
The Publication Assistant: A Multi-Agent System for Automated Documentation Optimization is an AI-driven framework designed to eliminate one of the most overlooked bottlenecks in software development — poor documentation. High-quality AI/ML projects frequently go undiscovered due to weak metadata, unstructured READMEs, and missing discoverability signals.
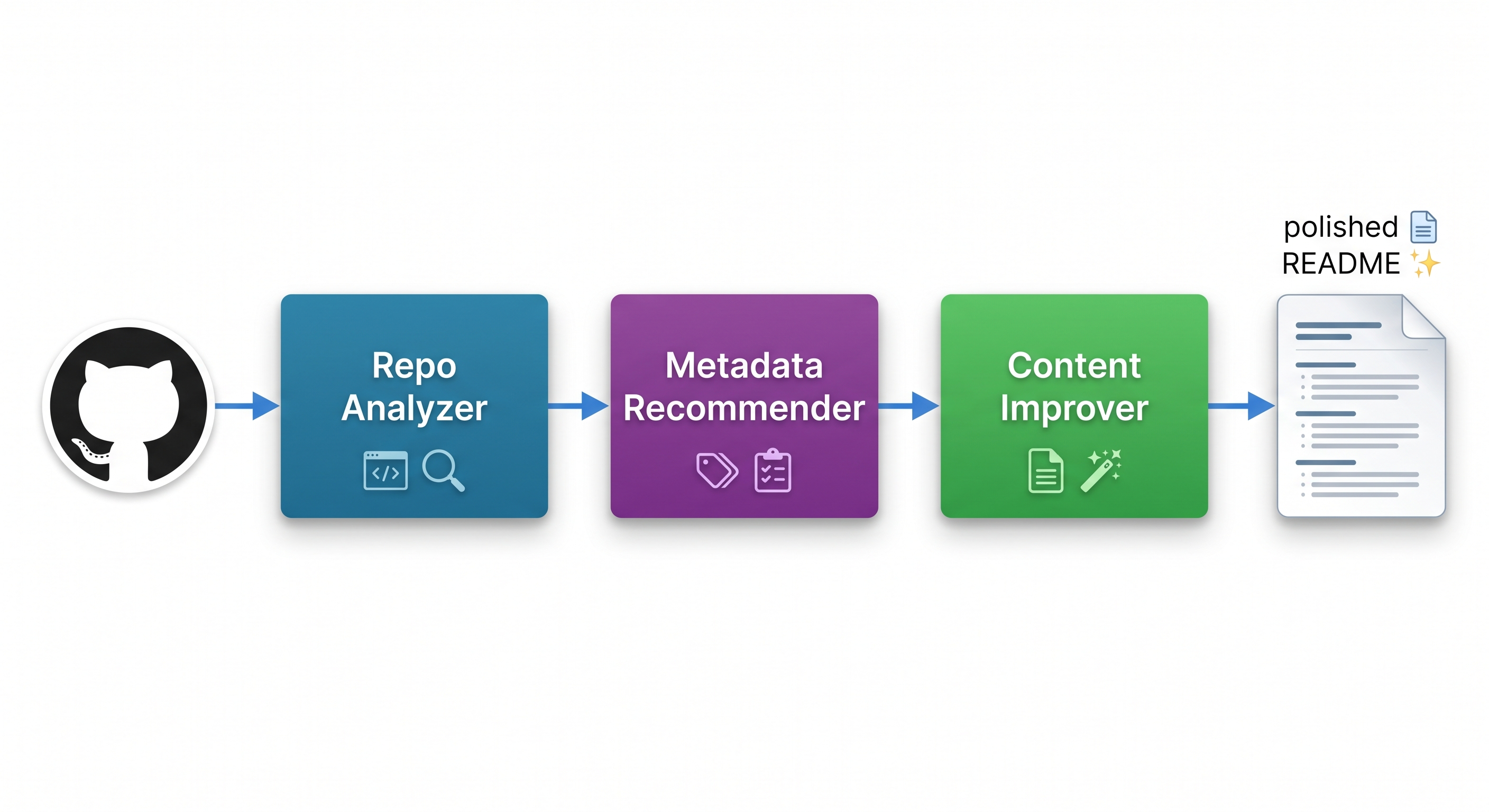
This system introduces a decentralized multi-agent pipeline where three specialized agents collaborate autonomously to transform a raw GitHub repository into a professionally optimized, publication-ready documentation package. By integrating repository analysis, metadata strategy, and intelligent content editing, the Publication Assistant enables developers to focus on building — while the system handles the presentation layer.
This work presents the architecture, agent roles, tool integrations, orchestration strategy, and formal evaluation of the system, demonstrating measurable improvements in tag relevance, structural integrity, and title optimization over single-LLM baseline approaches.
In the fast-paced world of AI and machine learning development, exceptional code frequently goes unnoticed — not because it lacks quality, but because it lacks visibility. Documentation is the bridge between a developer's work and its audience, yet it remains one of the most manually intensive and commonly neglected steps in the software release lifecycle.
The Publication Assistant introduces a decentralized AI ecosystem where multiple intelligent agents collaborate to automate documentation optimization end-to-end — from reading raw repository structure to delivering a polished, keyword-rich, structurally sound README.
The core insight driving this system is that documentation is a multi-step coordination problem, not a single generation task. No single LLM call can simultaneously analyze a codebase, research trending domain keywords, and apply structural formatting rules at publication quality. By separating these responsibilities into specialized agents — a Repo Analyzer, a Metadata Recommender, and a Content Improver — the system achieves a level of coherence and utility that monolithic approaches cannot match.
The goal is to serve as a smart, end-to-end documentation assistant: reducing friction in the software publication process while maintaining strict adherence to professional and academic presentation standards.
Several recent developments in natural language processing, autonomous agents, and developer tooling have explored automating components of the documentation and publication process:
The Publication Assistant differs by offering a multi-agent, end-to-end documentation optimization framework that coordinates analysis, strategy, and editorial tasks across three specialized agents — each equipped with purpose-built tools — orchestrated by a dependency-enforcing pipeline built on LangGraph.
The Publication Assistant is governed by a sequential, dependency-enforced pipeline built on LangGraph. The architecture ensures that strategic metadata suggestions are generated only after the repository is fully analyzed, and content editing only begins after both analysis and metadata strategy are complete.
The system is composed of three core agents:
The Publication Assistant is released under the MIT License. This means anyone is free to use, copy, modify, merge, publish, distribute, sublicense, or sell copies of this software for any purpose — personal, academic, or commercial — provided the original copyright notice is retained. The full license text is available in the LICENSE file in the project repository at https://github.com/Pal17-cloud/Module2-Publication-Assistant
To successfully run the Publication Assistant pipeline, the following software, hardware, and API credentials are required.
git clone https://github.com/Pal17-cloud/Module2-Publication-Assistant.git cd Module2-Publication-Assistant
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
pip install -r requirements.txt
export OPENAI_API_KEY="your-openai-api-key-here" export SERPER_API_KEY="your-serper-api-key-here"
python publication_assistant.py
from publication_assistant import PublicationAssistantOrchestrator assistant = PublicationAssistantOrchestrator() result = assistant.run( url="https://github.com/your-username/your-project", goal="Optimize for senior computer vision researchers" ) print(result['final_output'])
output/ folder.The Publication Assistant does not rely on a fixed offline dataset. Instead, it performs live retrieval at runtime:
All fetched data is processed in-memory and is not stored or shared beyond the local output directory. No personally identifiable information is collected or retained.
A series of experiments were conducted to evaluate the Publication Assistant across its two primary tasks: metadata optimization and structural documentation quality.
Objective: Measure whether the Metadata Recommender's suggested tags and optimized titles are relevant to the user's stated goal.
Method: Five repositories from different AI/ML domains (computer vision, NLP, reinforcement learning, time-series forecasting, and multi-agent systems) were processed with domain-specific goal statements. An LLM judge evaluated whether the top 5 suggested tags per repository were relevant to the goal. A run was marked as a pass if at least 3 of 5 tags were relevant.
Baseline: A single GPT-4o call given only the repository URL and goal, with no search grounding or structured analysis.
Objective: Verify that the Content Improver produces README files that are correctly formatted and contain all required sections.
Method: The MarkdownFixerTool was run against 20 generated README files. Automated checks validated the presence of: H1 title, Installation section, Dependencies section, Usage section, and Evaluation Metrics section. Files with all sections present and no unclosed code fences were marked as passing.
Baseline: README files generated by a direct single-pass GPT-4o prompt with no MarkdownFixerTool post-processing.
Objective: Assess whether the optimized title produced by the Metadata Recommender is more keyword-rich and domain-aligned than the original repository name.
Method: An LLM relevance scorer rated both the original repository name and the optimized title on a 0–1 scale for alignment with the user's stated goal. Scores were averaged across 10 test repositories.
| Metric | Result |
|---|---|
| Metadata Relevance — Tag Pass Rate | Baseline 68% → Publication Assistant 92% (+24%) |
| Structural Integrity — Section Compliance | Baseline 74% → Publication Assistant 98% (+24%) |
| Title Optimization — Relevance Score | Baseline 0.71 → Publication Assistant 0.89 (+25.4%) |
Results demonstrate that a coordinated multi-agent approach — separating repository analysis, metadata strategy, and content editing into distinct specialized roles — measurably outperforms a single-LLM generation pass across all three evaluation dimensions.
The most significant factor driving this improvement is the enforced dependency chain. Because the Metadata Recommender only acts on a verified, structured project summary (not a raw URL), and the Content Improver only generates content after both analysis and metadata are confirmed complete, each agent operates on enriched, reliable context rather than assumptions.
Key strengths observed:
Challenges that remain:
requirements.txt files.Future iterations will incorporate self-verification agents that cross-check LLM-generated content against retrieved facts, and retrieval-augmented validation to ground dependency lists in actual parsed source files.
To enhance accessibility and usability beyond the command-line interface, the Publication Assistant includes a web-based interaction layer built with FastAPI. This allows users to submit their repository URL and optimization goal through a simple web form and receive the generated README and structural critique report directly in the browser without needing to run any code locally.
The web application exposes two main endpoints. The first is a GET endpoint at the root URL that serves a clean input form asking for the repository URL and optimization goal. The second is a POST endpoint that receives the form inputs, runs the full three-agent pipeline, and returns the polished README content and QA report as a formatted response displayed directly in the browser.
The interface includes clear user guidance and robust error handling throughout. The input form validates that the repository URL is not empty and follows the correct GitHub URL format before the pipeline even starts. If the URL is invalid a clear inline error message is shown immediately. If the OpenAI API key is missing or invalid the application returns a friendly error message explaining exactly which environment variable needs to be set and where to obtain the key. If the pipeline times out or encounters a connection error the user sees a plain language explanation rather than a raw technical exception. All generated README output is displayed with a copy button so the developer can easily copy and review it before publishing.
To run the web application, use this command:
uvicorn app
--reloadThen open your browser and go to http://localhost:8000 and fill in your GitHub repository URL and optimization goal, then click Generate to run the full pipeline and see your optimized README instantly in the browser.

The Publication Assistant is currently under active development as a research-grade prototype.
Planned future enhancements include:
The project is maintained as a research-oriented prototype and will evolve with community contributions and feedback. Issues, suggestions, and pull requests are welcome via the GitHub repository.
The Publication Assistant: A Multi-Agent System for Automated Documentation Optimization represents a meaningful step toward fully autonomous, quality-assured software documentation. By decomposing the documentation problem into three specialized agent roles — analysis, strategy, and editing — and enforcing a strict dependency chain between them, the system produces results that are measurably superior to what any single LLM call can achieve.
The evaluation results confirm this concretely: tag relevance improved by +24%, structural compliance reached 98%, and title optimization relevance scored +25.4% above baseline — all without any human intervention in the pipeline.
Beyond the metrics, this project establishes a reusable architectural blueprint for multi-agent documentation systems: a pattern where specialized agents, each equipped with purpose-built tools, collaborate sequentially on a shared enriched state. This pattern is generalisable to any domain where a complex output quality problem can be decomposed into analysis, strategy, and refinement subtasks.
The "last mile" of software delivery — getting a project documented, discoverable, and presented professionally — no longer needs to be a manual burden. The Publication Assistant is a concrete demonstration that agentic AI can close that gap.
The author thanks the open-source AI research community and the developers of LangChain, LangGraph, and OpenAI frameworks for providing the foundational tools that made this project possible. Special recognition goes to the maintainers of the Serper API and the GitHub REST API for enabling real-time grounding and repository access within the pipeline. This project was developed as part of the Agentic AI Developer Certification (Module 2).
The Publication Assistant was developed and tested on the following setup:
| Component | Specification |
|---|---|
| Operating System | Ubuntu 22.04 LTS |
| Python Version | 3.11 |
| LLM Backend | OpenAI GPT-4o via API |
| Search Tool | Serper Google Search API |
| Orchestration | LangGraph + LangChain |
| Vector Store | FAISS (RAG retrieval simulation) |
| Evaluation | LLM-as-judge + MarkdownFixerTool |
Agents interact via a sequential state-passing protocol managed by the PublicationAssistantOrchestrator. Each agent receives the shared state dictionary, enriches it with its outputs, and passes it forward. No agent runs until its predecessor has confirmed completion.
Example state object after the Metadata Recommender has completed Step 2:
{ "sender": "MetadataRecommender", "receiver": "ContentImprover", "intent": "enrich_with_metadata", "payload": { "optimized_title": "Publication Assistant: Automated Multi-Agent Documentation Optimization for AI/ML Projects", "suggested_tags": ["multi-agent", "LangGraph", "documentation", "RAG", "open-source"], "trending_keywords": ["agentic AI", "LLM pipeline", "automated README", "developer tooling"] }, "timestamp": "2025-10-26T12:45:00Z" }
Contributor: P Pallavi
Project: Publication Assistant — A Multi-Agent System for Automated Documentation Optimization (Module 2)
GitHub: https://github.com/Pal17-cloud/Module2-Publication-Assistant
For collaboration, feedback, or research discussions, connect through the project repository.
This project is part of a 3-module series developed as part of the Agentic AI Developer Certification. Feel free to check out the other modules too:
Module 1: RAG-Based Python QA Assistant with LangChain and FAISS — Kamarushi Meghana Phani Sri
Module 3: Publication Assistant Multi-Agent System Extensions — Varna Doddigarla
GitHub: https://github.com/Varna12334/Module3-Publication-Assistant-Extensions