Vector search operations in Qdrant average around 3.3 seconds, which is normal considering the overhead of MiniLM inference and the network path between the host and the Podman VM. Memory usage is stable and predictable, with MiniLM consuming roughly 10 MB peak RAM — consistent with CPU‑only sentence-transformers models.
python tools/benchmark_performance.py
Test LLM and embeddings
python tools/test_llm_embeddings.py
Test Qdrant integration
python tools/test_qdrant.py
{
"title_alternatives":[
0:"Seismic Activity Summary from INGV Records"
1:"INGV Earthquake Dataset Analysis"
2:"Seismic Events Report (M 0.3–1.7)"
]
"one_line_summary":"Dataset containing 6 INGV-recorded earthquakes, with magnitudes ranging from 0.3 to 1.7 (average 1.05)."
"tags":[
0:"microseismicity"
1:"intermediate-depth"
2:"geophysics"
3:"campi-flegrei"
4:"INGV"
5:"earthquake"
6:"seismic"
]
"reasoning":{
"magnitude_range":"Magnitude ranges from 0.3 to 1.7, avg 1.05."
"depth_range":"Depth ranges from 1.9 km to 24.5 km."
"classification_basis":"Tags and metadata are derived from earthquake intensity, depth category, and notable locations contained in the dataset."
}
}
{
"improved_text":"The dataset contains 6 analyzed seismic events. Earthquake magnitudes range from 0.3 to 1.7, with an average value of 1.02. Hypocentral depths span from 1.9 to 24.5 km (average: 11.35 km). The recorded events are distributed across multiple areas, showing spatial patterns and parameter variability consistent with typical regional micro‑seismic activity."
"metadata_used":{
"title_alternatives":[
0:"Seismic Activity Summary from INGV Records"
1:"INGV Earthquake Dataset Analysis"
2:"Seismic Events Report (M 0.3–1.7)"
]
"one_line_summary":"Dataset containing 6 INGV-recorded earthquakes, with magnitudes ranging from 0.3 to 1.7 (average 1.05)."
"tags":[
0:"microseismicity"
1:"intermediate-depth"
2:"geophysics"
3:"campi-flegrei"
4:"INGV"
5:"earthquake"
6:"seismic"
]
"reasoning":{
"magnitude_range":"Magnitude ranges from 0.3 to 1.7, avg 1.05."
"depth_range":"Depth ranges from 1.9 km to 24.5 km."
"classification_basis":"Tags and metadata are derived from earthquake intensity, depth category, and notable locations contained in the dataset."
}
}
"events_processed":6
}
{
"issues":[]
"recommendations":[]
"validation_results":{
"critical_issues":0
"warnings":0
"recommendations_count":0
"completeness":{
"EventID":true
"Time":true
"Latitude":true
"Longitude":true
"Magnitude":true
"Depth_Km":true
"Location":true
}
"overall_health":100
"numerical_anomalies":[]
"total_events":6
}
"action_items":[]
"priority_fixes":[
0:"Migliorare descrizioni località"
1:"Aggiungere metadati mancanti"
]
}
The modular agent-based design allows long-term maintainability.
Each agent encapsulates a specific responsibility and can be independently updated or replaced
without impacting the overall pipeline.
The text and images in this document were created with the support of Microsoft Copilot. The author, Rosaria Daniela Scattarella, transfers to Engineering Ingegneria Informatica S.p.A. all economic rights relating to such contents, including reproduction, modification, distribution, and commercial use. © 2026 Engineering Ingegneria Informatica S.p.A. – All rights reserved.
Built with: