In recent days, businesses, governments, educators, and individuals are increasingly required to handle various documents, including invoices, legal papers, and educational materials. These documents can exist in multiple languages and formats, complicating the process, especially when dealing with regional languages like Nepali and Hindi. Current Optical Character Recognition (OCR) systems, such as i2OCR, Google’s Tesseract, and Microsoft OCR, excel at recognizing printed English text but struggle significantly with handwritten English. This challenge is exacerbated for languages utilizing the Devanagari script. As a result, many organizations still rely on manual data entry, leading to wasted manpower, inefficiency, and high labor costs. The limitations of existing OCR technologies highlight the urgent need for advancements in this field to improve automation and document management.
The limitations of current Optical Character Recognition (OCR) tools in effectively recognizing and extracting text from multiple scripts motivated my research in this technology. The goal of this project is to develop a Multilingual OCR system with a low Character Error Rate (CER) for handwritten English and Devanagari scripts, specifically for Hindi and Nepali languages. This system addresses challenges related to text extraction in various industries, including education, finance, government, and legal documents. In a country like Nepal, there are frequent cases of risks associated with preserving students’ exam papers, which can adversely affect their education and careers. By digitizing exam papers as a backup, this project aims to mitigate these issues and enhance the overall educational experience.
The background of the project originated from the observation of a significant deficiency in reliable text recognition tools across multiple languages, including handwritten English and Devanagari related language such as Nepali and Hindi. These languages are spoken by millions and billions of people, respectively. In the industry and government sector of south-east Asia, the demand for automated data entry, text extraction, document digitization, text analysis and searchability has been steadily increasing. Hence, the objective of this project is to develop a multilingual OCR system capable of accurately recognizing handwritten text in English, Nepali, and Hindi with low CER (Character Error Rate), which is the most crucial aspect influencing to the usage of OCR system. Thus, the projects employ advanced machine learning methods, especially deep learning, to address this challenge. The project integrates Computer Vision and Natural Language Processing for the robust outcome. For English text extraction, the Neural network architecture consist of Convolution layer combined with LSTM, utilizing the IAM Handwritten dataset. For Nepali and Hindi text recognition, it uses same datasets of Bhagwat Geeta images, and architecture involves CNNS with GRUs.
The robust and multi-language OCR system is hot research topic in the field of Computer Vision and Natural Language Processing. It has been the great topic of interest since long time. Due to the varying situation and problem, different research is carried out in their own way. For instance, some researchers may be developing OCR for number plates detection, while others might be working on hard copies, product’s image, or bill receipt. Additionally, they might be working with different languages, styles, fonts, skewness, and language scripts such as Nepali, English, Urdu, Chinese and so on.
The study from Facebook AI researcher (Huang, et al., 2021) has recently purposed multiplexed network with the claimed to be first model that can jointly use text detection and recognition with very high accuracy. Naïve training system for each language does not takes accountability of the precision of each language and it is also computationally expensive. The purposed architecture also reduces the computation as there is no need to train different model for each language. Language Prediction Network (LPN) is being used for automating the recognition of a languages. The output of the network is a vector of size L = Nlang i.e. the number of language class, which can later be converted into probabilities using a SoftMax. The strong point of the model is Nlang does not have to be equal to the Nrec i.e. the number of different recognition heads because model deals with shared alphabets. For instance, alphabet in Nepali and Hindi matches in most of the case, so prediction can be used interchangeably. Thus, in this case Nlang equals to Nrec.
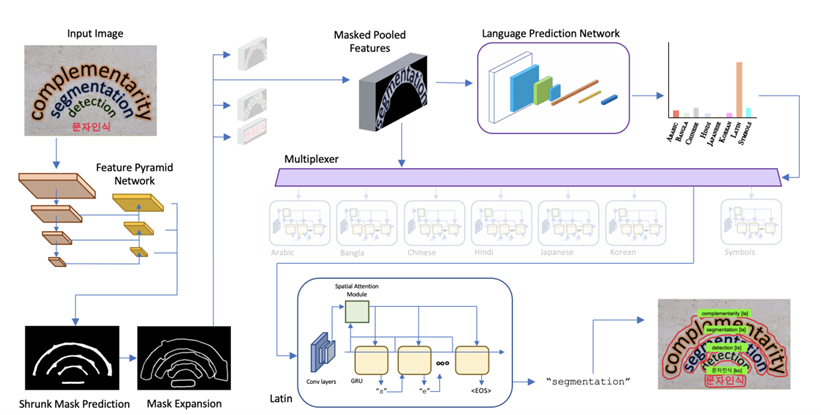
Figure 1; LPN architecture
Here is how Language Prediction Network (LPN) is calculated.
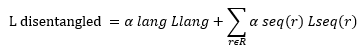
where, Llang, R, and Lseq(r) are the loss for LPN, set of recognition heads and loss for the recognition head r. are the two hyper-parameters of model.
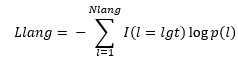
where, I(l = lgt) is the binary indicator i.e. 0 if the language do not matches or 1 if the expected language matches to the actual language, and p(l) is the probability of the word belonging to the language l.
.png?Expires=1783595884&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=DVXjairVeeAhHIckawcYBoJbe5AgixyAVlQ6hZzv7s7gqlOnt0Fmw~0IH0r76SOLoyxaD4WMyc6AJJAUcXAOVr-V8DDXRzCiVlHzeElTZtzEJuXMCiTZVDrprh1yhIM04ab-YoXfIGdQSc5qQxGQJ~D~ZnS1YmoGDycUeZ0cM8h4zfyBl-TDYZV0P7BoeZu5~iHGI3QlzOwgV5wqMfgQ6SRCOdJNgfJsMRONFOmRtD3knbcFLRmwoHJvK98Vn0xCAU0o3BamaCURuPjKRdsWeKyfZpkbt2AWhpCSYcb9sGCx~P-LjVHIqrUAGQb5AJHiaInQKgdwFNwu857wV-YOiw__)
where, p(yt = ct) is the predicted probability of character at position t of the sequence, T is the length character, Cr is the character set that is supported by recognition head r.

Figure 2; Recognizing text
Another study from (Biró, et al., 2023) evaluates the feasibility of synthesized language preparation and its comparison by implementation with machine learning based neural network architecture. The research aims to address the challenges of real-time multilingual OCR in a collaborative environment. The vocabulary is artificially generated by applying a sampling technique to real-world data and creating simulation scenarios where models and processes interact to create completely new data. So, the synthesis datasets for training ranges from 66k to 8.5M and total of 21 results were analysed. The straightforward comparison is conducted between Convolution Recurrent Neural Networks (CRNN) and patch-wise image tokenization framework (SVTR) model architectures as Machine learning based OCR engines. PaddleOCR was also configured for fine-tuning.
CRNN is basically the combination of Convolution Neural Network (CNN) and Recurrent Neural Network (RNN) where it retrieves feature from the input image through CNN and RNN models the sequential dependencies between the characters in the text. On the other hand, SVTR is an advance OCR system that uses both deep learning and traditional image processing techniques to recognizes text in images. Additionally, SVTR also contains attention mechanisms that allows to prioritize on most important visual components and boosts the noise and distortion resistance of the model (Biró, et al., 2023). So, these two modern text recognition techniques were experimented shown in the figure below.
figure 3; distortion resistance
Multiple experiments were conducted with the proposed network architecture. But each time CRNN was able to outperform SVTR. The Machine learning models records the highest precision in Experiment 11, 12 and 14 with scores of 90.25%, 91.35% and 93.89%. So, now we will discuss the detail architecture of selected model from the study.
In compared to previous study, the research from Xinjiang university (Yu, et al., 2023) has argued experimentally to the previous study by improving the Convolution Recurrent Neural Network (CRNN) for scene text recognition. The improved CRNN model was also trained on synthetic datasets but tested on public datasets. For accomplishing this, the Connectionist Temporal Classification (CTC) function proposed by Alex Graves is redefined. After the feature is first extracted by Convolution Neural Network (CNN) algorithm, the feature dependencies are captured through Recurrent Neural Network (RNN), the output prediction distribution after applying RNN is fed to CTC for processing and then it gives a sequence of text as results. Text and speech signals are sequential data, which makes it difficult to perform segmentation. Additionally, the volume of text recognition data is huge, making it difficult to achieve segmentation and annotation. So, to make the Recurrent Neural Network (RNN) much more applicable for text recognition, the Connectionist Temporal Classification (CTC). The CTC decoding process maps the generated path into final sequence. The figure below shows an example of the final sequence mapped after deduplication and removal of a whitespace character using CTC.
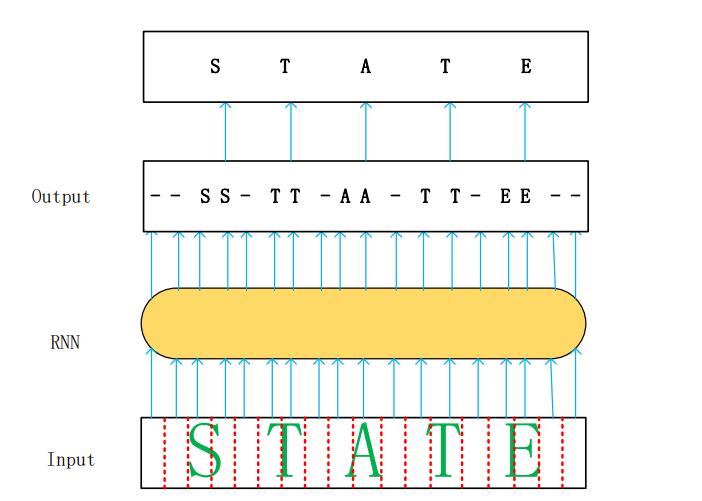
Figure 4; Input Output Sequence
The network structure of the model consists of three layers, that is convolution layers, recurrent layers and the transcription layers with the combination of CNN + RNN + CTC. In the beginning, image is converted to a grayscale and then resized to W*32 with fixed height. Recurrent layers using RNN predicts a label distribution of the feature sequence which is obtained from the convolution layers. The feature maps extracted by the CNN are split by column where each column of 512 – dimensional feature is input into two layers of 256-unit bidirectional LSTMs for classification. CTC than converts the label distribution obtained from RNN through transcription layer. The CTC algorithm deduplicates to obtain the final recognition result, and label smoothing is further added. The recognition result is then forwarded to the language model for correcting characters and finally the final output is obtained.
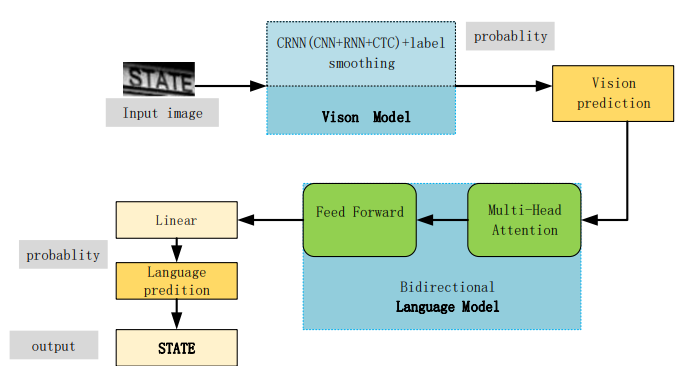
Figure 5; Structure of overall improved architecture
The datasets used in text recognition can be divided into synthetic and real. Synthetic datasets are mainly used for training, while real datasets are used for evaluating the training results. The study has used synthetic datasets: MJSynth a plain English text dataset that contains 3000 folders with about 9 million image and SynthText consisting of 800,000 scene images. The real datasets which is used are further divided into regular and irregular, based on the format of the text in the Image. Regular datasets include IIT5k-words (IIT5k), SVT (Street View Text), and IC13 (ICDAR2013).
Deep Convolution neural networks (CNN) has shown state-of-the-art performance in various field of computer vision. Due to the availability of pre-trained models, one can save time and resources, and improve accuracy. In the study (K.O & Poruran, 2020), OCR-Nets variants of AlexNet & GoogleNet is presented for recognition of handwritten Urdu characters through transfer learning. While performing transfer learning, Initial layer weights are freeze and the last three-layers are fine-tuned for training and classification of Urdu characters whereas only four inception module is utilized, and the last two layers are modified for learning and classification of the Urdu characters. The experiment shows significant performance gain by OCR-AlexNet and OCR-GoogleNet of about 96.3% and 94.7% average recognition rate respectively.AlexNet is a winner of ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012, becoming the first deep learning model to do so with top-5 test error rate of 15.3%. The network consists of 8 deep layers trained with 10000 classes of ImageNet dataset. The implemented OCR-AlexNet architecture has minor differences to AlexNet for customization. The last three layers of AlexNet consist fully connected layers, with the final layer used for a 1000-label classification task. The network takes input images of 227*227 pixel. Each of the fully connected layers consists of 4096 neurons, chances of overfitting is reduced via Data augmentation and Dropout. Dropout is applied by setting zero to 50% of neurons during training. Adjustments are made to facilitate faster learning including the changes in fully connected layer’s size and learning rates. The architecture of OCR-AlexNet can be presented below.
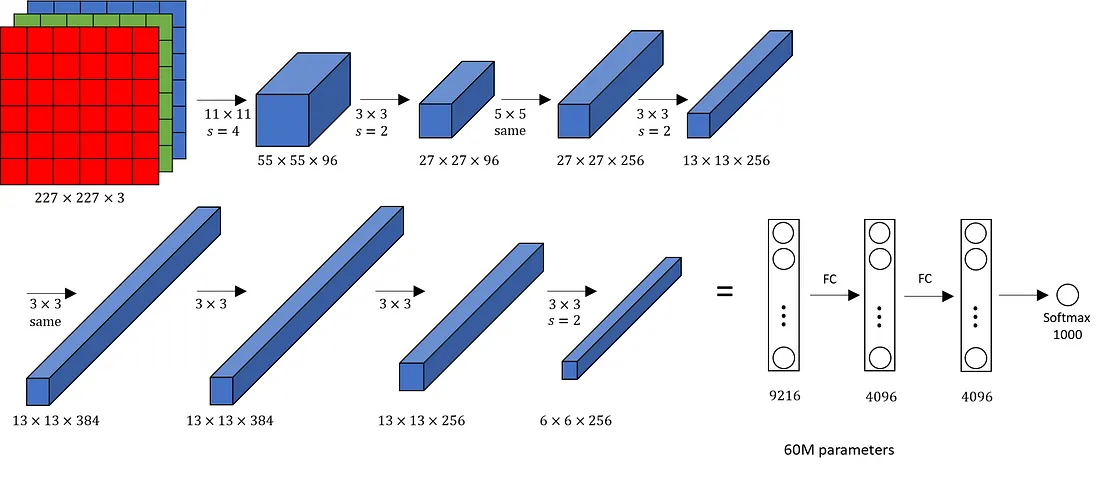
Figure 6; AlexNet Architecture
GoogleNet, also known as Inception-v1, is a deep convolution neural network which gained popularity by winning the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2014 with top-5 error rate of 6.67%. It is more complex with compared to AlexNet. GoogleNet consist of 22-layer deep neural network utilizing 9 unique inception modules unlike traditional CNN structures. These inception modules effectively capture local features by using various kernel sizes for computation, which are later combined together with upcoming layers. To adapt GoogleNet for Custom OCR, the researchers has fine tune it by keeping 4 inception modules and replacing the final two layers with new ones. Overfitting is prevented by freeing earlier layers’ weights and adjusting the learning rates.Thus, this method encourages rapid learning in new layers, slower learning in intermediate, and no learning in frozen layers (K.O & Poruran, 2020).

Figure 7; GoogleNet Architecture
In contrast to the other study, where end-to-end deep learning architecture are implemented, the author (Kumar, et al., 2023) has compared and experimented the commercially available OCR software for processing the text from Television and Video data. The study has analysed 3 differed OCR model’s performance over IAM Handwritten datasets and Complete Blood Count (CBC) datasets. IAM database consist of 14,892 photos of handwritten English lines of text by 657 authors, which is 1,539 handwritten pages and 115,320 words in total. The CBC datasets is gathered by researchers themselves from family and relatives which consist of 85 complete blood count printed reports. The three models Amazon Textract, Google Vision, and PyTesseract were tested on these two different datasets.
Amazon Textract: Aws Textract is a managed machine learning service that goes far away from traditional OCR in the task like recognizing and extracting data from forms and tables in addition to printed and handwritten text. The service also offers an API for image processing, providing flexibility to retrieve raw text in JSON (Javascript Object Notation) format or any other organized tabular layouts. For the IAM dataset, a simple API request is enough to obtain raw text, while for the CBC dataset, the available table detection feature streamlines the extraction of parameters and targeted values from the images.
PyTesseract: It is a widely used python module for text recognition in images build on the Tesseract Engine. It is compatible with various image formats, and incorporates preprocessing techniques such as image rescaling, binarization, noise reduction, normalization, morphological thinning, and deskewing to enhance accuracy. After preprocessing, the image is feed into the PyTesseract engine and it returns a textual unstructured response. And then it is formatted accordingly to both IAM and CBC datasets.
Google Vision: It is an AI-powered API by Google for image processing using REST and RPC APIs with pre-trained models that allows user to label images, recognize objects and text, and adds metadata to images saved in Google Cloud Storage. It do not have table extraction as Amazon does but provides word-centric responses based on block coordinates. In the IAM dataset, content retrieval involves combining information from the boxes in the same row to create sentences using a matching algorithm. As for the CBC dataset, with diverse sections and lines, the process involves identifying similar box coordinates for each line, assembling sentences, and extracting parameters and values.
Google Vision – It is an AI-powered API by Google for image processing using REST and RPC APIs with pre-trained models that allows user to label images, recognize objects and text, and adds metadata to images saved in Google Cloud Storage. It do not have table extraction as Amazon does but provides word-centric responses based on block coordinates. In the IAM dataset, content retrieval involves combining information from the boxes in the same row to create sentences using a matching algorithm. As for the CBC dataset, with diverse sections and lines, the process involves identifying similar box coordinates for each line, assembling sentences, and extracting parameters and values.
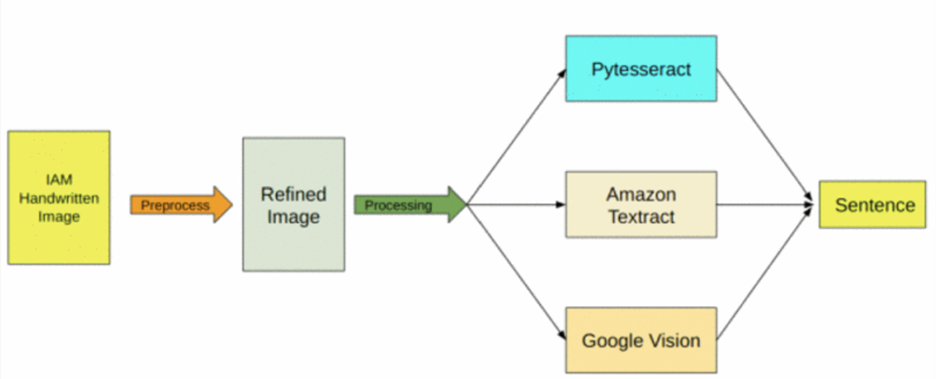
Figure 8; Implementing different models on IEM Handwriting dataset
In the study, the two metrics, Accuracy and Character Error Rate (CER) are used to analyze the model. The accuracy of each model for the IAM dataset was measured by the percentage of characters that were correctly detected and in case of CBC dataset, the accuracy is measured by how correctly the values of parameters are matching. Every character in the truth dataset is matched with the expected value in string matching.
On the other hand, the second metric, Character Error Rate (CER) is dependent on the quality and the content of the dataset and thus calculated using the equation below.
Here, S means the number of substitutions, D is the number of deletions, I refers to the number of insertions, and C is the number of correct characters. The lower the value of CER is, the better the performance of model is.
The final performance of all three models on the IAM and CBC datasets is presented below.
| Dataset | Metric | Amazon Textract | Google Vision | PyTesseract |
|---|---|---|---|---|
| IAM | Accuracy | 89.42% | 88.53% | 81.02% |
| IAM | CER | 0.1403 | 0.1621 | 0.2650 |
| CBC | Accuracy | 95% | 90.3% | 84.1% |
| CBC | CER | 0.1082 | 0.1332 | 0.2231 |
After testing the different models on the different datasets, Result indicates that the Model performs better in printed CBC dataset than Handwritten ones, likely due to consistent character formats in printed text. Amazon Textract demonstrated superior performance compared to Google Vision and PyTesseract, with preprocessing techniques further enhancing model accuracy. It also achieved the highest accuracy of 95% and the lowesr CER of 0.1082 for CBC blood reports with preprocessing. The study suggests that performance of OCR engine heavily depends on datasets and model training.
As the motive of this project is to develop Optical Character Recognition system (OCR) which is dependent on the Deep learning techniques. It has complex architecture in the background. This architecture is designed in such a way that it takes images of size 96*1408 with its corresponding label while learning. There is series of convolution layer for extracting the pixel value and learning the image content. It is connected with Sequential model where it learns the label text of corresponding images by mapping. For handling Images there is 9 residual blocks. Residual block is the architecture developed by google in its inception-v1 model. Each residual block has Convolution layer, Pooling, Dropout, and it is repeated 3 times by connecting with each other. At the end the input layer is itself multiplied with the final convolution layer, therefore this is also known as skip-connection architecture. For Sequence modelling, I have used two different architectures depending on the language model. For English Model, there is LSTM (Long-Short term Memory) and for Devanagari Model, there is GRU (Gated-Recurrent Unit). This is because, English datasets is larger than Devanagari datasets, but the Devanagari datasets is much complex than the English one. Before feeding data to the model, it goes through different process and the crucial step is given below.
The CRNN (Convolutional Recurrent Neural Network) architecture is highly preferred option for the the tasks such as Optical Character Recognition (OCR). This architecture integrates Convolution Layers (CNN) to extracts spatial information from the input image and maps it with the corresponding sequential data by dealing with the sequences of varying lengths. The Recurrent Layers (RNN), such as Bidirectional - Long Short-Term Memory (Bi-LSTM), Bidirectional - Gated Recurrent Unit (Bi-GRU), analyses the order of elements in a sequence, enabling a deeper understanding of the sequential patterns of data. The integration of Connectionist Temporal Classification (CTC) loss further strengthens the CRNN architecture. This facilitates end-to-end training by empowering the model to learn and directly predict the character sequences from the input image data. This eliminates the need for explicit alignment between input images and ground truth text. In addition to streamlining the training process, it also enhances model performance significantly. Thus, the CRNN architecture has emerged as a highly adaptable framework, which outperforms many other methods at extracting features, modelling sequences, and recognizing characters. This characteristic makes it one of the best options for building our own OCR system using deep learning techniques. There are two different variants of CRNN which is being used in the project: one for English model and another for Devanagari model.
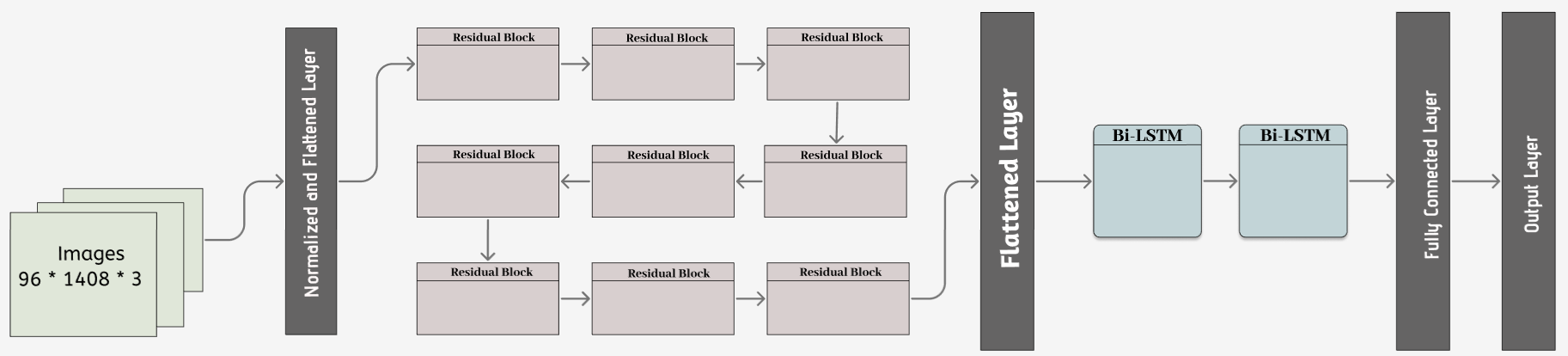
Figure 9; Architecture for English Model
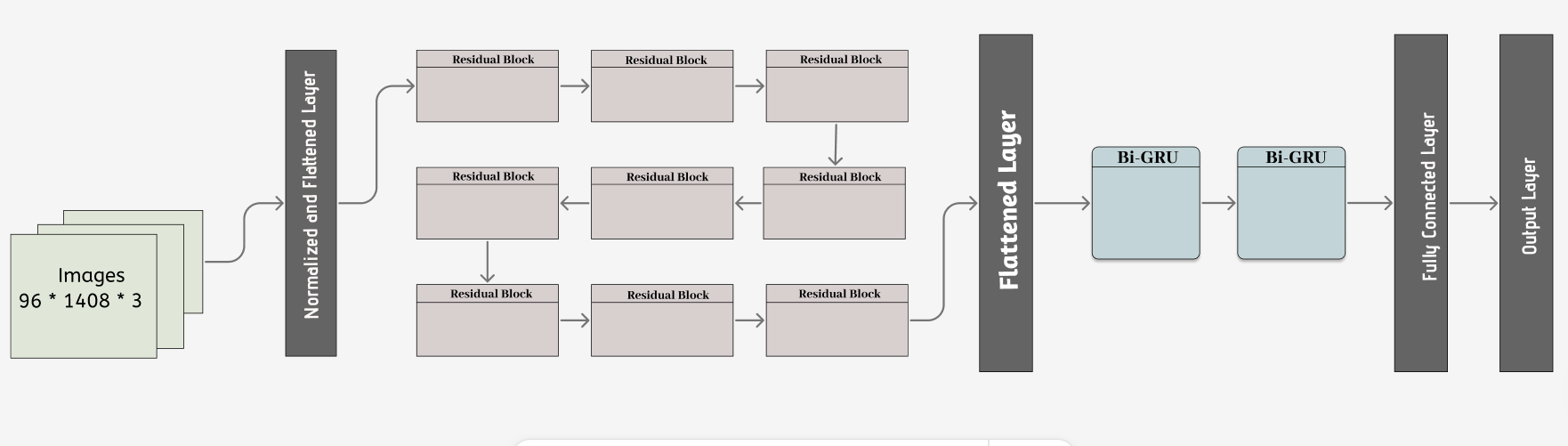
Figure 10; Architecture for Devanagari Model
The common things in both the architecture are:
1.Input layer: The height and width are reshaped to 94 x 1408 to both English and Devanagari images. As we know, the model is being trained with line base images with its corresponding label, height is slightly low then the width of the image.
2.Dense Layer: It is a type of Artificial Neural Network (ANN) layer where each neuron in the layer is connected to every neuron in the preceding layer. This is why it is also known as Fully Connected Layers. It performs a weighted average, on the input data, and activate to the result of weighted average to introduce non-linearity into the network. This allows model to learn complex patterns in data during training process.
3.Residual Blocks: The concept of a residual block originated due to the problem of vanishing gradient, that are particularly encountered while training deep neural networks. They were introduced in the paper of ResNet architecture as a skip-connection blocks which can learn residual functions by directly maping to the final reference of convolution layer. This means that instead of learning the desired underlying maping
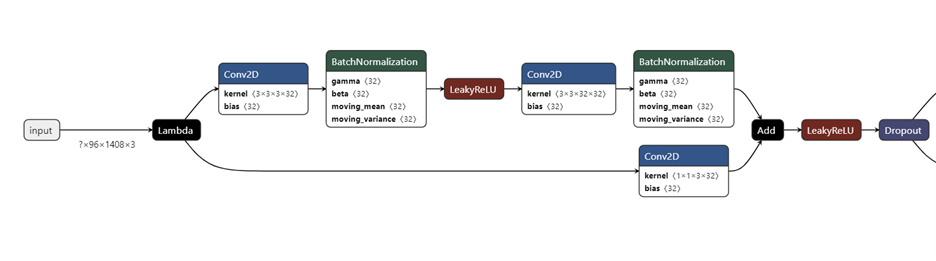
Figure 11; Residual block
The figure above shows the first residual blocks of our architecture. At first input is normalized and squeeze, which is denoted by Lambda. Then it goes pass through
1.Conv2D with kernel size <3 x 3 x 3 x 32>: This represents a Convolution 2D layer with a kernel height and width of 3 x 3 and a depth of 3, which represents RGB color channel. The 32 at the end indicates that there are such thirty two kernels in this layer, each producing its own output feature map.
2. Batch Normalization: Batch Normalization is a technique for normalizing the activation of each layer in a neural network. It is very helpful in reducing the internal covariate shift, which stabilizes and speeds the training process.
3. Leaky ReLU Activation Function: The Leaky ReLU Activation function is a variant of the Rectified Linear Unit (ReLU) activation function. The difference is Leaky RelU introduces a small slop, typically a small positive value like 0.00001 for negative input values allowing a small or non-zero gradient when the input is negative. This helps to overcome dying ReLU problem, which could make neuron dead during training.
ReLu activation function is defined as below.
It returns 0 for any negative input value and return input value itself for any positive value.
And Its derivative is as follow.
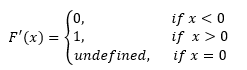
Leaky ReLU has make difference by introducing following small alpha(α) value.
Its derivatives is as follow.
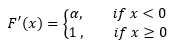
The graph of ReLu(x) and Leaky ReLu looks like belows

Figure 12; ReLu vs Leaky-ReLU
4.Output Layer: This is the final layer of the architecture, that produces the output predictions of the model. The structure and activation function of the output layer is dependent on the nature of the task that is trying to be addressed. In our case, the output layer has neuron according to the unique vocab available in the datasets. For example, English model architecture has 93 neurons in Output layer because there are 93 unique character and sign such as like comas and slashes and Similarly, Devanagari model has 90 neurons in Output layer. The activation function used in our Output layer is
The difference in the architecture is in sequence modelling. The English model uses Bidirectional-Long Short-Term Memory (LSTM) but the Devanagari model contains Bidirectional-Gated Recurrent Unit (GRU). This is because English model has a lot of training data, and complex label. So, during hyperparameter tuning LSTM architecture was doing great work. But Devanagari datasets is not big as IAM handwriting, and the Devanagari character is much more complex than English character. So, Gated Recurrent Unit (GRU) was converging and doing much better than LSTM, and ultimately, I have modified the architecture to GRU. Below, we will detailly explored the Bi-LSTM and Bi-GRU architecture.
Annotation and symbols for understanding LSTM and GRU
The above symbols will be used further to understand the calculation of the Sequential Model.
Bi-LSTM is a Recurrent Neural Network (RNN) which is used to process sequential data like text and sounds, where the current output is depended on previous output. It stacks multiple Long-Short Term Memory (LSTM) to reverse the direction of the flow of information. Before describing Bi-LSTM architecture, lets understand the simple LSTM architecture

Figure 13; LSTM Architecture
The LSTM architecture consists of forgot gate, input gate and output gate. These gates are designed to regulate the flow of information through the Cell. It allows the LSTM to selectively update its and memory and also decide which relevant information to be kept or which to discard.
1.Forgot Gate: The forgot gate takes the current input and the previous hidden state as inputs and computes the forgot gate vector
2.Input gate: The input gate determines how much of the new information should be added into the cell state. It takes the current input and the previous hidden state as inputs and computes a gate vector it is using a sigmoid activation function, which controls the flow of new information into the cell state.
3.Output gate: The output finalize how much of the cell state should be incorporated to the next hidden state. It also takes current input and the previous hidden state, candidate hidden state as input and passes them to the sigmoid activation function. Additionally, the cell state Ct is also passed through tanh activation to produce value between -1 and 1. And finally, the output gate combines the sigmoid gate values and the tanh values to produce the final hidden state
Mathematical Operation
Input Gate Operation
Forgot Gate Operation
Output Gate Operation
Candidate State Cell
Cell State Update
Hidden State Output
Bi-LSTM adds two LSTM layers to flow the information from both the direction and and combine their output. The figure of Bi-LSTM is presented below.
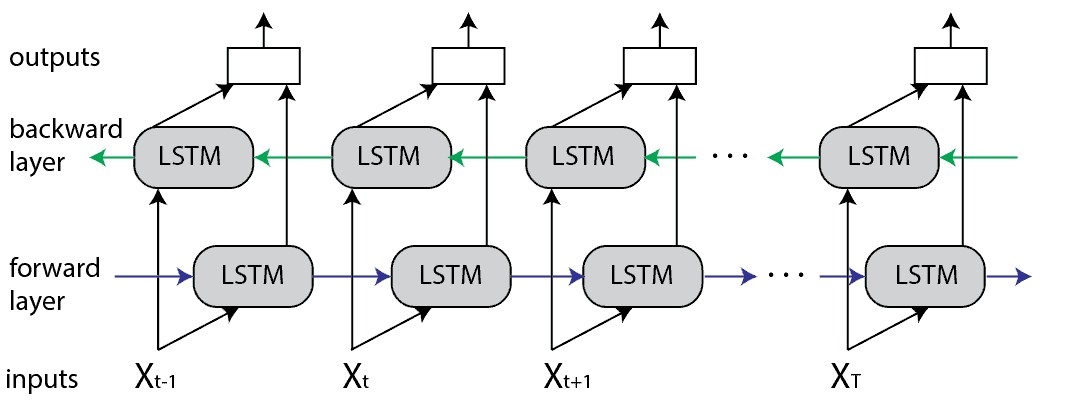
Figure 14; Bi-LSTM Architecture
The forward LSTM processes the input sequence from left to right and the backward LSTM processes it from the right to left. Like we see earlier, Each LSTM cell in both directions maintains a hidden state and a cell state to capture information from the input sequence. The forward LSTM captures information from past tokens in the sequence, while the back LSTM captures from future tokens. By processing the input sequence in both forward and backward directions, the Bi-LSTM can capture information in bidirectional context.
Like Bidirectional LSTM, Bidirectional GRU is another variant of RNN which we have used in Devanagari architecture. It has also stacked multiple Gated Recurrent Unit (GRU) to reverse the direction of the flow of information. Single unit of GRU architecture is presented below.

Figure 15; GRU Architecture
GRU also maintains a hidden state
1. Update Gate: The update gate determines how much of the previous hidden state should be retained and how much of the current input should added into the new hidden state. It passes current input and the previous hidden state though a sigmoid activation as input.
2. Reset Gate: The reset gate determines how much of the previous hidden state should be forgotten. It also takes current input and previous hidden state as input and passes them through sigmoid functions.
Mathematical Operation
Update Gate Operation
Reset Gate Operation
Candidate Hidden State
Final Hidden State Update
Same as Bi-LSTM, Bi-GRU adds two GRU layers to flow the information from both the direction and and combine their output. The figure of GRU is presented below.
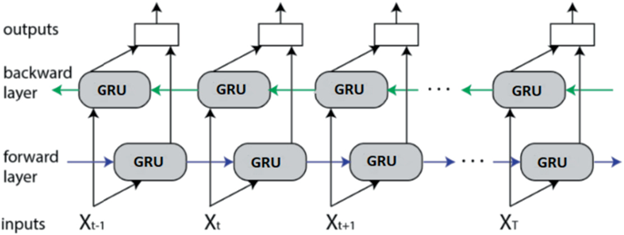
Figure 16; Bidirectional-GRU Architecture
The forward GRU processes the input sequence from left to right and the backward GRU processes it from the right to left. Each GRU cell in both directions maintains a hidden state and a cell state to capture information from the input sequence. The forward GRU captures information from past tokens in the sequence, while the back GRU captures from future tokens. By processing the input sequence in both forward and backward directions, the Bi-GRU can capture information in bidirectional context.
One of the reasons why Neural Network architecture outperforms traditional Machine learning algorithm is its tendency to learn better with the large datasets. Deep learning architecture are designed to feed huge volume of data. For training our system with English and Devanagari language, which need to have two different variants of data. One is English datasets, and another is Devanagari datasets. Each datasets have Image containing the text and Corpus with corresponding textual document of an image. For training the English Model, I have collected IAM handwriting datasets. This dataset is publicly available with certain credential by Research Group on Computer Vision and Artificial Intelligence at University of Bern. While Devanagari datasets isn’t available in desired form. I have collected the Bhagwat Geeta, a popular scripture images and labelled it manually. The detailed description of each dataset is below.
1. Datasets for English
The IAM online handwriting dataset is around 7GB in size. It contains handwritten images with corresponding labels in txt file. It provides data in three forms: Full scale image, Sentences based image, Line based image and Word-based image. Full scale image is contained in three directories: formsA-D, formsE-H, and formsI-Z. Each full scale image under forms directory is made with the combination of form id and writer id. The sentence directory contains sub directory of form id, form id has sub directory of writer id, and inside writer id there is sentence based segmented image of each form, full scale image. Like sentence data, line directory also has subdirectory of form id, form id itself has subdirectory with writer id and writer id contains the line based segmented image of each form. Word directory also contains subdirectory of form id, form id has subdirectory of writer id and writer id directory contains separate image for each word that is contained on full scale image. With compared to sentence and line image, word image can be little big because word and sentence itself contains many words, and for each word there is different image. There is also optional xml directory if we like to work with xml files.
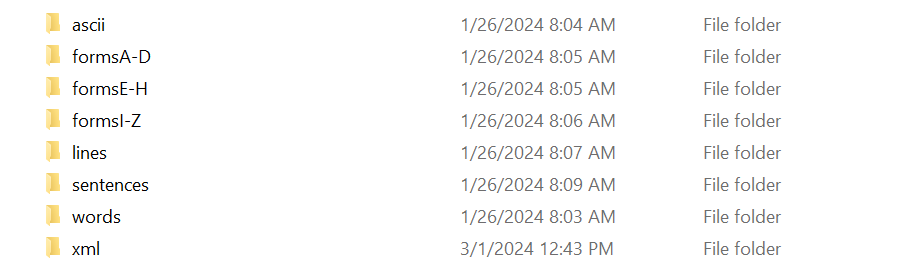
Figure 17; Directory of datasets
The directory ‘ascii’ contains corresponding text label of all the forms, lines, sentences, and words. There are four text file each representing text, error status, and bounding box for corresponding images in forms, lines, sentences, and words.
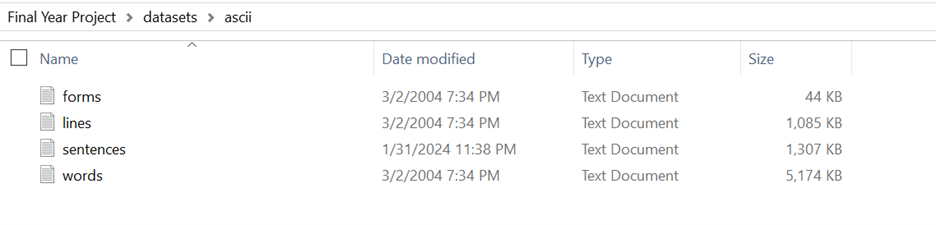
Figure 18; Corresponding annotation for IAM datasets
2. Datasets for Devanagari
The indian phylosophical scripture bhagwat geeta datasets is prepared for Devanagari model is prepared manually. I collected the images from online source, and then utilized tools like online orc to get the textual content and online Devanagari typing tools to correct the error of labelled text. And then, I have written algorithm that will iterate over each image and text, tokenize each line of image with corresponding line in text file. There are altogether 3400+ line base image. The size of Devanagari datasets is quite low compared to English datasets, but the complexity is pretty much high. This Devanagari datasets is in Hindi and some sort of Sanskrit language. The actual sloka is in sanskrit and its corresponding interpretation is in Hindi.
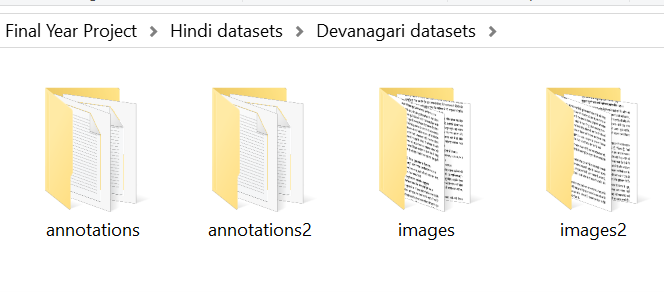
Figure 19; Devanagari directory
Data cleaning is a crucial step for preventing data integration issue. We need to verify whether the corresponding label of training and validating images is correct or not. For English language model, if there is labelling issue, the tag of ‘err’ is given and thus we can ignore that line and if there is no error, the tag of ‘ok’ is given. But for Devanagari data, I have manually automated the task of segmenting each line as region of interest (ROI) with corresponding labels. Some time, region of interest (ROI) could not be capture but its corresponding label will be available, and it will be assigned to other images. This can create label mismatch problem. Therefore, I have manually checked and ensure region of interest (ROI) is perfectly captured for every line of and images. Sometimes, small dots, lines can also make confuses to edge detection algorithms, so some height and width is also given for the confirmation of valid text. If any of the criteria is not fulfilled, then the images is discarded.

Figure 20; Detecting ROI for extracting text
To build a generalize model; a model that can work good on diverse set of data, and reduce overfitting, data augmentation is very popular and useful techniques. It helps to increase the size and variety of our datasets. This technique applies transformation like Random Rotation, Random scaling, Image translation, Random Brightness and adding noise to the data. Each of these techniques is explained below.
1.Random Rotation: This is a process of rotating the images by a random angle for enabling the OCR system to recognize characters at different orientations. I have implemented random rotations in data augmentation steps with the angle range of -10 to 10 degrees.

Figure 21; Rotated image
2.Random Scaling: Random Scaling is another technique for diversifying the training data. It includes resizing the line images with certain scale factor, so that our model learns to recognize character of different sizes. I have used the scale factor of 0.3, so that random scaling with range between 0.7 and 1.3.
3.Random translation: Random image translation is used to randomly shift the image horizontally resulting in new variant of image with the change in position of content. The position of the textual part of the image will change it position and the padding will be applied to the current empty space. This technique is combinedly applied with the other data augmentation techniques.

Figure 22; Random image translation
4.Random Brightness: This is very rare that model will always get same light, brightness every time. It is very crucial to consider different images containing different levels of brightness. Some images would be lighter than others, some may be little darker than others. Model should be ready to adopt and work on this. So, random brightness is applied with a factor of 0.4, which will result between 0.6 and 1.4.
5.Adding Noise: While processing images in the real world, this is not sure that every of them will be very clear and sharp. So, the model needs to be trained for working on disrupted images, where some pixel values are not clear as others. So, adding noise is a good option which we can use for making generalize learning.

Figure 23; Adding noise in image
1.Sharpening: Image sharpening is a technique for making image look concise and clear by enhancing the edges, brightness and contrast of a image. It helps to improve the quality and readability of images by minimizing the factor like blur, noise which may came with the factor like low camera, camera shaking during snapshot, low resolution, and compression. It works by increasing the distance between pixel value of near the boundary’s areas. It can sometimes create over sharpening issue, so we I have used appropriate clipping value to prevent the overflow of pixels information.
2. Grayscale conversion: A gray-scale image is one which has single color channel. Normally, the image is composed of three-color channels, red, blue, and green. Each of these color channels has pixel value ranging from
3.Binarization and thresholding: This method is used in the project for converting grayscale images into black and white images, also known as binary image. I have binarized the image using the global threshold method. First, the global threshold value is determined, and find out whether the pixel has gray value greater than given threshold or not. If the pixel value is greater than threshold, it will be converted to 1 and if the pixel value is less than threshold, it is assigned to 0. Here, 1 represents white and 0 represents black. It will simplify the process by representing the data in binary form.
4.Dilation: Dilation expands the size of an object by convolving the image with a structure element. A small binary image or matrix is used as structuring element to define the neighborhood of a pixel during dilation process. The shape of the binary image will determine the degree to dilate.
5.Erosion: Erosion shrinks the size of an object by convolving the image with structure element. After convolving the object, it returns the result of erosion operation as a new image where the pixels value of image is shrunk, also known as eroded.
The popular metrices that is used to evaluate the performance of the OCR model are CER (Character Error Rate) and WER (Word Error Rate). We have monitored the performance of both Model using Tensorboard. The following figures shows the different metrices to evaluate the model.
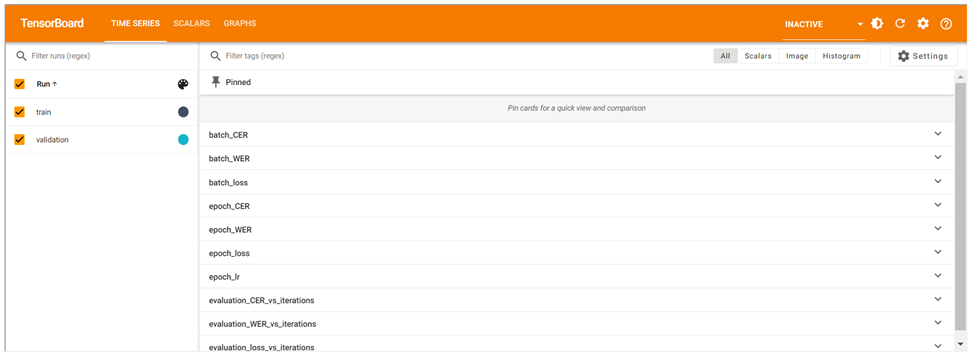
Figure 24; Tensorboard for Monitoring Models
We can understand the above figure in three parts. First three metrics shows the performance of model during training time, Last three metrics shows the performance of model during validation and middle three metrics is the comparison between training and validation performance in different steps.
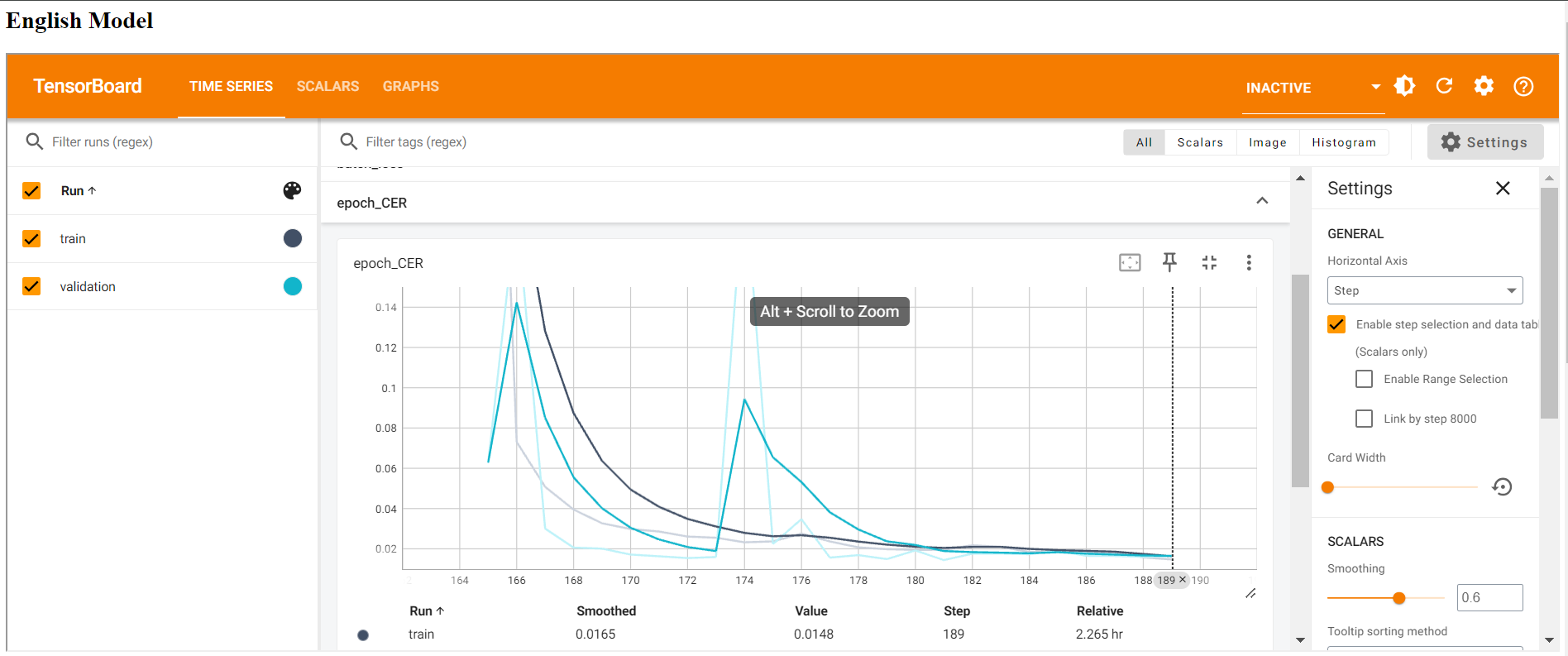
Figure 25; Training vs Validation CER (Character Error Rate) for English Model
The above graphs shows that CER of validation is moving along with the fall of CER in training time.
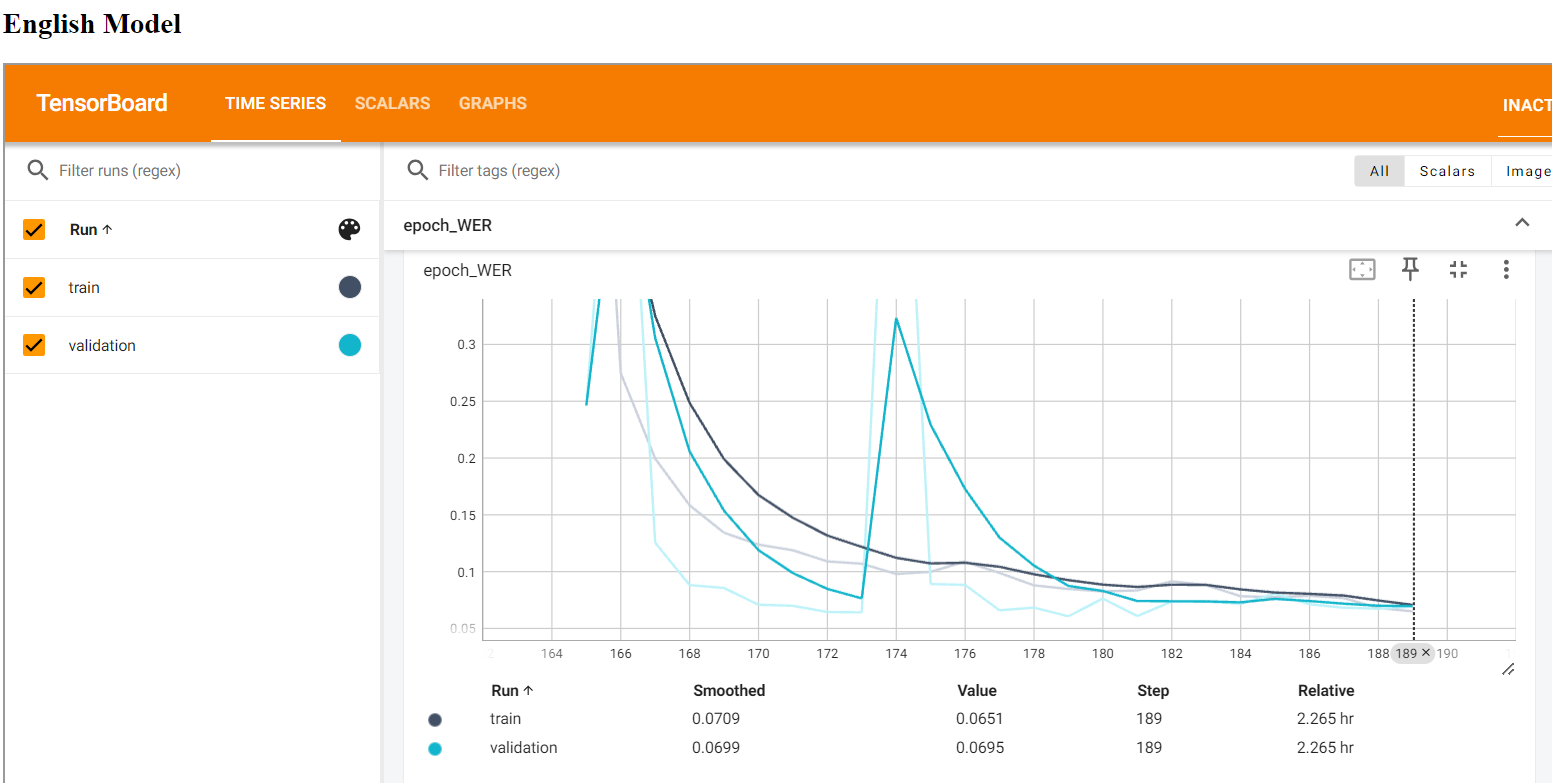
Figure 26; Training vs Validation WER (Word Error Rate) for English Model
The above line plot also shows that word error is falling when we keep training the model.
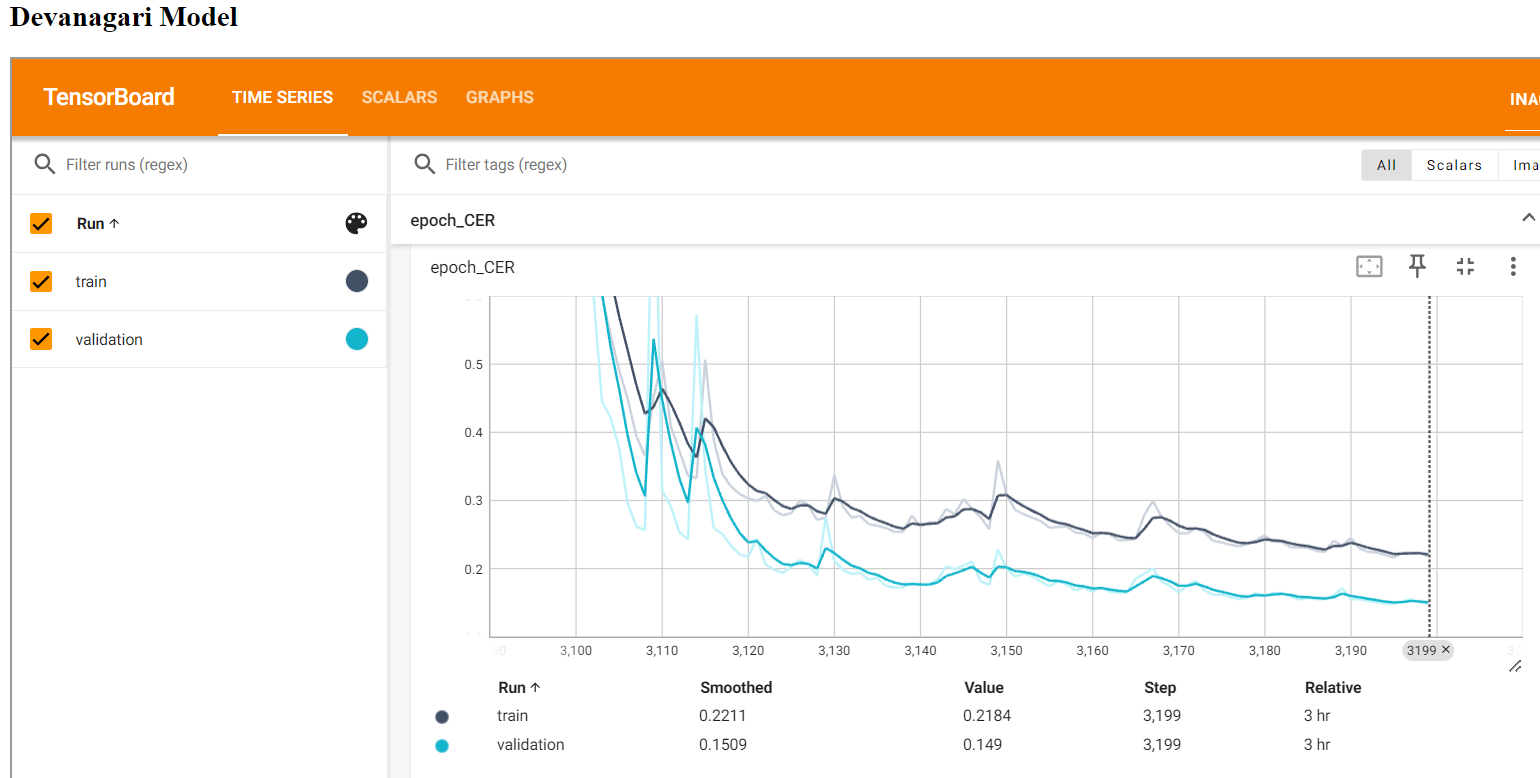
Figure 27; Training vs Validation CER (Character Error Rate) for Devanagari Model
The above graph shows how validation CER of Devanagari Model is Falling with time.
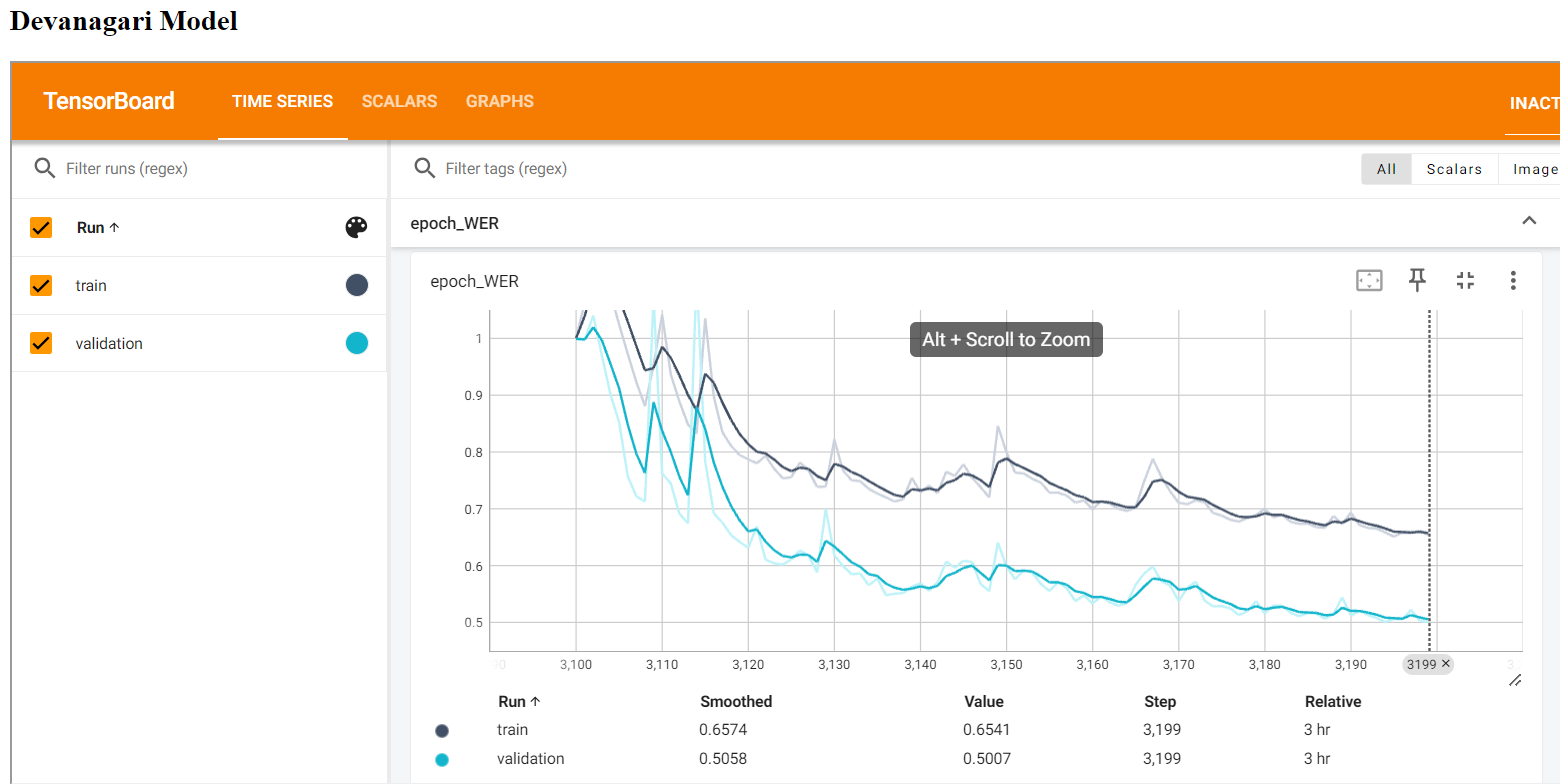
Figure 28; Training vs Validation WER (Word Error Rate) for Devanagari Model
The above figure shows more we train the model , WER will also fall accordingly.
| Model Name | CER | WER | Loss |
|---|---|---|---|
| English training | 0.01001 | 0.0800 | 1.566 |
| English testing | 0.01005 | 0.0955 | 1.738 |
| Devanagari training | 0.1000 | 0.3578 | 30.456 |
| Devanagari testing | 0.13162 | 0.4494 | 35.3282 |
In this section, I will discuss the deployment of the OCR model for general users. The application leverages the Django Rest Framework for backend API development, Vanilla JavaScript for frontend interaction, and SQLite as the default database for storing information.
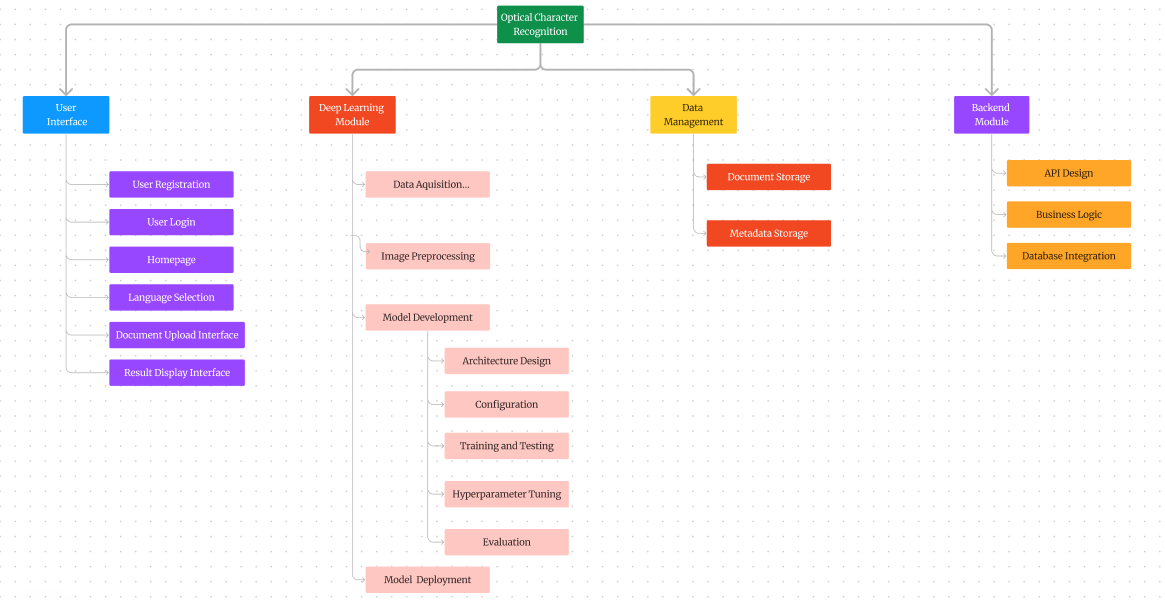
Figure 29; Functional Decomposition Diagram
In the above FDD, I am have splited the system into four parts i. e. ,User Interface, Deep Learning module, Data Management and Backend module. The sections make a modular view of the related functionalities, which when put together form an entity of the programme. By viewing this illustration we would be able to investigate the levels of the system, the interconnections as well as the relationships of the project. This awareness is indeed crucial for an adequate planning and decision-making process throughout the project complex lifecycle.
1. User Interaction
i) Image Upload: Users can upload images that they want to process.
Figure 30; Uploading image
ii) Image Editing: Users have the option to edit the images as needed.
Figure 31;Option for editing uploaded image
2. Language Selection
Users select the language of the document, which determines which model will be used on the backend.
Figure 32; Selecting language according to documents
3. Edge Detection
Users identify the Region of Interest (ROI) in the image. They have three options for edge detection algorithms to choose from.

Figure 33; Edge detection
4. Text Prediction
After selecting the appropriate edge detection algorithm, the model processes the image and predicts the text.
The predicted text is displayed in a text box, allowing users to:
i) Copy the text.
ii) Export it in .txt or Word format.
This deployment strategy utilizes a modular architecture, ensuring that each component functions effectively while contributing to the overall performance of the OCR application. This structure not only enhances user experience but also supports scalability and maintainability of the system.
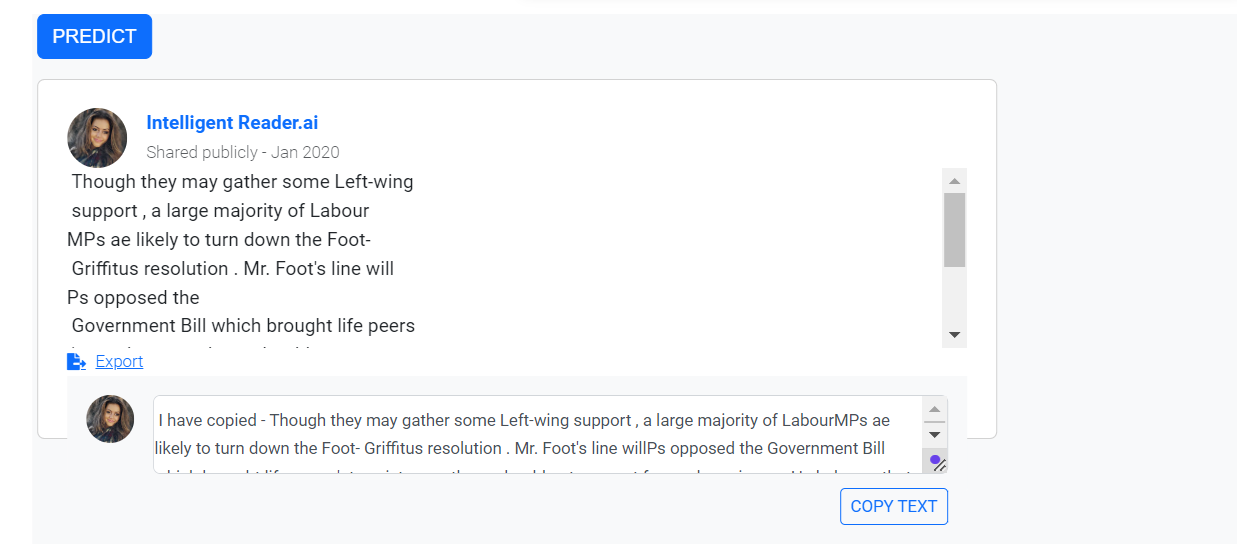
Figure 34; Text Prediction
The primary aim of this work was completed through research and developing an OCR designed to decipher images with text in both the English and the Devnagari languages. The specific tasks were to apply the methods of deep learning to create the OCR system from the ground up, ensure the model familiarizes with the concept of UI, and compare the results with the real performance of the OCR systems. The particular academic questions that were being investigated earlier in this paper include understanding the limitations of existing OCR systems, the causes of varied performance of an applied language, and the steps that should be taken in developing a general OCR engine.
The major conclusions and findings that can be made throughout the course of this projects are the following. The challenges we faced during the development of the multilingual OCR system from scratch helped us to understand which factors have a major impact on the error rate, in particular: resources: easy access to large variety of training data; computational constraints; dealing with multiple languages. The OCR model that was trained with the help of deep learning and that was developed specifically for the application could recognize not only the English language but also Devanagari despite the fact that the comparison with generic OCR services was employed. The incorporation of the OCR model with the user-friendly interface made the entire process of text information extraction from documents ideal for both laypersons and experts with relative ease.
I also identified the problem associated with the current OCR and the solution I want to suggest is Intelligent Document processing. This method involves combining Machine learning for understanding predefined sets of rule in the text document like margin, table, border, signature and many other things. Another issue that comes up is the availability of training data, the more data we have we can build better OCR. We have also observed that OCR would not have same level of performance in different languages because, there architecture may vary, resources are imbalance and the complexity of different languages are also identical.
1.Abisado, M., Imperial, J. M., Rodriguez, R. & Fabito, B., 2020. Doctor’s Cursive Handwriting Recognition System Using Deep Learning. Manila, ResearchGate.
2.Biró, A. et al., 2023. Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Applied Sciences, 13(7), p. 4419.
3.Cristiano , C., 2020. For a Science-oriented, Socially Responsible, and Self-aware AI: beyond ethical issues. In: 2020 IEEE International Conference on Human-Machine Systems (ICHMS). IEEE, pp. 1-4.
4.Dey, R., Balabantaray, R. C. & Mohanty, S., 2022. Approach for Preprocessing in Offline Optical Character Recognition. Bhubaneswar, IEEE.
5.Huang, J. et al., 2021. A Multiplexed Network for End-to-End, Multilingual OCR. s.l., IEEE.
6.K.O, M. A. & Poruran, S., 2020. OCR-Nets: Variants of Pre-trained CNN for Urdu Handwritten Character Recognition via Transfer Learning. Procedia Computer Science, 171(1877-0509), pp. 2294-2301.
7.Khan, A. A. et al., 2023. AI Ethics: An Empirical Study on the Views of Practitioners and Lawmakers. IEEE Transactions on Computational Social Systems, Volume 10, pp. 2971-2984.
8.Kumar, A., Singh, P. & Lata, K., 2023. Comparative Study of Different Optical Character Recognition Models on Handwritten and Printed Medical Reports. 2023 International Conference on Innovative Data Communication Technologies and Application (ICIDCA), 20 04, pp. 581-586.
9.Memon, J., Sami, M., Khan, R. A. & Uddin, M., 2020. Handwritten Optical Character Recognition (OCR): A. IEEE Access, Volume 8, pp. 142642-142668.
10.Muneer, S. U. a. N. M. a. K. B. a. Y. M. H., 2020. Evaluating the Effectiveness of Notations for Designing Security Aspects. pp. 465-471.
11.Sayallar, C. ̧. a., Sayar, A. & Babalık, N., 2023. An OCR Engine for Printed Receipt Images using Deep Learning Techniques. International Journal of Advanced Computer Science and Applications, 4(2).
12.Sethu, S. . G., 2020. Legal Protection for Data Security: a Comparative Analysis of the Laws and Regulations of European Union, US, India and UAE. 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), pp. 1-5.
13.Yu, . W., Ibrayim, M. & Hamdulla, A., 2023. Scene Text Recognition Based on Improved CRNN. Information, 14(7), p. 369.