This publication presents a comprehensive walkthrough for building an intelligent document question-answering system using a Retrieval-Augmented Generation (RAG) architecture. The project addresses the common challenge of efficiently extracting specific information from large, unstructured text documents. We detail an end-to-end implementation featuring a modern technology stack, including LangChain and LangGraph for pipeline orchestration, Google's Gemini models for advanced language processing, and FAISS for high-speed vector search. The resulting application is a command-line chatbot capable of holding a contextual conversation about the contents of a given PDF document. This work serves as both a practical guide for developers and a clear educational resource for those looking to understand the core components of RAG systems.
1. Introduction
1.1. Motivation and Problem Definition
In an era of information overload, manually searching for specific facts within lengthy documents like research papers, reports, or historical texts is inefficient and often impractical. Traditional keyword-based search systems may fail to capture the semantic nuance of a user's query, leading to irrelevant results. This project tackles this problem by building an intelligent chatbot that can "read" and "understand" a document, providing direct, contextual answers to natural language questions.
1.2. Objectives
The primary objectives of this project are:
To provide a clear, step-by-step implementation of a Retrieval-Augmented Generation (RAG) pipeline.
To demonstrate the use of Google's Gemini-Pro and embedding models within a Python application.
To illustrate how LangGraph can be used to construct robust, stateful AI workflows.
To produce a functional Q&A chatbot that can be adapted for various document-based tasks.
1.3. Intended Audience
This publication is intended for AI/ML students, developers, and researchers who have a foundational understanding of Python and are interested in learning about or building practical Large Language Model (LLM) applications. It is designed to be a hands-on guide for implementing RAG systems from the ground up.
2. Methodology and System Architecture
The core of this project is a RAG pipeline orchestrated as a stateful graph. This architecture ensures that each step in the query process is modular and logically connected.
2.1. System Architecture
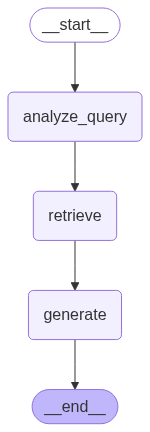
The workflow of the RAG system is described as follows:
Load & Split: The system loads a PDF document and splits it into smaller, manageable text chunks.
Embed & Store: It uses an embedding model to convert these text chunks into vectors and stores them in a FAISS Vector Store.
User Question: The user inputs a question.
Query Analysis: An LLM analyzes the question to optimize the search query.
Retrieve: The system searches for and retrieves the most relevant text chunks from the Vector Store (FAISS).
Generate: The LLM receives the original question and the retrieved context to generate the final, comprehensive answer.
Workflow answers user questions like this:
2.2. Data Ingestion and Processing
The foundation of any RAG system is its knowledge base. The data pipeline is implemented in create_vector_store.py and involves the following steps:
PDF Loading: The source document is loaded using the PyPDFLoader library.
Text Splitting: To fit within the context window of the language model, the document is split into smaller, overlapping chunks of approximately 1000 characters using RecursiveCharacterTextSplitter.
Metadata Enrichment: Each chunk is enriched with metadata. Specifically, its page number and its relative position in the document (e.g., "beginning", "middle", "end") are recorded. This allows for more sophisticated, filtered retrieval later on.
Embedding Generation: Each text chunk is converted into a numerical vector (embedding) using Google's text-embedding-001 model. This vector represents the semantic meaning of the chunk.
Vector Storage: The generated embeddings and their corresponding text chunks are stored in a FAISS (Facebook AI Similarity Search) index, which allows for extremely fast and efficient similarity searches.
2.3. Comparative Analysis of Vector Databases and Embedding Models
Vector Database Comparison
FAISS (Facebook AI Similarity Search):
Advantages:
Open-source and free, developed by Facebook AI Research.
Extremely high performance for vector similarity search on both CPU and GPU.
Supports various indexing algorithms (Flat, IVF, HNSW, PQ, etc.), suitable for both small and large datasets.
Easy integration with Python projects, large community, and comprehensive documentation.
Limitations:
Does not natively support distributed or scale-out deployments like Pinecone or Milvus.
Lacks a web management interface; mainly operated via code.
Does not provide built-in features for security, multi-tenancy, or backup as some cloud services do.
Comparison with other options:
Pinecone: Cloud service, easy to scale, strong API, but incurs costs and relies on a third party.
Milvus: Open-source, supports distributed deployment, powerful for big data, but more complex to set up than FAISS.
ChromaDB, Weaviate: User-friendly, REST API support, suitable for small to medium applications, but may not match FAISS in performance for large-scale data.
Why FAISS was chosen:
For this project, which primarily runs locally with a moderate dataset size, FAISS offers optimal performance, easy Python integration, and cost-effectiveness, making it a practical and efficient choice.
Embedding Model Comparison
Gemini "models/embedding-001":
Advantages:
Developed by Google, optimized for semantic search and RAG applications.
Strong contextual understanding, produces high-quality embeddings for both short and long texts.
Easy integration via Google AI Studio API, supports multiple languages.
Outperforms many open-source models (such as Sentence Transformers) in recent benchmarks.
Limitations:
Requires an API key and depends on Google’s service, which may incur costs for heavy usage.
Not open-source, so less customizable than local models.
Comparison with other options:
OpenAI Embedding (text-embedding-ada-002): High quality and popular, but also requires an API key and has associated costs.
Sentence Transformers (SBERT): Open-source, runs locally and free, but sometimes lags behind large models from Google/OpenAI in contextual understanding and embedding quality.
Cohere, HuggingFace models: Diverse options, both free and paid, but quality and speed may not be as consistent as Gemini.
Why Gemini "models/embedding-001" was chosen:
Gemini embeddings provide excellent vector quality, are easy to integrate into Python pipelines, and are optimized for semantic search and RAG, leveraging the latest advancements from Google AI.
Summary:
The combination of FAISS and Gemini embeddings enables the system to achieve high performance, easy deployment, reasonable cost, and ensures the best possible answer quality for users.
2.4. Query Processing Pipeline
The query-response cycle is managed by a StateGraph from LangGraph, as defined in main.py.
Query Analysis: When a user poses a question, it first passes to an "analyze_query" node. Here, an LLM call is made to rephrase the user's question into an optimal search query and to identify if the user is asking about a specific part of the document (e.g., "in the beginning...").
Document Retrieval: The optimized query is used to search the FAISS vector store. The system retrieves the top 'k' most semantically similar chunks of text. If the previous step identified a specific section, the search is filtered to only that part of the document, increasing relevance.
Answer Generation: The retrieved text chunks (the context) and the original user question are passed to the final "generate" node. The Gemini model synthesizes this information to produce a final, human-readable answer, grounded in the document's content.
3. Implementation and Usage Guide
3.1. Dataset
The knowledge base for this demonstration is the data/Vietnam_War.pdf document.
Content: A 28-page document detailing the events, figures, and timeline of the conflict.
Statistics: The document is split into 128 text chunks for processing.
3.2. Installation and Execution
Prerequisites:
Python 3.9+
Git
Steps:
Clone the repository:
git clone https://github.com/phanminhtai23/VietnamWarQA-RAG.git
cd VietnamWarQA-RAG
Install dependencies from requirements.txt:
pip install -r requirements.txt
Configure API Key:
Create a .env file in the project's root directory and add your Google AI Studio API key:
GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY"
Run the Application:
Execute the main script. The vector store will be created on the first run.
python main.py
4. Discussion
4.1. Limitations
While effective, the current system has several limitations:
Single-Document Scope: The knowledge is strictly confined to the single PDF provided.
Language Specificity: Performance is optimized for English queries and documents.
Retrieval Dependency: The final answer quality is highly contingent on retrieving the correct context. If the retriever fails, the generator cannot produce an accurate answer.
Static Knowledge: The knowledge base does not update automatically and requires reprocessing the source document.
4.2. Future Work
Potential enhancements for this project include:
Multi-Document Integration: Extending the system to query across a corpus of multiple documents.
Web Interface: Developing a graphical user interface (GUI) using a framework like Streamlit or FastAPI for improved user experience.
Advanced Retrieval Strategies: Implementing more sophisticated retrieval techniques, such as HyDE (Hypothetical Document Embeddings) or RAG-Fusion, to enhance context relevance.
Automated Evaluation: Integrating frameworks like RAGAs to quantitatively measure and track the performance of the RAG pipeline.
5. Conclusion
This project successfully demonstrates the construction of a powerful, RAG-based Q&A system. It provides a clear and practical blueprint for developers, showcasing how to leverage modern AI tools to unlock the knowledge contained within unstructured documents. The modular architecture using LangGraph ensures that the system is not only functional but also extensible for more advanced applications in the future.