This project demonstrates how to implement object detection and tracking the found objects. For demonstration, I implemented this by tracking cards.
A python script uses OpenCV to capture camera's images that are then passed to a loaded YOLOv5 model that was trained on Edge Impulse Studio. Using the Edge Impulse's Linux Python SDK the classifier returns the bounding boxes of found cards. These bounding boxes are then passed to a python script that implements a centroid-based tracking algorithm. This centroid-based tracking script was implemented by PyImageSearch. The resulting image, card's bounding boxes, and number of tracked cards is then displayed on a window.
![]()
Here is a link to the public Edge Impulse project : Object detection and tracking. The source files for this project are available in this GitHub repository: object_detection_and_tracking-centroid_based_algorithm.
In simple terms, object detection involves processing an image, detecting objects in the image and locating objects (things) in the image. These objects can be cars, people, buildings, trees, etc. Normally, this processing is done by algorithms that use Machine Learning or Deep Learning. These object detection algorithms return the name of the object and its bounding boxes (coordinates where the object appears in an image). In object tracking, we use an algorithm to track the movement of a detected object.
The object tracking technique used in this project is the centroid-based tracking. This technique has been extensively described on PyImageSearch.
![]()
Simply, in this technique we first get an object's bounding box and compute its centroid. Afterwards, we compute a property, called the Euclidean distance, between new bounding boxes and existing bounding boxes. Finally, we update the x, y coordinates of existing objects and this implements the object tracking. If we get new bounding boxes, we register them and do the tracking.
But what happens when an tracked object is not being seen anymore? To handle this situation, the algorithm deregisters previous objects that cannot be matched to existing objects after a given number of subsequent frames. In the centroid_tracker.py script, there is a parameter called maxDisappeared that specifies the number of subsequent frames after which an object will be deregistered. To simplify the object tracking algorithm, the tracking script uses the latest predicted bounding boxes to keep track of an object. This is however not an ideal object tracking technique.
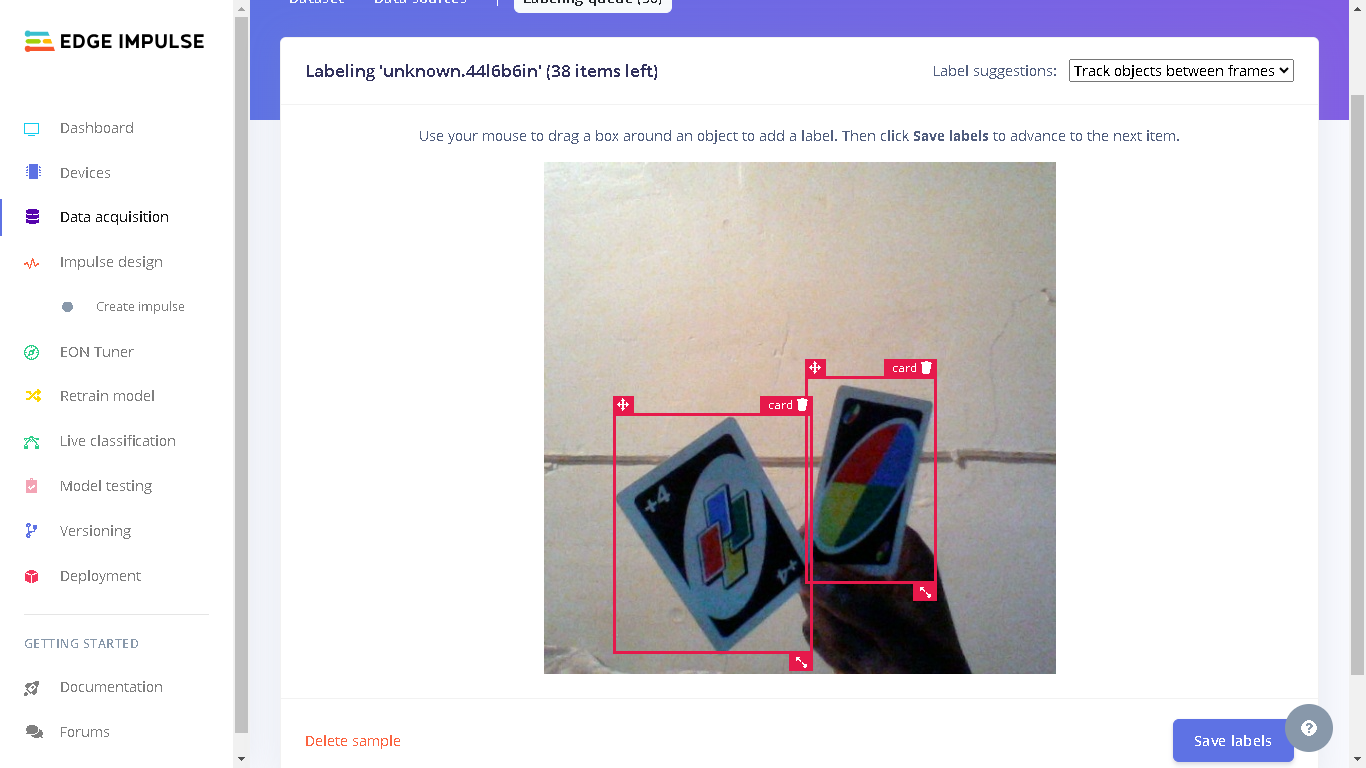
To train a Machine Learning model to detect cards, I first took images of some Uno cards. Note that it is advisable to collect your data in a way that is representative to how the deployment environment will look like. In total, I took 100 images of Uno cards and split them with a 80/20 ratio for training and testing. Note that it is recommended to have more images so that the model learns well, but in this demo I worked with this number and the model performed well. The next step was to label the cards in all images which I also did from the Studio. Note that for the labelling, Edge Impulse has AI assisted labelling which can be used by tracking objects in frames, classify objects with YOLOv5 or classify objects with your pertained model. In my case I chose to track objects between frames, which automatically drew the bounding boxes on cards.
We can now use our dataset to train a model. This requires two important features: a processing and learning block. Documentation on Impulse Design can be found on this page. For my Impulse, I settled with an image width and height of 320x320 pixels; and resize mode to Squash. Processing block is set to “Image” and the Learning block is “Object Detection(images)”.
Also, when running the object detection script, we can see the camera feed but the resolution of this feed is controlled by the model's input size. Simply, a smaller image size will mean that the OpenCV camera window will be pixelated. For demonstration, I used an image size of 320x320 pixels so that the camera feed can be clear. A lower image resolution like 96x96 or 160x160 worked very well.
_qPd9cMFPBh.png)
The next step is to use the processing block (Image) to generate features from our dataset.
_3NpiOT3YC6.png)
Finally, the last step is to train the model. For the Neural Network architecture, I used a YOLOv5 model. Note that I did a lot of tweaking between the image input size, model type and number of training cycles (epochs). I settled with the current configuration based on the:
_EIwdZnP01e.png)
Note that the on-device performance estimations are for the Raspberry Pi 4. On a personal computer, I got inference time of around 60ms (milliseconds). However, we can reduce the image input size to say 96x96px and this will greatly reduce the model's size as well as the inference time.
When training the model, we used 80% of the data in the dataset. The remaining 20% is used to test the accuracy of the model in classifying unseen data. We need to verify that our model has not overfit by testing it on new data. If a model performs poorly, then it means that it overfit (crammed the dataset). This can be resolved by adding more dataset and/or reconfiguring the processing and learning blocks, and even adding Data Augmentation. Increasing performance tricks can be found in this guide.
In my tests the model achieved an accuracy of 100%. Note that this is not an assurance that the model is perfect. The dataset was small and the model will not perform well in other situations, say with background objects or in a differently lit environment.
_dBp7v8yfom.png)
Below is a test result on an image. We can see that the model is able to correctly detect the card.
_v5HkSNB9jH.png)
To run the model locally on a Linux-based computer, we can run the command edge-impulse-linux-runner --clean and this lets us log in to our Edge Impulse account and select the cloned public project. The model will be downloaded and inference will start automatically. We can then go to the provided URL(the computer's IP address at port 4912) and we will see the feed being captured by the camera as well as the bounding boxes if present.
Using Edge Impulse Linux Python SDK, I created a python script that captures images from a camera using OpenCV, then passes the images to a classifier that returns, if any, the bounding boxes of cards in an image. These bounding boxes are then passed to the centroid_tracker script that implements registering objects, tracking them and deregistering them if required.
In the repository, I uploaded two .eim executables which are Edge Impulse YOLOv5 models with image input sizes of 160x160 pixels and 320x320 pixels. Feel free to load any of these models in ei_object_detection_and_tracking.py by updating the file path of the modelfile variable.
The repository describes how you can run the project, please check the README file for the detailed steps.
Changing the tracked object is very simple and I would highly recommend training and deploying the Machine Learning model using Edge Impulse. To do this, please follow the following steps:
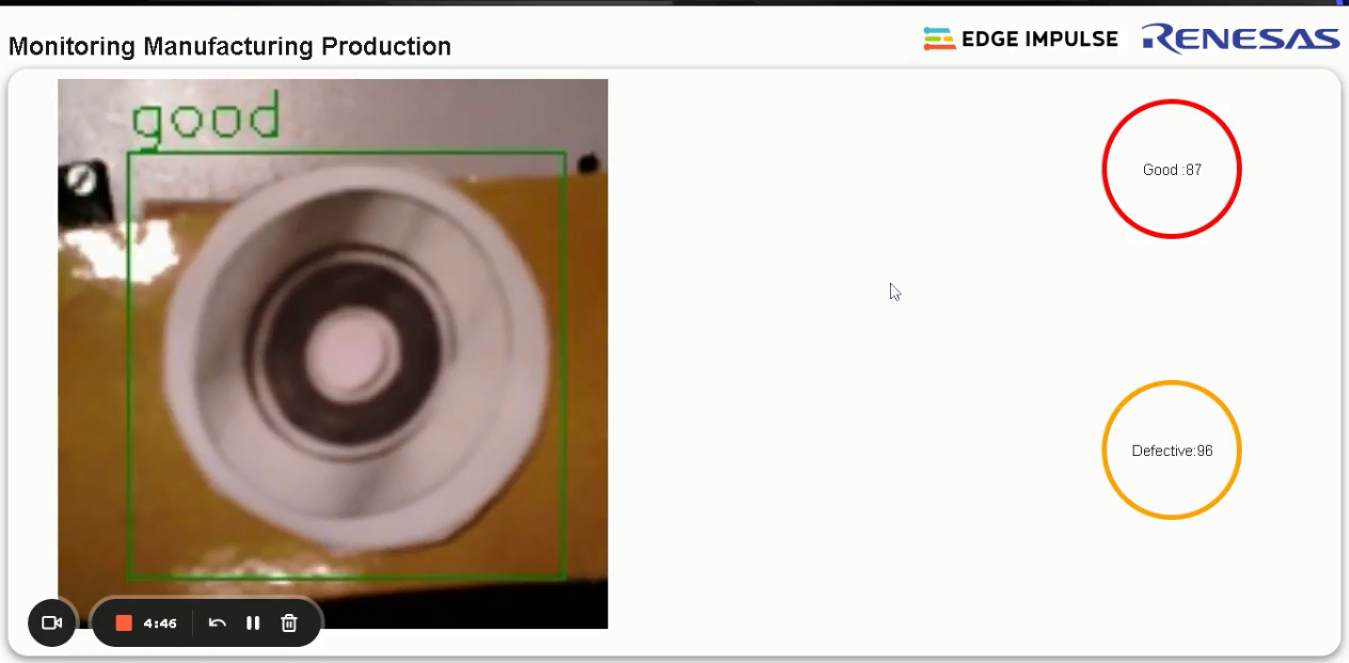
modelfile path in ei_object_detection_and_tracking.py to match the name of your downloaded .eim fileif(bb['label'] == 'card'). For example, in this case, card is the target class.This object tracking algorithm can be applied to a wide range of use cases, such as counting items on a conveyor belt that transports manufactured products for inspection using computer vision. For example, in this project that develops a computer vision system for product inspection we could enhance the conveyor belt system to perform additional actions, such as sorting good and defective submersible pump impellers. The object tracking algorithm can identify and track these impellers, enabling a robotic arm to automatically sort them based on their quality.