
Tags: AI · LLM · Multi-Agent Systems · LangGraph · FastAPI · Deployment · Healthcare AI · Text-to-Speech · Speech-to-Text · RAG · PubMed
⚠️ MEDICAL DISCLAIMER: Obiora is NOT a replacement for professional medical diagnosis, treatment, or advice. It is an AI assistant for informational purposes only. In any life-threatening situation, call your local emergency services immediately.
This publication documents the design, development, and deployment of Obiora, a multi-agent medical AI assistant built using large language models and deployed as a production-ready API.
Unlike traditional single-prompt chatbot systems, Obiora introduces a stateful, multi-agent architecture that separates concerns between a conversational assistant and a specialised medical persona (Dr. Obiora). The system handles real user flows including onboarding, location-aware hospital search, payment gating, session management, and post-consultation summaries — deployed with a full CI/CD pipeline that runs an LLM-as-judge evaluation suite before every deployment.
The application runs on FastAPI + Docker on Render, with two persistent SQLite memory layers, PubMed-backed retrieval-augmented generation (RAG) for evidence-grounded responses, and end-to-end voice interaction via speech-to-text and text-to-speech pipelines. The architecture is designed to be model-agnostic — the underlying LLM provider can be swapped without changing any system logic.
Healthcare access — especially for quick, low-friction consultations — is often limited by cost barriers, availability of professionals, and friction in reaching basic medical guidance. In urgent situations, people also struggle to quickly locate nearby hospitals.
Obiora addresses this by providing a structured AI-assisted experience that:
This is not just a chatbot — it is a controlled interaction system with enforced workflow transitions, persistent memory, and a production deployment pipeline.
Standard Text Interaction:
User: Hello
Assistant: Welcome to Obiora! I'm your assistant. What's your name?
User: My name is Tunde
Assistant: Nice to meet you, Tunde! How can I help — find a hospital
or speak with Dr. Obiora?
User: I need a hospital near me
Assistant: [auto-detects IP location → Ibadan, Oyo State, Nigeria]
I've detected your location as Ibadan, Oyo State. Is that correct?
User: Yes
Assistant: [searches via Tavily → returns nearby hospitals with contacts]
Consultation Interaction:
User: I want to speak with Dr. Obiora
Assistant: Dr. Obiora's consultation fee is N12,500.
Please provide your 10-digit account number.
User: 1234567890
Assistant: Payment successful! Are you ready to be transferred to Dr. Obiora?
User: Yes
Dr. Obiora: Welcome, Tunde! Thank you for your payment.
I'm Dr. Obiora. What would you like to discuss today?
User: I have a persistent headache for 3 days
Dr. Obiora: [queries PubMed, returns evidence-grounded response]
Voice Interaction:
User uploads audio → Whisper STT transcribes → LangGraph processes
→ edge-tts synthesises response → text + base64 audio returned
Functional
Performance
Product
Stage Users/day Notes
MVP 50–200 Testing + demos
Growth 1,000+ API integrations
Scale 10,000+ Health platform deployments
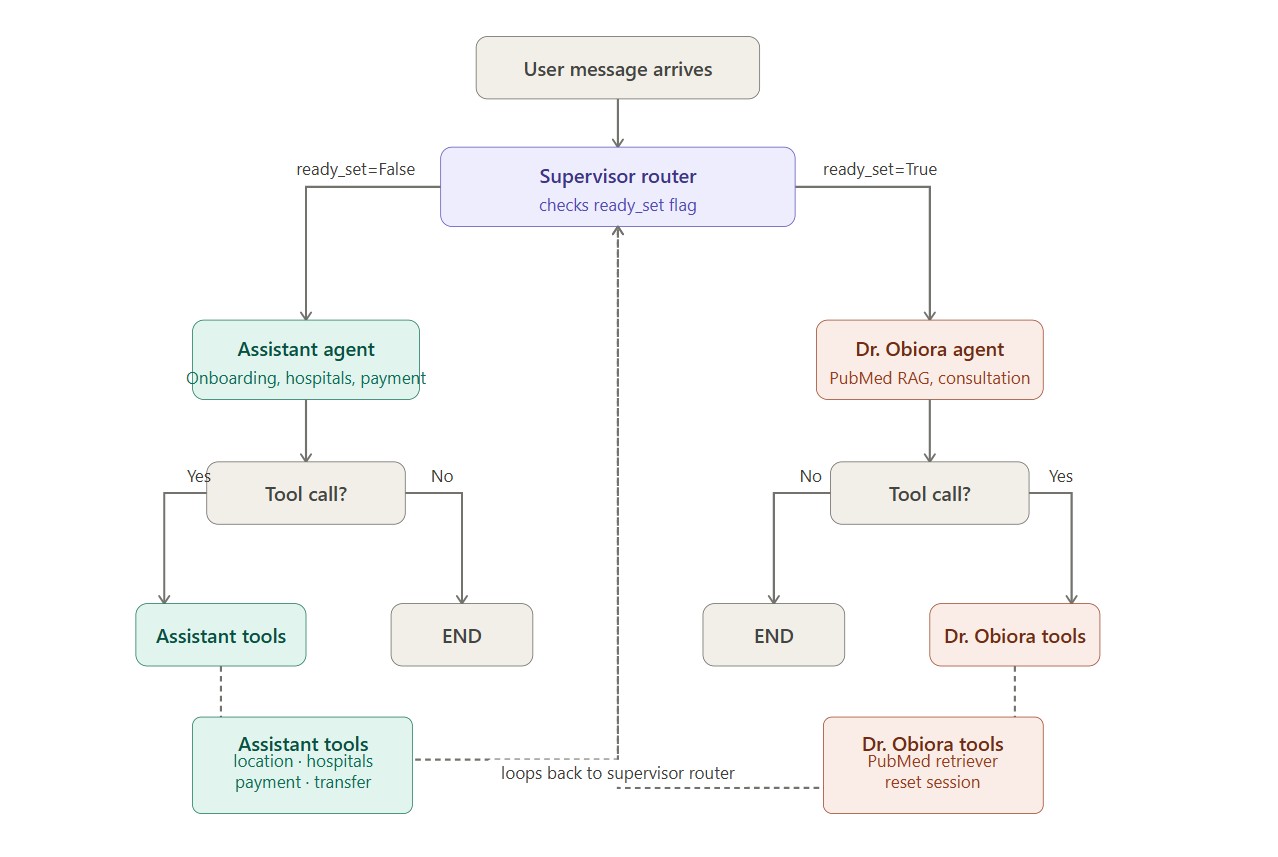
Obiora is built on a supervisor-pattern multi-agent architecture powered by LangGraph. Routing between agents is fully deterministic — no LLM is involved in routing decisions.
User login (user_id)
↓
Supervisor router ←─────────────────────────────────┐
↓ │
Assistant agent ──── payment ──── Dr. Obiora agent ───┘
↓ ↑
SqliteSaver (short-term) SQLiteStore (long-term: profile + dr_summary)
Two agents, distinct responsibilities:
| Agent | Responsibility |
|---|---|
| Assistant | Onboarding, location detection, hospital search, payment, session routing |
| Dr. Obiora | Medical consultation backed by PubMed RAG, session memory, summarisation |
The architecture is model-agnostic — the LLM provider (currently Groq) and specific models can be swapped without changing the graph, tools, prompts, or any other system component.
Routing is controlled by a single boolean in the agent state: ready_set.
def supervisor_router(state: AgentState) -> str: return "obiora_node" if state.get("ready_set") else "assistant_node"
ready_set becomes True only after:
ready_set returns to False only after:
The flowchart below illustrates this branching logic — recommended to draw using Excalidraw or draw.io for the publication:
Every message arrives
↓
supervisor_router checks ready_set
↓ ↓
ready_set=True ready_set=False
↓ ↓
obiora_node assistant_node
↓ ↓
tool call? tool call?
↓ ↓ ↓ ↓
YES NO YES NO
↓ ↓ ↓ ↓
obiora_ END assistant_ END
tool_node tool_node
↓ ↓
supervisor_router (loops back)
class AgentState(TypedDict): messages: Annotated[list[AnyMessage], add] # full conversation history username: str # collected during onboarding new_user: bool # session flag account_number: str # payment gate ready_set: bool # routes between agents dr_summary: str # Dr. Obiora's private session notes date: str # session timestamp (Africa/Lagos timezone)
dr_summary is private to Dr. Obiora — injected only into Dr. Obiora's system prompt, never surfaced to the Assistant. This enforces a clean separation between onboarding context and medical consultation context.
SqliteSaver (obiora_checkpoints.db)
└── Short-term: full conversation history per thread_id
└── Restored on every request before graph invocation
SQLiteStore (obiora_store.db)
└── Long-term: username, account_number, dr_summary per user_id
└── dr_summary: cumulative session notes appended after each consultation
private to Dr. Obiora — never shown to the Assistant
Both stores use SQLite for the current single-server deployment. Swap both for Postgres when scaling beyond one instance.
One of the Assistant's core capabilities is helping users in urgent situations quickly find hospitals near them.
@tool def get_user_location() -> dict: # IP-based geolocation using geocoder g = geocoder.ip("me") lat, lng = g.latlng # Reverse geocode to get human-readable address geolocator = Nominatim(user_agent="obiora_emergency_app") location = geolocator.reverse((lat, lng), language="en") return { "region": ..., "state": ..., "country": ..., "latitude": ..., "longitude": ... } @tool def available_hospitals_tool(location_data: dict) -> dict: # Web search for hospitals near detected/confirmed location tavily = TavilySearchResults(max_results=5) query = f"hospitals near {region} {state} {country}" results = tavily.invoke({"query": query}) # Returns up to 5 results including names, addresses, contacts where available
The Assistant does not transfer the user to a hospital location silently. The flow is:
get_user_location to detect location via IPavailable_hospitals_tool with confirmed locationThis confirmation step ensures the user is not sent to the wrong area due to IP geolocation inaccuracy.
Dr. Obiora does not rely solely on the LLM's training-time knowledge. For every consultation query requiring specific medical information, the agent calls a PubMed retrieval tool before formulating a response.
@tool def retriever_tool(query: str) -> dict: # Step 1: Search PubMed for relevant article IDs search_response = requests.get( "https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi", params={"db": "pubmed", "term": query, "retmax": 3, "retmode": "json"}, timeout=10 ) id_list = search_response.json()["esearchresult"]["idlist"] # Step 2: Fetch abstracts for those IDs fetch_response = requests.get( "https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi", params={"db": "pubmed", "id": ",".join(id_list), "retmode": "text", "rettype": "abstract"}, timeout=10 ) return {"message": fetch_response.text.strip()[:1500]}
Retrieved abstracts are injected into Dr. Obiora's context window as tool results, grounding the response in real published literature. The user never sees the raw tool call — Dr. Obiora synthesises the content naturally.
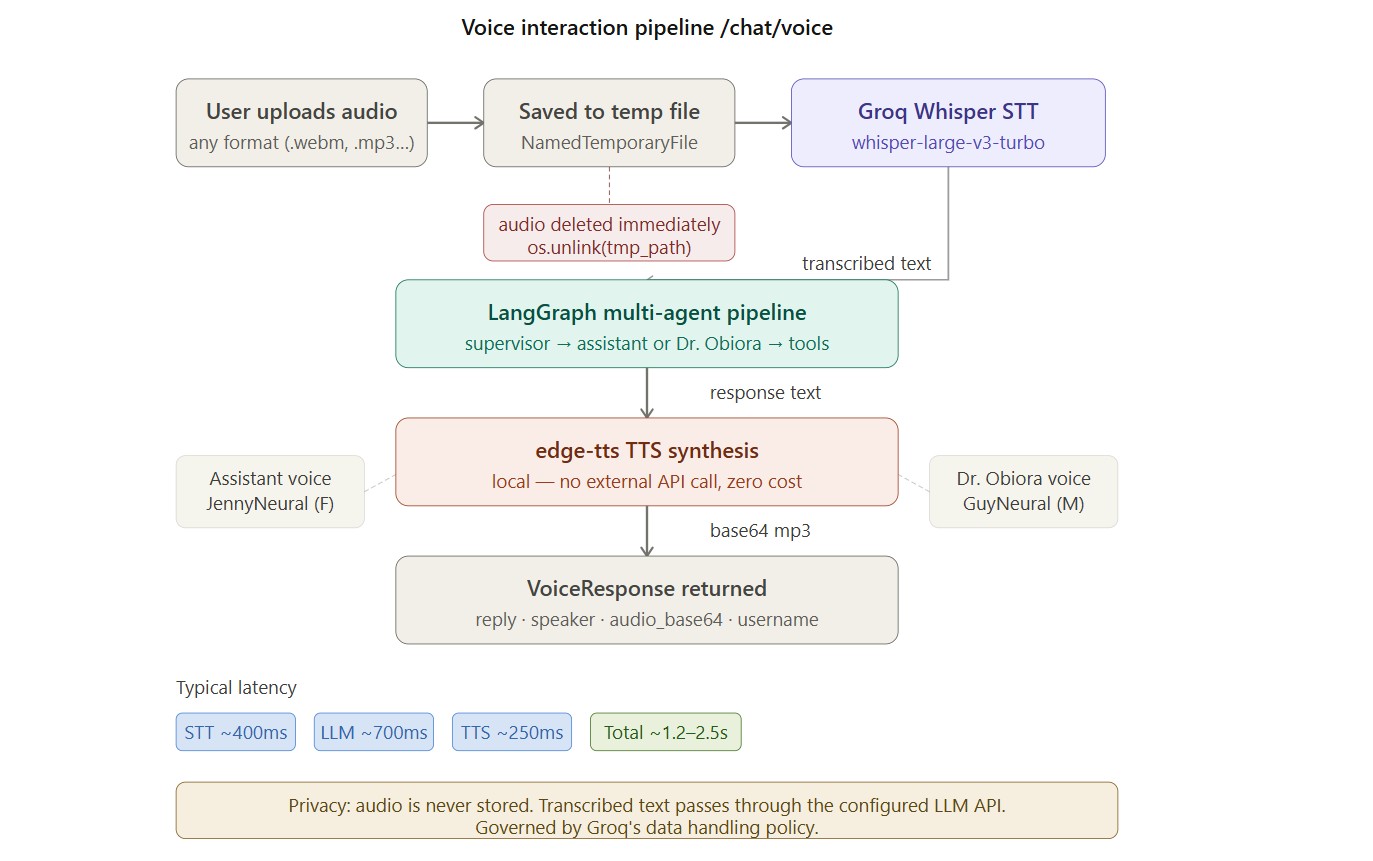
Obiora supports end-to-end voice via the /chat/voice endpoint.
User uploads audio file
↓
Saved to temporary file (tempfile.NamedTemporaryFile)
↓
Groq Whisper STT (whisper-large-v3-turbo, language="en")
↓
Temporary audio file deleted immediately (os.unlink)
↓
Transcribed text passed to LangGraph chat pipeline
↓
Response text passed to edge-tts TTS
→ Assistant voice: "en-US-JennyNeural" (female)
→ Dr. Obiora voice: "en-US-GuyNeural" (male)
↓
Audio converted to base64-encoded mp3
↓
VoiceResponse: { reply, speaker, audio_base64, username, new_user, ready_set }
Audio recordings are processed transiently and are never stored:
with tempfile.NamedTemporaryFile(delete=False, suffix=".webm") as tmp: tmp.write(await audio.read()) tmp_path = tmp.name # transcription happens... finally: if os.path.exists(tmp_path): os.unlink(tmp_path) # deleted immediately after transcription
Transcribed text passes through the LLM provider's API. Users should be aware that text content is governed by the provider's data handling policy.
Client
↓
FastAPI (main.py)
↓
load_user_profile() → SQLiteStore
↓
LangGraph graph.invoke()
↓
supervisor_router → assistant_node OR obiora_node
↓ ↓
assistant_tool_node obiora_tool_node
↓ ↓
save_user_profile() → SQLiteStore
↓
ChatResponse / VoiceResponse returned
| Method | Endpoint | Description |
|---|---|---|
| GET | /health | Health check — returns {"status": "ok"} |
| GET | / | Service info + endpoint directory |
| POST | /login | Load user profile by user_id |
| POST | /chat | Text message → text response |
| POST | /chat/voice | Audio upload → text + base64 audio response |
LoginRequest: { user_id: str } LoginResponse: { user_id, username, new_user, message } ChatRequest: { user_id: str, message: str } ChatResponse: { reply, speaker, username, new_user, ready_set } VoiceResponse: { reply, speaker, audio_base64, username, new_user, ready_set }
speaker returns "assistant" or "obiora" — useful for clients displaying a different UI per agent.
git clone https://github.com/blaqadonis/obiora.git cd obiora python -m venv venv source venv/bin/activate # Windows: venv\Scripts\activate pip install -r requirements.txt cp .env.example .env # Fill in GROQ_API_KEY and TAVILY_API_KEY in .env uvicorn app.main:app --reload
API docs at http://localhost:8000/docs
| Variable | Description | Where to get it |
|---|---|---|
GROQ_API_KEY | LLM inference + Whisper STT | Groq |
TAVILY_API_KEY | Hospital search | Tavily |
DATA_DIR | SQLite DB file path | Default: ./data |
Pull Request to main
↓
GitHub Actions runs: pytest tests/test_evals.py -v
↓
All tests must pass before merge
↓
Push to main → evals run again
↓
All pass → Render deploy hook fires automatically
Obiora ships with an LLM-as-judge evaluation suite (tests/test_evals.py) that runs automatically in CI before every deployment.
| Eval Set | Tests | What It Measures |
|---|---|---|
| Eval 1 — Assistant Behaviour | 6 | Onboarding, name collection, hospital search, payment gate, transfer consent |
| Eval 2 — Dr. Obiora Behaviour | 4 | First-entry welcome, medical response quality, session-end warning, reset confirmation |
| Eval 3 — Memory & Login | 4 | New user detection, profile restore, summary persistence, cross-session recall |
| Eval 4 — Model Comparison | 6 × 3 models | Same 6 test cases run across three different Groq models |
Total: 14 core tests + 18 model comparison runs
Each test runs a scripted conversation through an isolated in-memory graph, then passes the final agent response and a plain-English criterion to a judge LLM:
def judge(response: str, criteria: str) -> dict: # Returns: {"pass": bool, "score": int, "reason": str}
Results print with ✅ / ❌ per test and a final score per eval set.
1d. Payment done → asks "are you ready?" before transferring
Criteria: "After payment, assistant must ask if user is ready.
No automatic transfer."
2c. End session → warns about N12,500 re-payment
Criteria: "Dr. Obiora must warn about re-payment and ask for
confirmation. Must NOT reset automatically."
3d. Second session → Dr. Obiora references previous summary
Criteria: "Dr. Obiora should reference the previous session —
mentioning chest pains or the cardiologist advice."
The eval suite tests workflow and behavioural correctness, not medical accuracy. Medical response quality is assessed qualitatively by the judge LLM on a pass/fail basis. Quantitative medical benchmarking is a planned future improvement.
| Component | Typical Latency | Notes |
|---|---|---|
| FastAPI routing + profile load | ~50–100ms | SQLite read, minimal overhead |
| LLM inference — Assistant | ~300–600ms | Fast model via Groq |
| LLM inference — Dr. Obiora | ~500–900ms | Stronger model via Groq |
| PubMed tool call | ~300–700ms | External NCBI API |
| Whisper STT (voice only) | ~300–500ms | whisper-large-v3-turbo |
| edge-tts TTS (voice only) | ~150–350ms | Local synthesis, no external API |
| Total — text | ~400ms–1.6s | |
| Total — voice | ~1.2s–2.5s | Includes STT + TTS |
Measured on Render free tier. Paid tier reduces latency.
Groq was chosen specifically for fast LLM inference. edge-tts was chosen for TTS because it runs locally with zero API cost.
| Component | Cost |
|---|---|
| LLM inference — Groq | Usage-based; free tier available |
| Hosting — Render | Free / low tier (paid recommended for production) |
| SQLite storage | Effectively free — flat files |
| Whisper STT | Included in Groq usage |
| edge-tts TTS | Free — local synthesis, no API |
| PubMed / NCBI | Free — open public API, no key needed |
| Tavily search | Usage-based; free tier available |
The architecture scales linearly with token usage, not infrastructure complexity. The main cost lever at scale is prompt efficiency in the Dr. Obiora system prompt, called on every consultation turn.
| Concern | Implementation |
|---|---|
| API keys | Environment variables only; .env.example provided; never hardcoded |
| Voice recordings | Deleted immediately after transcription (os.unlink) — not stored |
| User data | SQLite stored locally on server; not transmitted to third parties |
| LLM provider | Text content passes through the configured LLM API |
| Input validation | user_id validated on all endpoints; account number validated via ^\d{10}$ |
| CORS | Currently allow_origins=["*"] — restrict to known origins in production |
Planned improvements:
user_idThese limitations must be understood before deploying Obiora in any real-world healthcare context.
1. Not a diagnostic tool.
Obiora is not a replacement for professional medical diagnosis or treatment. All responses should be treated as general information only.
2. PubMed RAG is not clinically validated.
Retrieval is keyword-based and synthesis is not validated against clinical standards. The system can surface incorrect or outdated information.
3. General-purpose LLM, not a fine-tuned medical model.
The system uses a general-purpose LLM. It has not been fine-tuned on clinical datasets or evaluated against medical benchmarks (e.g., MedQA, USMLE).
4. No human-in-the-loop.
There is no mechanism for a clinician to review, override, or escalate AI responses.
5. IP geolocation is approximate.
The auto-detected location is based on IP address, which can be inaccurate — especially on mobile networks or VPNs. The Assistant always asks the user to confirm before searching.
6. Voice accuracy degrades for accents and non-native speakers.
Whisper performs well on standard English but accuracy decreases for non-native speakers, regional accents, and background noise. This is a well-documented limitation of current STT systems.
7. SQLite is not production-grade at scale.
Both memory stores must be migrated to Postgres for multi-instance deployments.
8. English only.
The system is prompt-engineered and tested in English only.
9. Payment is simulated.
The payment_tool validates account number format and generates a mock record. It does not connect to a real payment processor.
Short-term
Medium-term
Long-term
This project goes beyond a simple LLM demo by implementing:
Obiora demonstrates how to move from a single-prompt chatbot to a production-ready, multi-agent AI system.
What it is: a well-engineered, fast, production-deployed conversational medical assistant — with location-aware hospital search, PubMed-grounded medical responses, persistent cross-session memory, full voice capability, and an automated evaluation pipeline gating every deployment.
What it is not: a clinical triage system, a medical device, or a replacement for professional healthcare.
The architecture is deliberately model-agnostic and component-modular. The LLMs, memory stores, STT provider, and TTS engine can all be swapped without changing the core graph logic.
🔗 Links
GitHub: https://github.com/Blaqadonis/obiora
Live Demo: https://obiora.onrender.com
Obiora is a research and demonstration project. It is not a medical device and has not been evaluated for clinical use.