
Abstract
The OCR Book dataset is a simple tool designed to read screenshots of book pages and extract text content to be incorporated into a dataset. The aim was to automate the manual note-taking process and implement an interface that allows users to select book extracts for saving.
Introduction
Having always loved reading, as the years went by, I gradually accumulated numerous handwritten notes of extracts from my readings. Whenever I wanted to refresh my memory and the opportunity arose, I would pull out the relevant book along with the snippets of notes containing the passages I had set aside.

I initially developed a simple prototype using a web framework that enabled me to manually fetch my notes into the app, facilitating easier access and consolidation of all the information in one place. However, the manual entry of each excerpt remained a lengthy and tedious process, and due to time constraints, I eventually set it aside.
Earlier this year, as I sought to gain experience with C++ and the Qt Framework , the project took on a new direction. I had the idea to implement an OCR system that could automate the process of manually fetching my dataset.
How it works
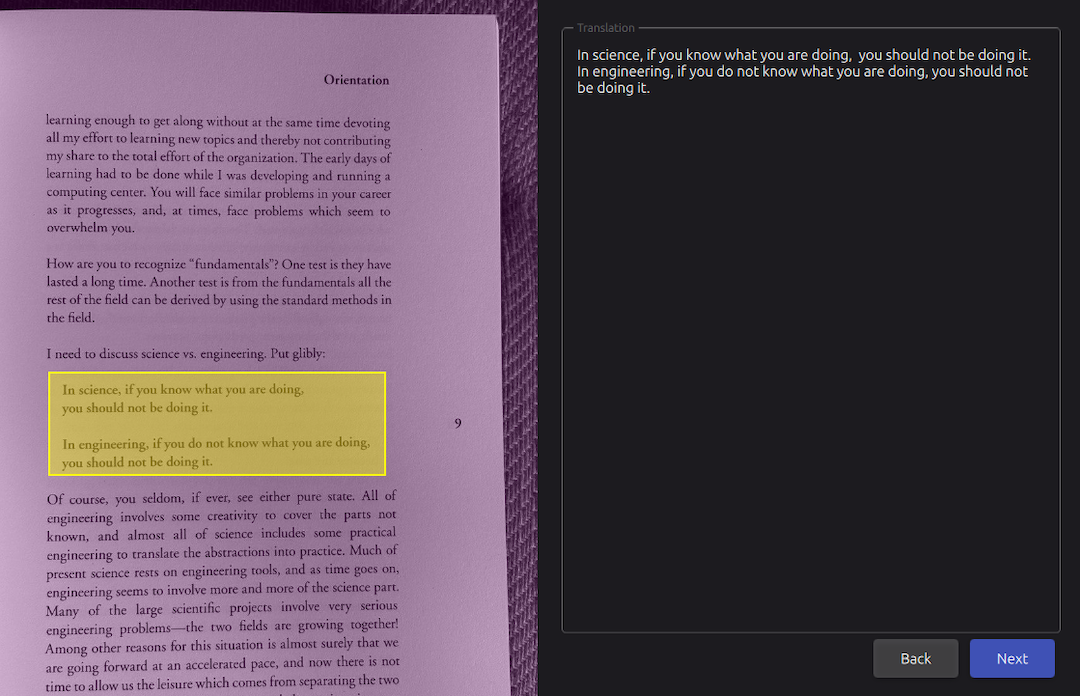
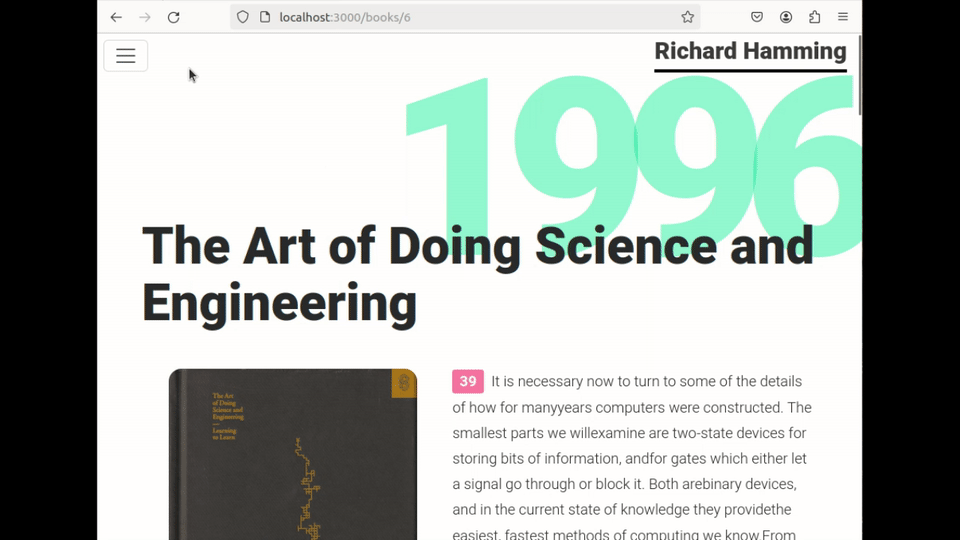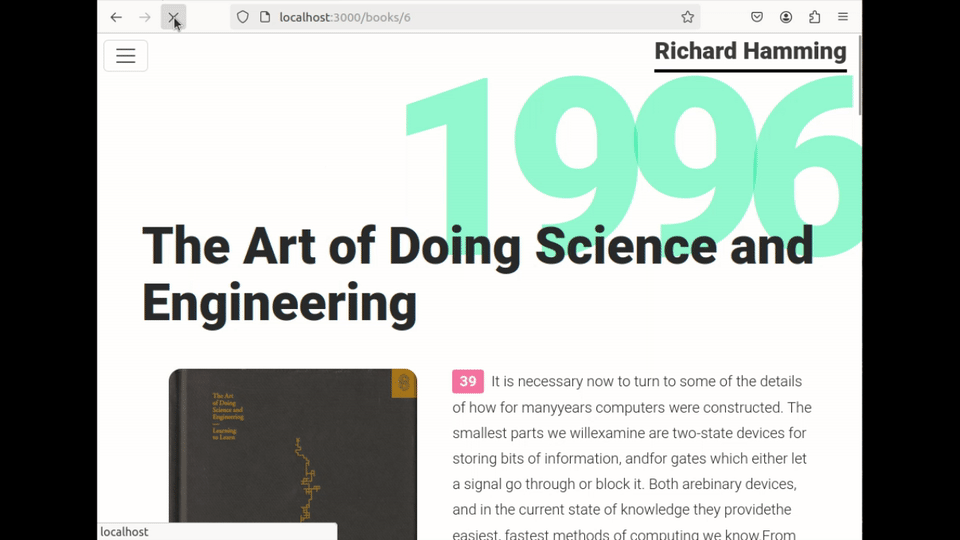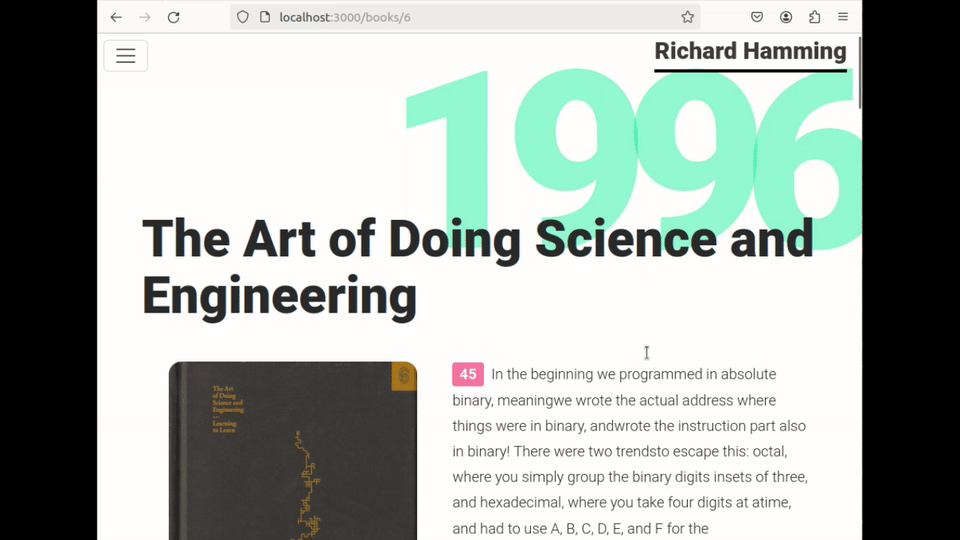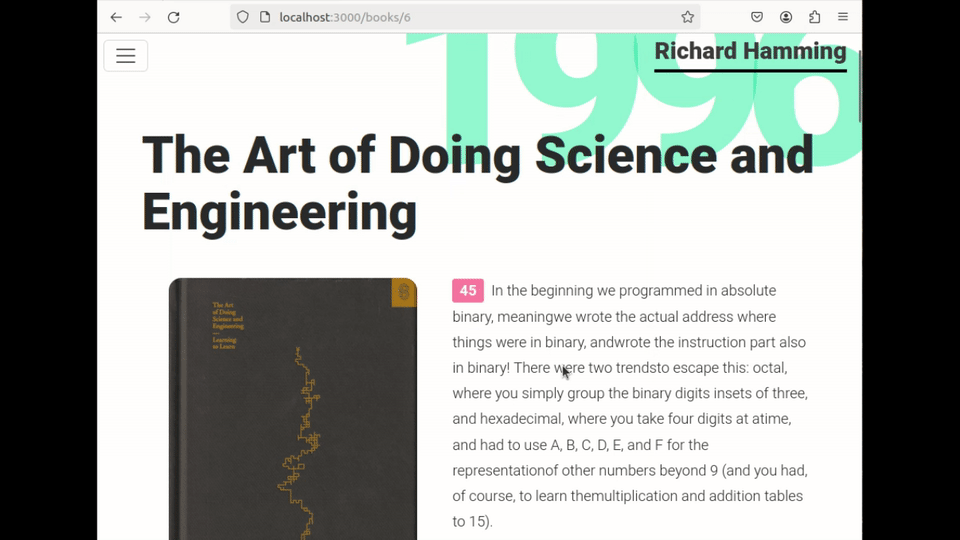
The user browses through their book collection and the related extracts :
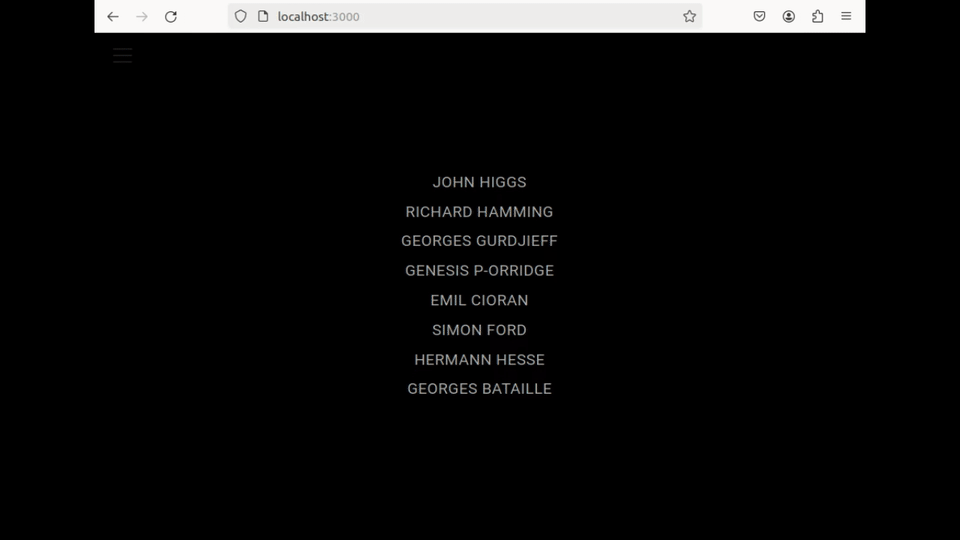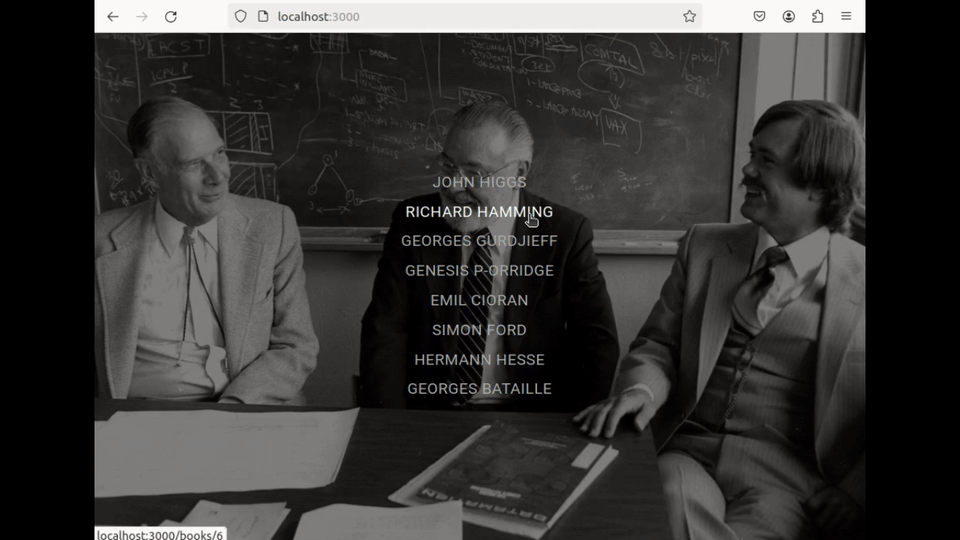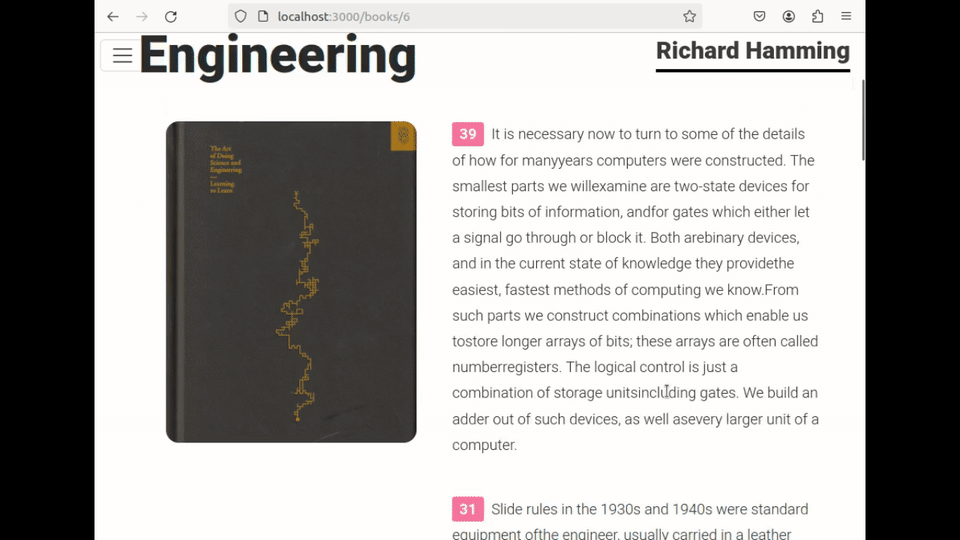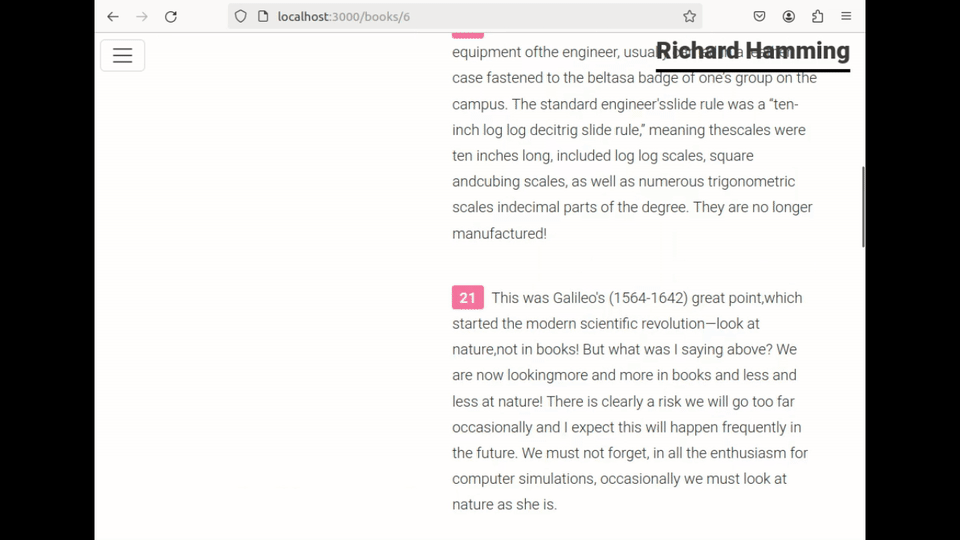
They launch the OCR application, where they are prompted to insert an image (or screenshot) of the page. Once loaded, the tool allows them to select the text area they wish to translate :
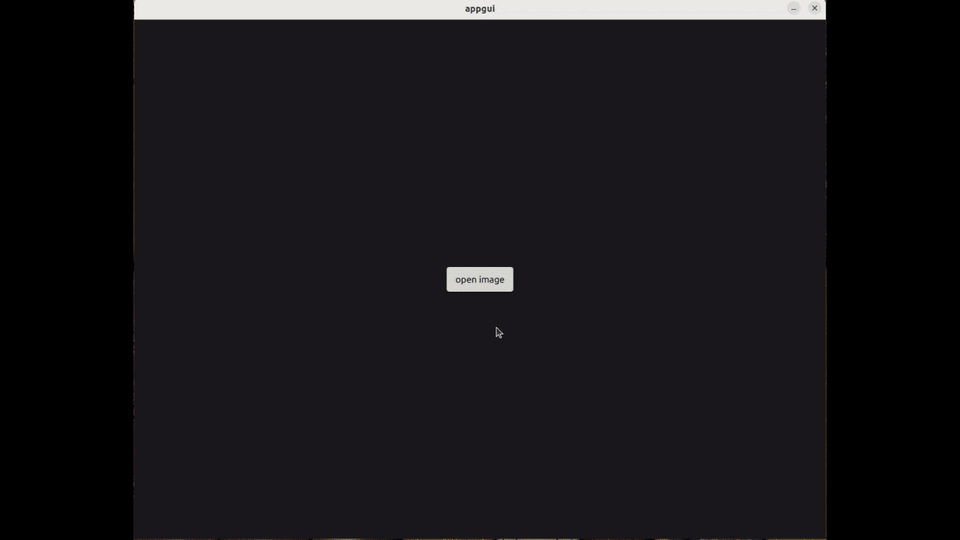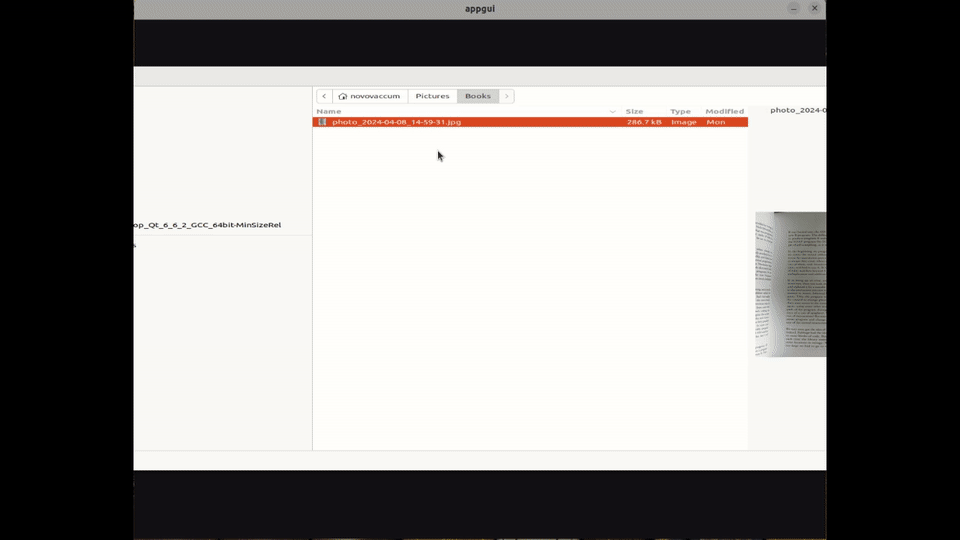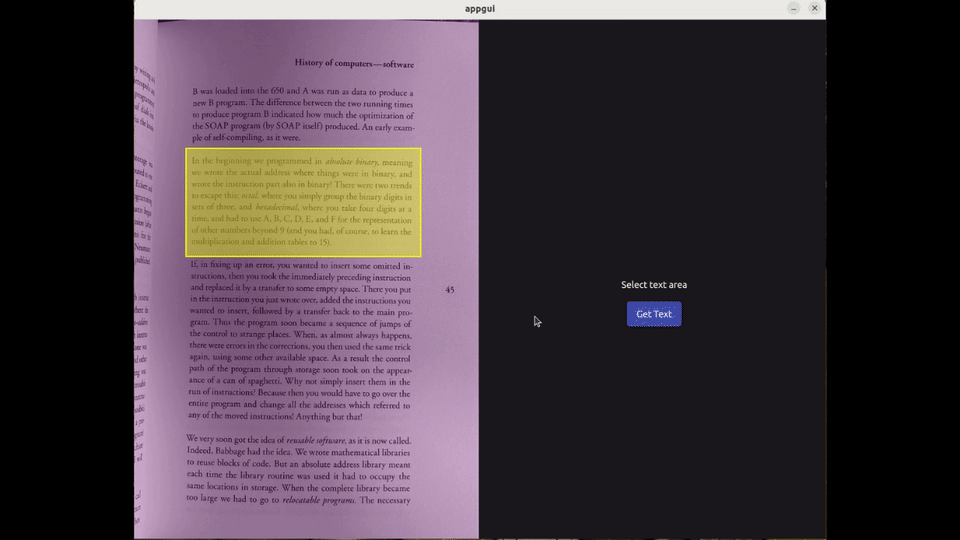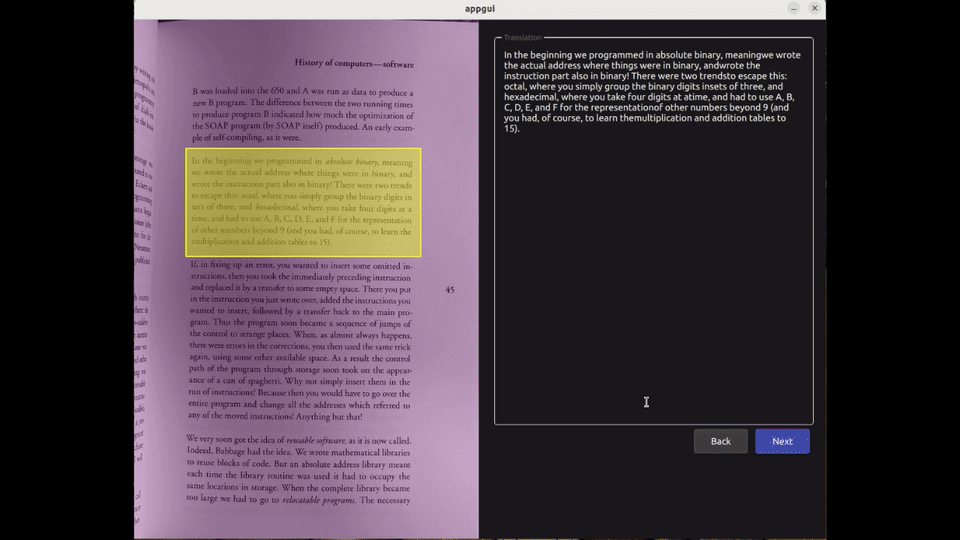
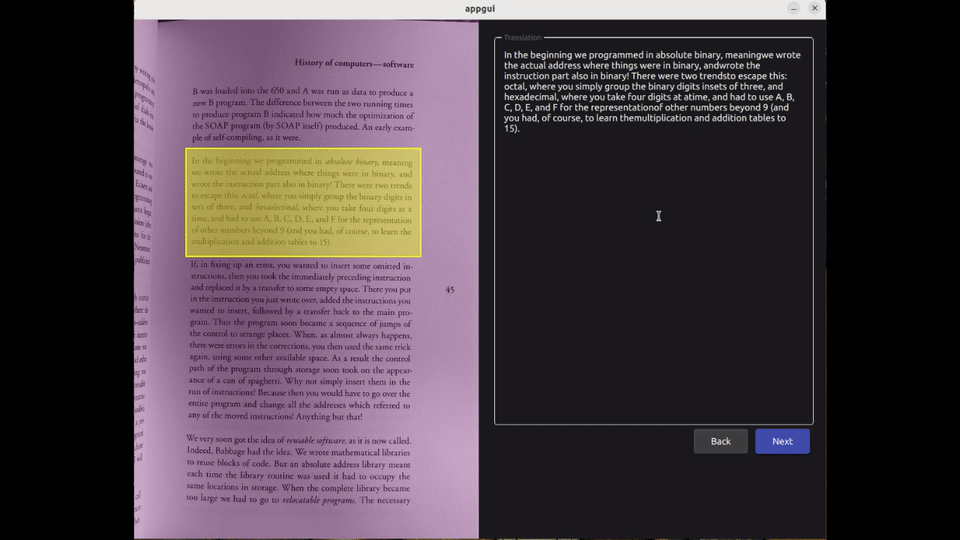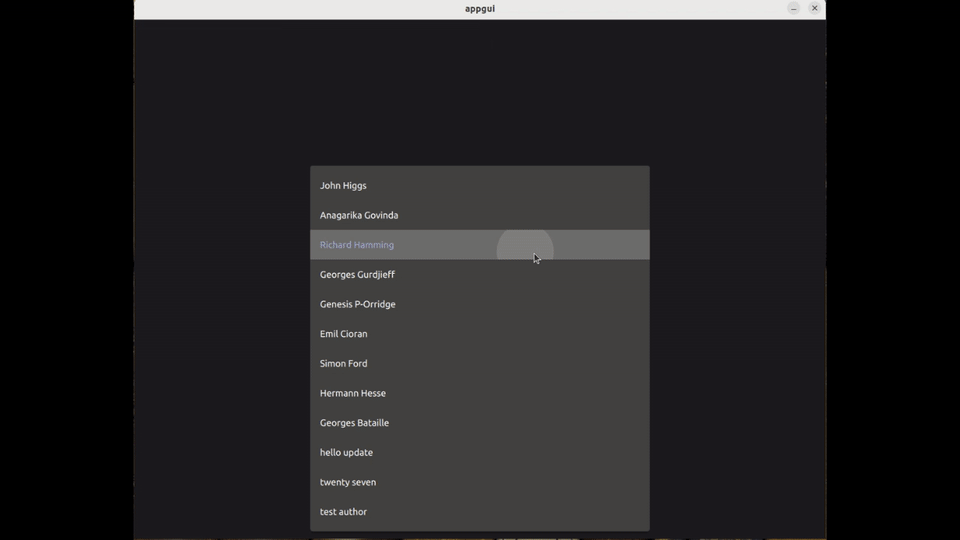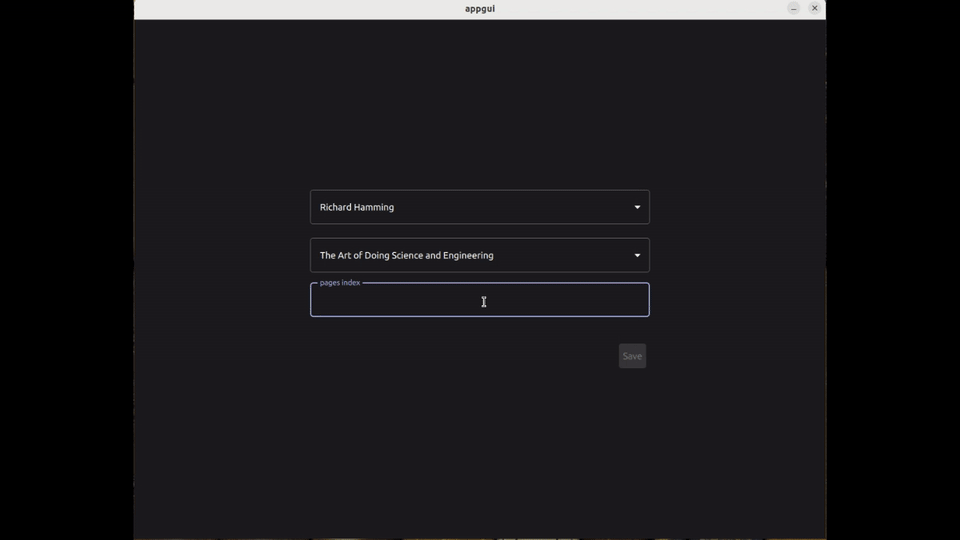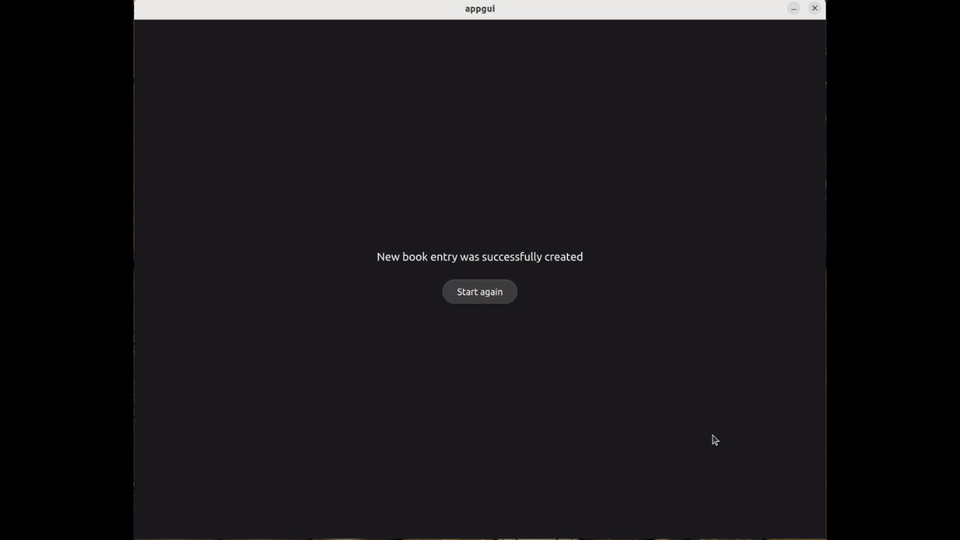
After the text has been retrieved, the user can make corrections and/or proceed to save the result. They select the author, the book, and enter the index of the page associated with this new entry :
Finally, they simply refresh the page to see the changes :
Architecture
The project is divided between web services to provide persistence and interaction over the collected data and a standalone GUI for the OCR. It revolves around three main components :
- A simple frontend client built with React and using Nginx web server
- Python FastAPI web framework to provide an API instance to fetch and persist book data collection
- Qt Framework to build a standalone OCR as a wrapper for OpenCV and Tesseract
Technology stack
Back-end
- FastAPI : Python Web framework to build APIs. Known for its performances and ease of use.
- SQLAlchemy : Python SQL toolkit and ORM that simplifies database interactions and management.
- Pydantic : Data validation and settings management using Python type annotations.
- Uvicorn : ASGI server for running FastAPI applications
Front-end
- React : JavaScript library for building user interfaces with reusable components
- React-Bootstrap : Bootstrap components built with React for responsive design
- Nginx : High-performance HTTP web server and reverse proxy for serving applications
GUI
- Qt : Cross-platform framework for developing desktop, embedded and mobile application with C++.
- QML : Declarative language for designing fluid user interfaces in Qt applications.
- QtQuick : Module for building dynamic UIs using QML and JavaScript in Qt.
- OpenCV : Library for computer vision tasks, enabling image processing and analysis.
- Tesseract : Open Source OCR engine that converts image-to-text
Deployment
- Docker : open platform to build, ship, and run applications in containers
- Docker compose : Tool for defining and running multi-container Docker applications easily.
Methodology
OCR implementation
To facilitate the process of image-to-text recognition, several image preprocessing steps must be performed, including binarization, noise removal, or grayscale conversion. In computer vision projects, this is typically accomplished using libraries such as OpenCV, aimed at simplifying visual information and enhancing OCR performance.
For this project, based on the quality of the provided images, converting them to grayscale was sufficient to achieve accurate results.
Region of interest
One of the key requirements for this application was to allow the user to define the selection or ROI on the image to be translated. Adjustments were necessary to translate the user's mouse coordinates from their selection within the interface to the 'real' coordinates of the original image size, ensuring that the correct data could be updated and processed, as shown in the code snippet below. :
cv::Mat ImageTreatment::cropSelection(const cv::Mat &mat, Selection &imgSelection) { // Original cv::Mat size int orig_w = mat.size().width; int orig_h = mat.size().height; // calculate width and height ratio (visible size vs. real size) float wRatio = ((float)orig_w / (float)imgSelection.m_visible_w); float hRatio = ((float)orig_h / (float)imgSelection.m_visible_h); // apply ratio on imgSelection float xOffset = (float)(imgSelection.m_x) * wRatio; float yOffset = (float)(imgSelection.m_y) * hRatio; float width = (float)(imgSelection.m_w) * wRatio; float height = (float)(imgSelection.m_h) * hRatio; // generate new matrix with region of interest to be cropped // Rect(x, y, width, height) cv::Mat ROI(mat, cv::Rect((int)xOffset, (int)yOffset, (int)width , (int)height)); // making a copy to be returned cv::Mat cropped; ROI.copyTo(cropped); return cropped; }
Requirements
API
- Docker 26.0.1+
- Docker compose 2.26.1+
GUI
Installation
The code repository is splitted upon two main directories. The api folder containing all of our frontend and backend services, while the ocr folder gathers all files related to our gui :
.
├── api
│ ├── backend
│ ├── db
│ └── frontend
└── ocr
└── gui
Build and run the web services
First we need build our backend and frontend services. To do so, a docker-compose.yml file is present inside the api directory. To automatically generate our build images and run the necessary containers :
cd api && docker compose up --build
Once our containers are running, we can access both our frontend and backend services.
Frontend (Default view)
Accessible at : http://localhost:3000

Backend (Interactive API docs)
Accessible at : http://localhost:8989/docs
FastAPI uses Swagger UI to generate an interactive documentation to visualize and interact with the api and its relied dataset.
Note: By default, the current project is shipped with mysql database schema and minimal dataset using mysql docker container.
Build the OCR (GUI)
Caution : At the time of its creation (19-04-2024), the gui part of the project had been developed on an x86_64 cpu architecture using Ubuntu 22.04 operating system. It also was later tested on the same architecture using an updated version of Ubuntu (Ubuntu 24.04) without known issues. Even though it should theoretically function well on other architectures and setups, I cannot guarantee its proper operation elsewhere.
OpenCV and Tesseract libraries installation
As our gui was built using OpenCV and Tesseract, we first need to install the dependencies following those instructions :
Build and compile from sources
You can directly build and compile the project using cmake and make inside the ocr/gui directory :
mkdir build && cd $_ cmake .. make
Caution : this step assumes you already installed all related Qt libraries and all necessary dependencies
Build and compile using Qt Creator
Qt Creator is still one of the simplest way to build the project as configured and generate the final executable. Installing Qt Creator will automatically install all necessary dependencies and help in managing the project.
Conclusion
The main goal of this project was to learn new skills and invest in an idea with tangible scope and practical applications. This motivated me to see it through to completion, while also ensuring that I left behind clear documentation for future reference, should I decide to revisit and further develop it one day.
This implementation of an OCR system is designed to automate data entry, revitalizing my initial concept. While I did not train the model with my own data or did not explore all the features and capabilities offered by the OCR, my primary objective was to ensure that the project operated seamlessly as a cohesive whole with all integrated technologies. The results were promising enough to serve as a solid "proof of concept".