This RAG assistant demonstrates secure, privacy-preserving retrieval and generation on academic publications about Agentic AI.
It preserves context with chunk overlap, prevents hallucinations, enforces GDPR/HIPAA compliance, and produces reliable, document-grounded answers.
This project presents a Retrieval-Augmented Generation (RAG) assistant with a dedicated focus on privacy and security in Agentic AI systems. Unlike general-purpose RAG pipelines, this assistant is designed to operate within a controlled knowledge base and enforce strict safeguards against hallucinations, data leakage, and unauthorized information disclosure.
To achieve this, the system employs document chunking with overlap to preserve context across text boundaries, integrates Groq LLM for efficient and reliable inference, and enforces privacy-aware prompt construction. The assistant demonstrates how secure RAG design can help researchers and developers explore privacy and security threats in AI while ensuring compliance with regulatory standards and safe handling of sensitive information.
The RAG assistant is built as a structured pipeline designed to ensure both accurate retrieval and privacy-preserving response generation. Unlike a simple setup where documents are directly fed into an LLM, this system divides the process into multiple stages, each with a clear purpose related to context preservation, security, and compliance.
The first stage, data ingestion, involves loading the target publication (Privacy and Security in RAG) into a vector database. Before storing the text, it is split into chunks of 500 tokens with an overlap of 100 tokens. This overlap is crucial for preserving context that might otherwise be lost between consecutive chunks, ensuring that the assistant can generate coherent answers even when relevant information spans multiple sections of a document.
Once the documents are ingested, user queries are processed through the embedding and retrieval stage. Each query is converted into a vector embedding and compared against the stored document chunks. Only the most contextually relevant chunks are retrieved based on a similarity threshold. This step minimizes irrelevant results and ensures that the assistant’s answers are grounded in the source material.
Following retrieval, a structured prompt is constructed for the Groq LLM. The prompt combines the retrieved chunks with carefully defined instructions regarding security, privacy, and style. By explicitly defining these constraints, the assistant is guided to generate responses that are accurate, context-aware, and compliant with privacy guidelines.
During the LLM response stage, the Groq LLM produces answers strictly based on the retrieved content. The system formats the output in Markdown, supporting structured lists or bullet points where necessary to enhance readability. At the same time, it strictly enforces rules to prevent hallucinations or unsupported claims.
Finally, the assistant incorporates multiple privacy and security constraints to ensure safe usage. It refuses to answer queries unrelated to the available documents, avoids hallucinations, and applies compliance measures aligned with regulations such as GDPR and HIPAA. These safeguards make the system suitable for research into sensitive areas like privacy and security in Agentic AI.
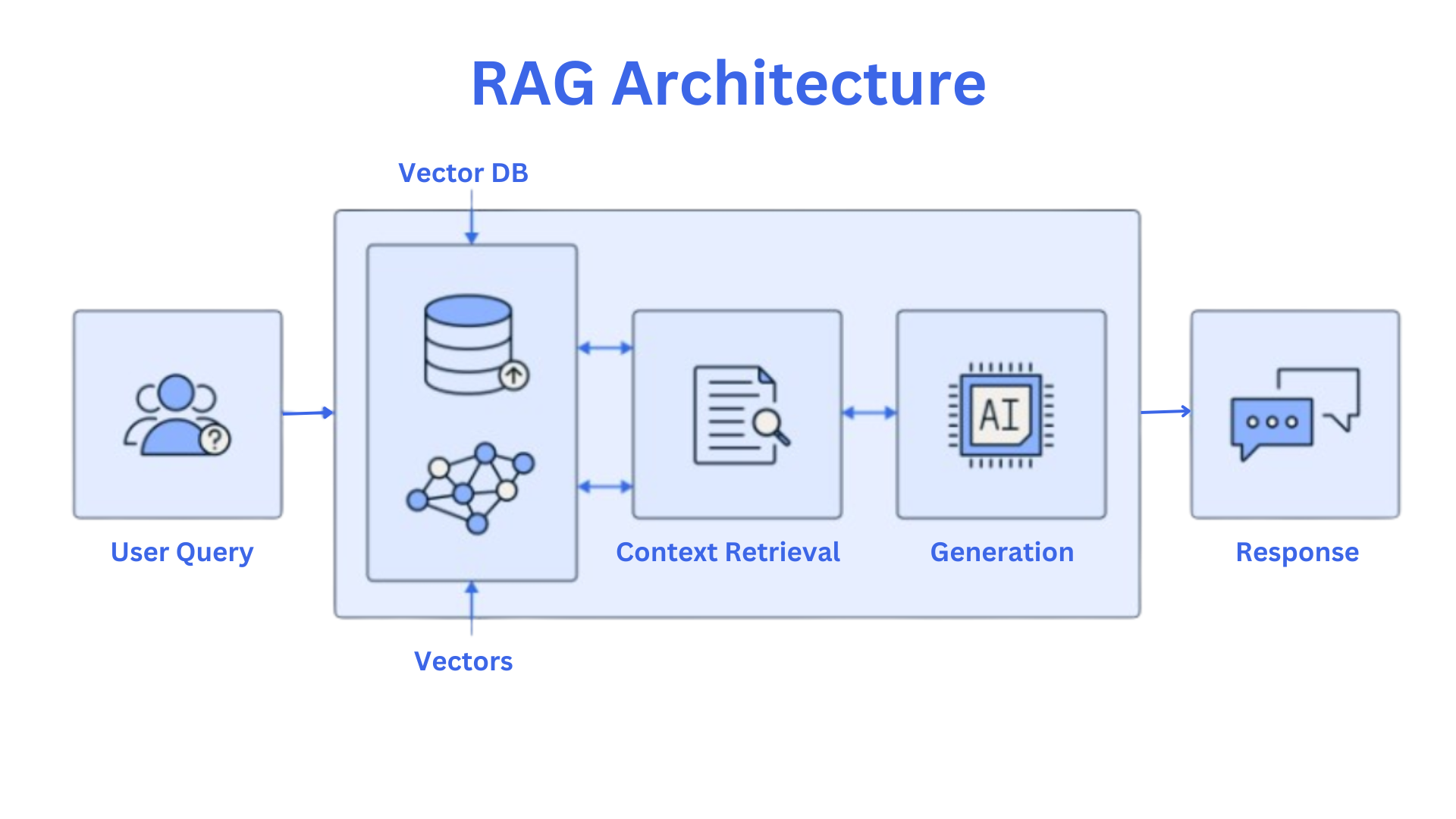
Figure 1: The RAG pipeline illustrates the flow from user query to retrieval, prompt construction, LLM processing, and secure answer generation.
The RAG assistant was evaluated on a set of queries designed to test both retrieval accuracy and privacy/security constraints. The results demonstrate that the system is able to provide relevant, document-grounded answers while refusing or limiting responses when the required information is not present in the source text.
Q1: What is this publication about?
The assistant correctly identified the scope of the publication.
A:
The work focuses on privacy and security concerns in RAG environments, emphasizing confidentiality, integrity of data, secure storage, protection against unauthorized access, and compliance with regulations.
Q2: What tools are used?
When no relevant details were present in the source, the assistant did not hallucinate an answer.
A:
The provided document chunks did not mention any specific tools.
Q3: What will be used as input data?
A:
Q4: How do you ensure your AI system is fair?
This query checks for refusal behavior when fairness is not addressed in the source.
A:
The publication does not mention fairness explicitly. It primarily discusses latency and accuracy trade-offs, without detailing fairness considerations.
Q5: How do you keep your AI system secure?
Here the assistant synthesized best practices drawn directly from the text.
A:
Security is ensured by applying robust security frameworks, access controls, encryption, regulatory compliance (e.g., GDPR, HIPAA), and by educating developers and users about security risks.
Q6: What must you tell data subjects?
A:
The assistant correctly listed obligations under GDPR and related regulations, including:
Q7: How do you ensure data subject rights?
A:
Through layered security (access controls, encryption, monitoring), regular assessments, compliance with external services, and proactive safeguards against misuse.
