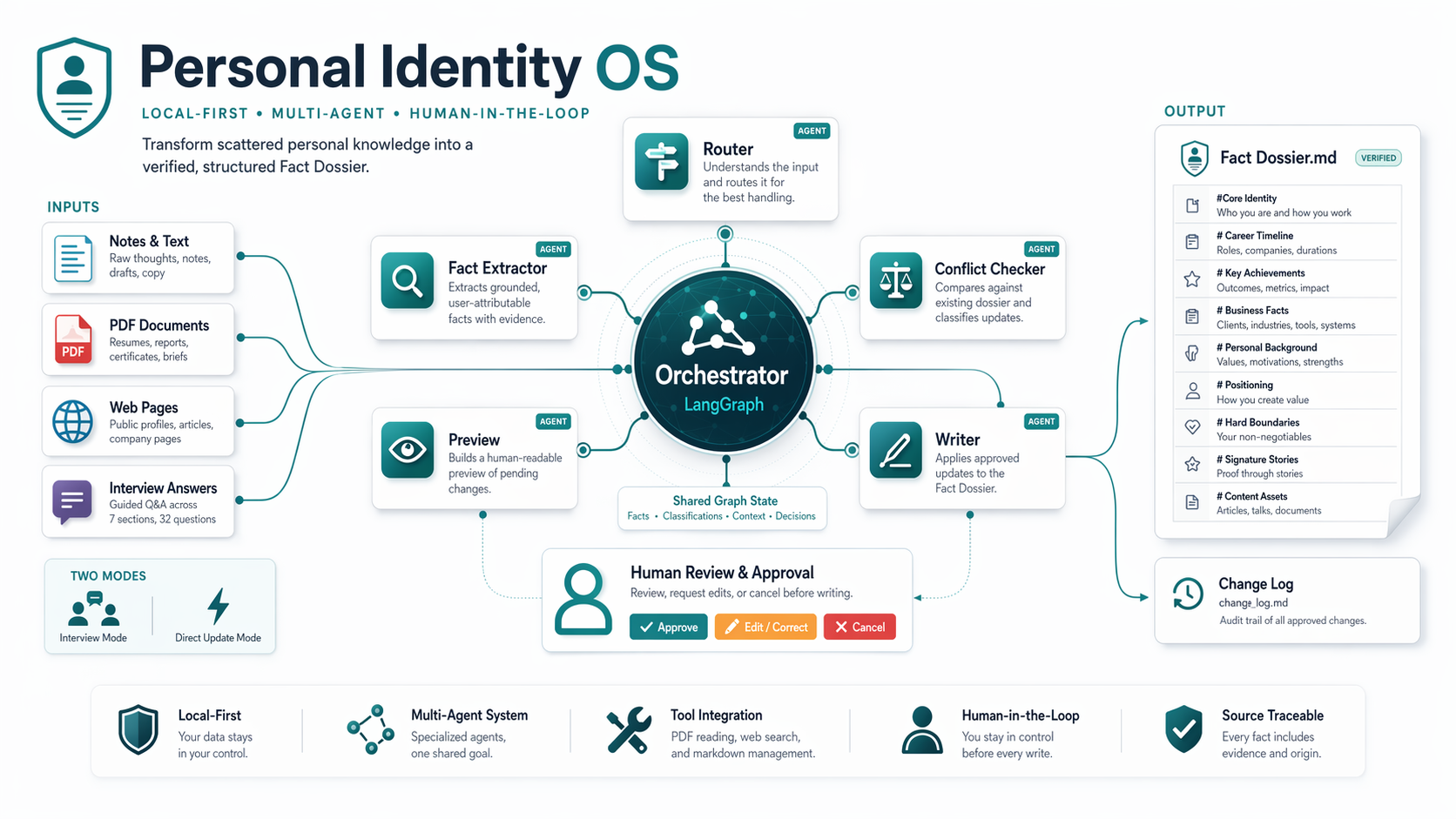
Personal Identity OS is a local-first multi-agent system built with LangGraph. It helps a user turn raw personal inputs such as notes, public URLs, and PDFs into a structured Fact Dossier.md that can be reviewed before it is written to disk.
The project was built as a capstone submission for the Ready Tensor Multi-Agent System program. Its goal is to demonstrate practical multi-agent collaboration, tool integration, orchestration with LangGraph, and human-in-the-loop review in a workflow that solves a real documentation problem: turning scattered professional information into a grounded and reusable profile.
GitHub repository: https://github.com/Zegor88/identity-os
Professionals often have their career facts spread across CVs, PDFs, websites, notes, and memory. Turning that material into a clean and trustworthy profile is harder than it looks.
A single prompt is usually not enough for this task because the workflow requires several different behaviors:
This is exactly the kind of problem that benefits from a modular multi-agent design rather than a one-shot generation flow.
The system addresses a practical problem:
How can we convert unstructured personal and professional source material into a reusable, source-grounded fact dossier without blindly trusting a single LLM pass?
The project focuses on three requirements:
Personal Identity OS supports two working modes:
In both modes, the workflow ends with a preview and a human approval gate before the dossier is updated.
Generated artifacts:
output/Fact Dossier.mdoutput/change_log.mdThe system is orchestrated with LangGraph. Each node has a distinct responsibility and collaborates through shared graph state.
graph TD User[User] CLI[CLI] Graph[LangGraph Orchestrator] Sources[Text / URL / PDF] Interview[Interview Flow] Direct[Direct Update Flow] Extract[Fact Extraction] Check[Conflict Checking] Preview[Preview + Approval] Dossier[(Fact Dossier.md)] subgraph Tools[Custom Tools] PDF[pdf_reader] WEB[web_search] MD[md_manager] end User --> CLI CLI --> Graph User --> Sources Graph -->|interview mode| Interview Graph -->|direct mode| Direct Sources --> Direct Interview --> Extract Direct --> Extract Extract --> Check Check --> Preview Preview --> Dossier Sources -.-> PDF Sources -.-> WEB Preview -. read/write .-> MD
flowchart TD Entry[entry] Entry -->|mode=direct| Ingestion[ingestion] Entry -->|mode=interview| IQ[interview_question] IQ --> IP[interview_progress] IP -->|more questions| IQ IP -->|section complete| ISR[interview_section_review] ISR --> IA[interview_apply] IA --> Ingestion Ingestion --> FE[fact_extractor] FE --> CC[conflict_checker] CC --> PP[prepare_preview] PP --> AP[approval] AP -->|approve| WR[write] AP -->|edit| FE AP -->|cancel| End1((END)) WR -->|direct| End2((END)) WR -->|interview| ADV[interview_advance] ADV -->|next section| IQ ADV -->|complete| End3((END))
This project satisfies the capstone requirement of using at least three agents with distinct responsibilities. In practice, it uses several specialized graph nodes:
| Agent / Node | Responsibility |
|---|---|
Router / Ingestion | Normalizes raw text, URL, or PDF input into graph-ready text |
Fact Extractor | Extracts grounded professional facts into structured state |
Conflict Checker | Compares new facts to the current dossier and classifies them |
Prepare Preview | Builds the human-readable preview shown before writing |
Markdown Writer | Rewrites the dossier using approved updates |
Interview Question | Asks the next question during interview mode |
Section Review | Summarizes a completed interview section and asks for missing details |
Interview Apply / Advance | Converts interview answers into graph input and moves to the next section |
The key point is not just the number of nodes, but the separation of concerns: extraction, checking, summarization, approval, and writing are handled independently rather than collapsed into one model invocation.
The project also satisfies the capstone requirement of integrating at least three tools beyond basic LLM responses.
| Tool | Purpose | Why it matters |
|---|---|---|
tools/pdf_reader.py | Extracts text from local PDF files using PyMuPDF | Extends the system to work with document inputs rather than plain prompts |
tools/web_search.py | Fetches public web page content through Firecrawl | Allows ingestion of external web sources |
tools/md_manager.py | Handles markdown reads, writes, template lookup, and output paths | Separates file lifecycle management from agent logic |
These tools give the system real I/O behavior and make the pipeline useful beyond pure text completion.
One of the most important design choices in this project is the explicit approval gate before writing to disk.
After extraction and conflict checking, the system shows the user a preview of the pending facts. At that point, the user can:
This keeps the workflow grounded and reduces the risk of silently writing incorrect facts into the dossier.
The user provides:
The graph then runs:
entry -> ingestion -> fact_extractor -> conflict_checker -> prepare_preview -> approval -> write
The user launches the CLI with no argument. The graph then runs a 32-question interview across these seven sections:
Each completed section is summarized, optionally extended by the user, and then processed through the same extraction and approval pipeline before the interview advances.
The structured graph state includes:
has_facts, is_ambiguous, justification)section, label, value, and source_excerptDuplicateContradictionEnrichmentNovelThis design gives the workflow a clear internal contract and makes it easier to reason about how information moves through the system.
git clone https://github.com/Zegor88/identity-os.git cd identity-os python3.10 -m venv .venv source .venv/bin/activate pip install -r requirements.txt cp .env_example .env
Required environment variables:
GOOGLE_API_KEYFIRECRAWL_API_KEY for URL ingestionpython run_graph.py
python run_graph.py "From 2022 to 2024 I led analytics automation for 14 markets." python run_graph.py "https://example.com/about-me" python run_graph.py "/absolute/path/to/profile.pdf"
Several practical design choices shaped the final system:
This is a working capstone project, not a polished production platform. Current limitations include:
I state these limits explicitly because Ready Tensor evaluation emphasizes technical honesty and verifiable claims.
From a capstone perspective, the project demonstrates:
This project is a good fit for the Mastering AI Agents capstone because it solves a real workflow problem that is hard to address with a single prompt. It requires routing, structured extraction, consistency checking, staged review, and controlled writing. Those responsibilities are distributed across multiple cooperating agents and tools, with LangGraph coordinating the overall flow.
In other words, the system is not “multi-agent” in name only. The decomposition is central to how the project works.
If I continue this project, the next improvements would be:
Personal Identity OS is a practical example of a local-first multi-agent pipeline that turns scattered professional inputs into a reviewed fact dossier. The project combines orchestration, tool use, human review, and structured writing into one coherent LangGraph workflow. It is designed to be understandable, runnable, and evaluable as a Ready Tensor capstone submission.
