
This is a Multi-Agents Agentic AI system that drafts a very simple research on a topic that the user provides based information from the internet with the ability to provide external resources (txt or pdf docs in the data folder) for the system to consider while conducting the research.
The System follows a parallelized architecture with the topic split into smaller subtopics to be searched and summarized independently, then the summaries from all those subtopics are merged and summarized into a final research.
The system uses a summarizer-critic loop for each summarization process.
The system uses the LLM whose API is available for these three options : OpenAI, Google , and Groq (in that order).
The purpose of this project is to code a multi-agents agentic AI system that helps drafting a research by just giving it the short main topic you want, that draft could be like a starting point for the user to improve and it can save a lot of time, it's also a way to showcase the skills learned in the Mastering AI Agents course.
The project consists of two main folder, src/ and data/
The data folder contains the external resources given by the user (optional), and those can be either pdf or txt files.
The src folder contains the source code for the project, which are main.py , tools.py, vectordb.py, prompts.py , nodes.py , build_graph.py and output_structures.py.
main.py is the main file which takes an input and invokes the system.
tools.py contains the tools used by the system, which are RAG retrieval, File Parsing, and Tavily web-search tool.
vectordb.py contains the implementation of the vector database, which is used to chunk and store the external resources in the data folder for using RAG Retrieval later.
prompts.py contains the prompt templates
output_structure contains the pydantic scheme for the output of some LLMs in the system
nodes.py contains the agents (nodes) of our system
build_graph.py defines the graph and connects the agents (nodes) according to a parallelized architecture
The project's GitHub repo:
https://github.com/Haydara-Othman/Mastering_AI_Agents_Project
The repository has a .env.example file with the names of the required environment variables ( like the APIs or the choices for models to use ).
A .env file with those environment variables names and their true values must be created.
The repository also has a requirements.txt file which contains the important dependencies.
To install the required libraries and dependencies, run the following code:
pip install -r requirements.txt
After creating the .env file and putting your APIs and Model choices in it, the project is ready to run.
The code won't work without installing the dependencies and setting up the environment variables.
It is crucial to run the command above to install all required libraries and dependencies, and to put your APIs in the .env file.
The data folder can be filled with external resources (pdf or txt files) if the user wants to add some files from his own for the system to consider and take information from.
Those documents will be chunked, embedded and added to a vector database. The system will use RAG Retrieval later to retrieve the relevant information.
The graph follows a parallelized architecture, just like in the photo below :
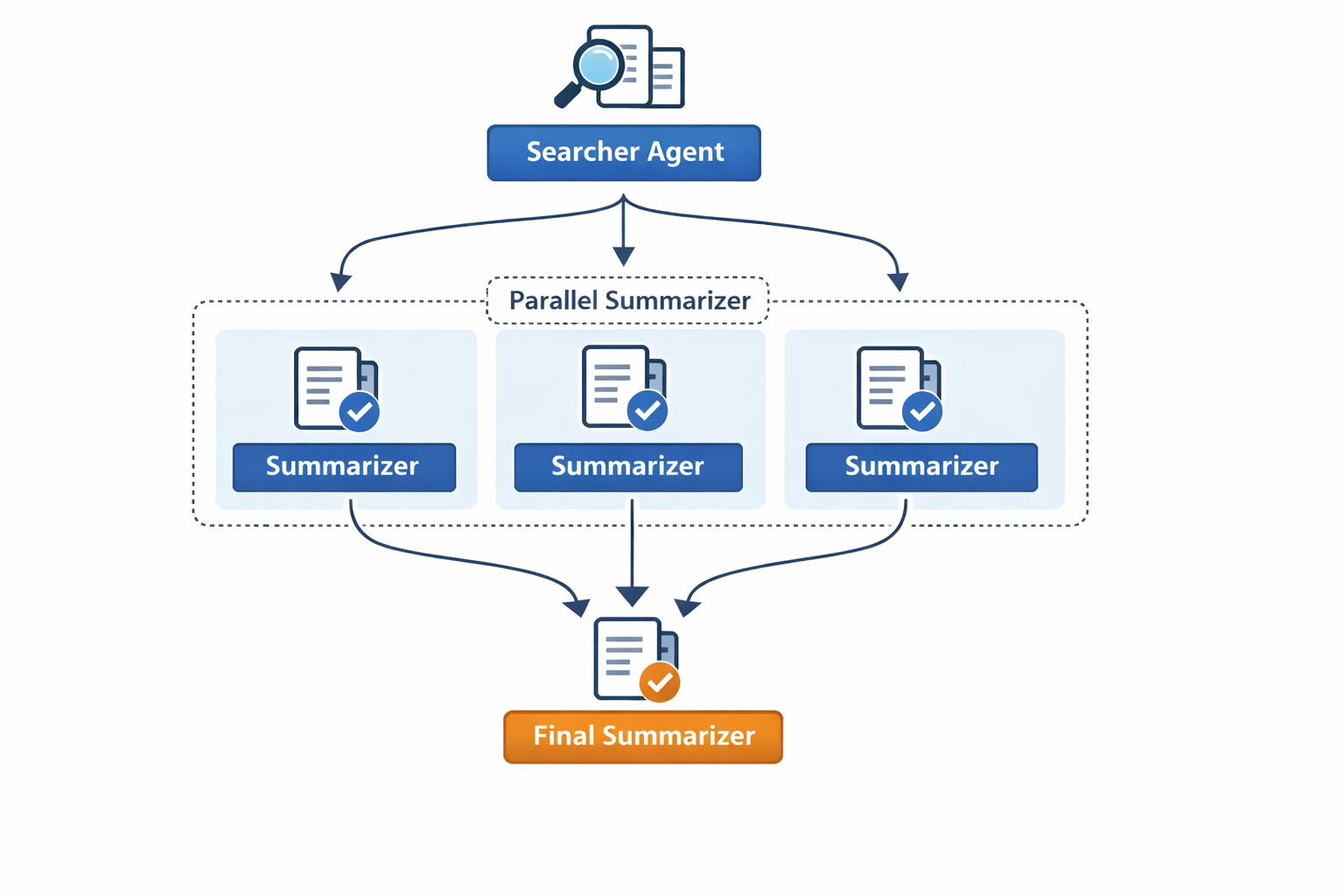
The system consists of three main agents: Searcher, Parallel Analyzer, and Final Summarizer
The Searcher takes the topic and splits it into different subtopics regarding the different aspects and information about that topic, then uses the Tavily tool which searches the internet for information about each of those subtopics. If there exists external documents added by the user, then the vector database is searched too.
The Parallel Analyzer takes the information about each subtopic and summarizes it into a summary, in a parallel branching way . Then, the summaries are revised by a critic which gives its approval and opinion of each one of those subtopics, if one of them wasn't approved, then the summarizer summarizes it again.
The Final Summarizer takes those sub summaries and summarizes them once more into a final result, with a critic giving its opinion on what should change if the summary wasn't approved.
As we said above, each summarizer agent (parallel or final summarizer) uses a summarizer-critic loop architecture, as in the following photo :
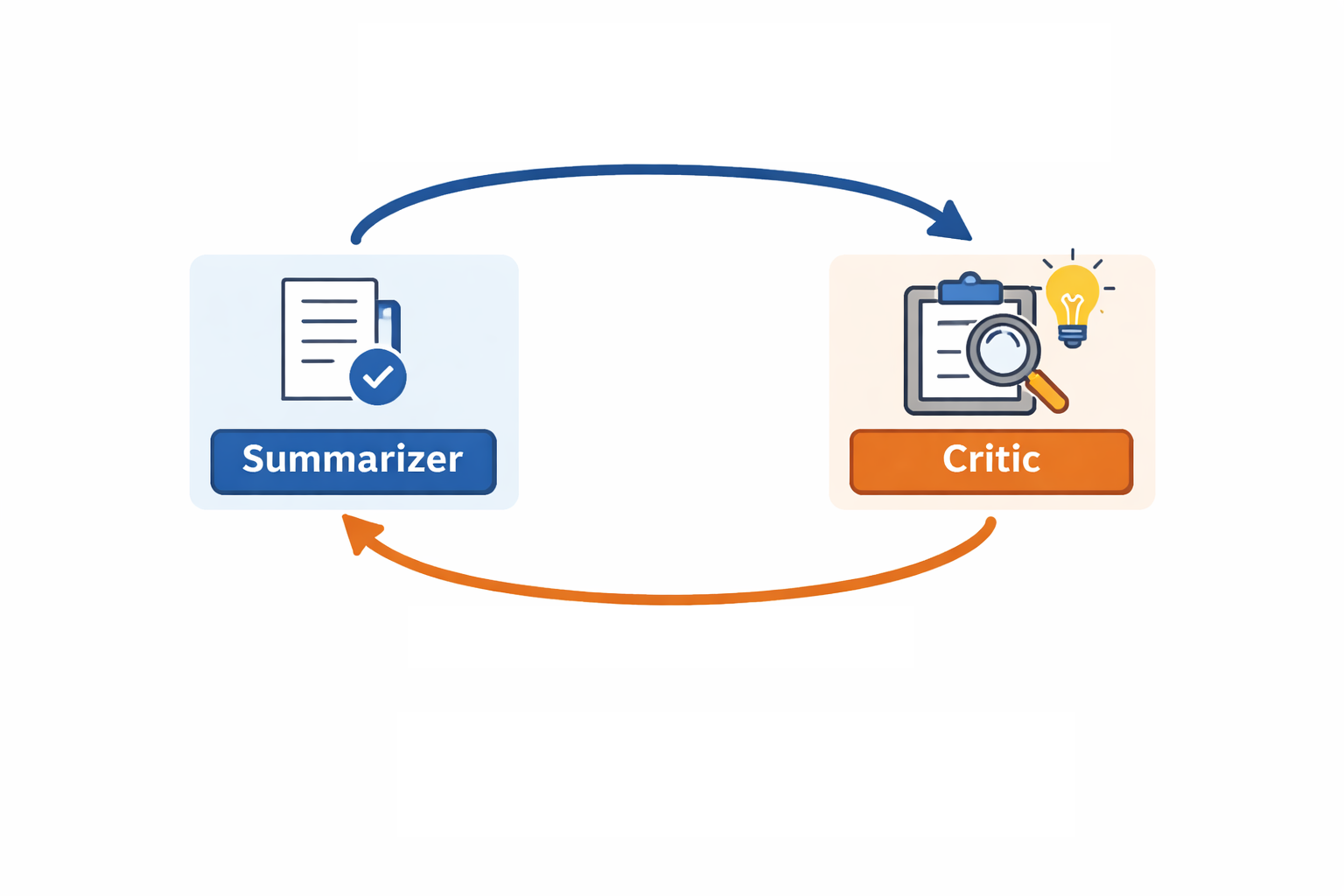
This loop architecture makes sure to remove as many mistakes from the summarizations as possible.
Now we explain each code file in the src folder :
This is the main file that should be run using :
python src/main.py
it defines an initial state for the system, and runs an infinite loop where it takes the topic from the user and runs the agent. The system can be shutdown by entering 'quit'.
Notice the
result = asyncio.run(agent.ainvoke(init_state))
instead of a simple agent.invoke...
That is because we are using asyncio to parallelize the summarization process of the different subtopics in the Parallel Summarizer agent, we'll explain that later when we explain the nodes.py file.
this one contains all the agents (nodes) of our system, The Searcher, The Parallel Summarizer, and The Final Summarizer.
It first initiates an LLM ( OpenAI or Google or Groq ) based on available API keys in the .env file in that order and defines the state of the graph.
Then it defines each of our agents:
def Searcher(state): print("[Searcher] starting") print(f"[Searcher] main_topic = {state['main_topic']!r}") response = searcher_chain.invoke( state['main_topic'] ) dc=state["search_results"] if getattr(response, "subtopics", None): subtopics=response.subtopics for topic in subtopics: print(f"[Searcher] querying Tavily for subtopic: {topic}") results = tavily_tool.invoke(topic) results_contents = [result['content'] for result in results.get('results', [])] print(f"[Searcher] got {len(results_contents)} web results for {topic}") dc[topic] = results_contents else: subtopics=[] print("[Searcher] WARNING: no subtopics were returned by the LLM") print(f"[Searcher] done. sub_topics = {list(response.subtopics) if getattr(response, 'subtopics', None) else []}") return { 'search_results' : dc, 'sub_topics': subtopics, 'summaries_approval' : {s :False for s in subtopics}, 'first_critic_opinions' : {s :'None' for s in subtopics} }
as we can see, the agent takes the wanted variables from the current state, does its job from calling the LLM and processing the results, then updates the state with the new results. That's the general method of most of the agents.
But we have to take a special look at Parallel_Analyzer:
async def Parallel_Analyzer(state): print("Starting parallel analyzer") if state['num_external_resources'] > 0: sr = add_rag_to_tavily_results(state) else: sr = state['search_results'] ts = state["topics_summaries"] tkf= state["topics_kfacts"] tasks_data = [] for topic,results in sr.items(): skip = state["summaries_approval"][topic] if skip: continue opinion = state["first_critic_opinions"][topic] results_string = "\n\n\n\n\n".join(results) single_args = {'topic': topic, 'paragraphs_list': results_string, 'opinion': opinion} tasks_data.append((topic, single_args)) coroutines = [first_summarizer_chain.ainvoke(args) for _, args in tasks_data] responses = await asyncio.gather(*coroutines, return_exceptions=True) for (topic, _), response in zip(tasks_data, responses): if isinstance(response, Exception): raise response ts[topic] = getattr(response, "summary", 'None') tkf[topic] = getattr(response, "KeyFacts", []) return {'topics_summaries' : ts , 'topics_kfacts' : tkf}
from the beginning we see thee "async", that's because we are using async to parallelize the summarization process of each subtopic independently. we define a list of tasks which is tasks_data and use ainvoke so that we can use await asyncio.gather to initiate all the summarizations at once.
we don't use async.run here since we used it in the main.py fileto make the temporal loop created by the async.run universal and so it lasts until the agent finishes all its work.
we can see the definition of both a summarizer and a critic for each summarizer to implement the summarizer-critic loop.
in the state we define variables for the both the critics' approval and opinion.
after the critic reviews the summarizations, it returns an approval Boolean and an opinion to the summarizer, if the approval is true, then we move forward. If not, then we retry the summarization process with passing the critic's opinion to the LLM this time.
This simply defines the system's graph, adding the nodes mentioned earlier and connecting them according to the architecture we discussed above.
paying attention when to return the summary to the critic and when to move forward.
This file contains the tools that'll be used by the system, like Parsing pdf and txt files , and searching the vector database for relevant chunks of text. without forgetting to define the Tavily web search tool.
This one contains the prompt templates for the different LLMs used. the prompts were chosen to explicitly tell the LLM what to do, defining the rules it must follow, the outputs it must generate, and the allowed responses.
Here is an example of a prompt in the file:
Simplifier_Prompt_Template = """ You are an LLM which is provided a web searching tool , You take a topic from the user to make a research about it, your job is to break that input into smaller subtasks to search for each subtask alone. Ensure you follow these rules when finding your response: -You shouldn't break the topic onto many tiny tasks that can be done together, because that will cost a lot. -You also shouldn't combine two different tasks into one. -Your output must be in the structured format you are given -Your list of subtasks will be given to web searchers to get information, so keep its words as simple as possible. -Make sure that the subtopics are formulated nicely for web search, just like a human would search on the web about that topic . -Make sure that your to-search subtopic is clear and that it can't have two different meanings, if it has, then include an explanation for it or a hint of which meaning is the desired one . Make sure to follow these tips: -When generating the sub-questions, make sure to ask about things that enrich the meaning and make the reader understand more. For example, if the topic is scientificial like calculus, you'd want to search for the original rule that calculus is based on (which is the limits, why do we we need them, ...) make sure to search for definition, base rule or material that the topic is based on, some theory, examples, use cases, pros and cons about the topic and things like that... Also, calculus can have different unrelated meanings, so as you are instructed above, include that we mean the mathematical concept for example : "phases of calculus in math" or something like that. Given Topic : {topic} Task: Divide and simplify the given topic of the research into smaller subtasks to search for each subtask independently on the web. """
This is the prompt for the LLM used by the Searcher agent, which divides the main topic into sub topics.
This file contains some Pydantic structures that serve as a blueprint for the LLM output.
This one contains the definition of the vectordb class, which is the vector database for the RAG retrieval tool.
for more information, see the publication : https://app.readytensor.ai/publications/simple-rag-assistant-project-X4AhWzVWUPnu
We can ask the system to generate some researches about some topics and see how well it performs.
For example, if we ask the system to give us a research about linear algebra ( see this experiment's final research at the end of the publication ), the system divided the topic into those sub-topics: ['What is linear algebra definition', 'Fundamental concepts of linear algebra', 'Applications of linear algebra in real world', 'Why is linear algebra important', 'Basic examples of linear algebra problems'], as instructed the subtopics cover different scientific aspects of the main topic, starting from the basic definition to the fundamentals to applications and so on...
So the topic was broken successfully.
-The first limitation to notice is the cost of the system most free APIs reach the limit after only two usages of the system.
-The system doesn't store previous messages, we can't tell the system to edit anything in the output, and we have to construct all over again, and even if we could, the cost is very high
-Using the systems for a few times, we can found that almost always, the final research is from 12K to 13K characters.
-The final research is only consists of text.
-We need to work on finding away to massively reduce the high cost of the system.
-We can add memory to store previous messages, and adding a shortcut to edit the system without beginning all over again and with much lower cost.
-We should find a way to make the final output longer (or even shorter if the user wants to).
-We might want to add the ability to add external photos, search for them, or let an AI model generate them
Now to see the final result:
Linear algebra stands as a fundamental branch of mathematics, dedicated to the study of vectors, vector spaces, linear transformations, and systems of linear equations. At its core, it explores "line-like relationships," which are inherently predictable, distinguishing them from more complex non-linear interactions. This field is indispensable across nearly all areas of mathematics, including modern geometry and functional analysis, as well as in physics, engineering, and computer science, where it is employed to define basic objects like lines, planes, and rotations, model natural phenomena, and significantly enhance computational efficiency.
The bedrock of linear algebra is built upon the concepts of vectors and vector spaces. A vector space comprises a set of vectors along with all possible linear combinations of these vectors. The operations within a vector space, such as vector addition and scalar multiplication, must adhere to specific requirements known as vector axioms, ensuring the space forms an abelian group under addition. Subsets of vector spaces that maintain these properties under the induced operations are termed linear subspaces. The span of a set of vectors refers to the complete collection of all possible linear combinations that can be formed from those vectors.
A crucial concept is linear independence, which defines a set of vectors where no vector can be expressed as a linear combination of the others. Conversely, a set is linearly dependent if one vector can be written as a combination of the others, or if the set contains the zero vector, or if the number of vectors p exceeds the dimension n of the space Rn. Linear independence is vital for establishing a basis, which is any set of linearly independent vectors that can serve as a coordinate system for a vector space. For an n-dimensional vector space, a basis is composed of exactly n linearly independent vectors from that space. The Dimension Theorem formalizes this, stating that if a vector space V has a basis of n vectors, then any set in V containing more than n vectors must be linearly dependent, and every basis of V must consist of exactly n vectors. Furthermore, for a subspace H of a finite-dimensional vector space V, any linearly independent set in H can be expanded to form a basis for H, implying that H is also finite-dimensional and its dimension is less than or equal to the dimension of V (dim H ≤ dim V). The Basis Theorem adds that for a p-dimensional vector space (p ≥ 1), any linearly independent set of p vectors in V is a basis for V.
Linear equations, typically represented as a1x1 + a2x2 + ... + anxn = b, where a's are coefficients, x's are unknowns, and b is a constant, form a cornerstone of the subject. Systems of such equations are efficiently solved using matrices, which are rectangular arrays of numbers. In a linear system Ax = b, A is the coefficient matrix, and (A|b) is the augmented coefficient matrix. While matrix theory over a ring shares similarities with that over a field, determinants exist only for commutative rings, and a square matrix is invertible only if its determinant possesses a multiplicative inverse within that ring.
Linear transformations are mappings that preserve the fundamental operations of vector addition and scalar multiplication. If T is a linear transformation, it satisfies T(0) = 0 and T(cu + dv) = cT(u) + dT(v) for all vectors u, v and scalars c, d, thereby preserving linear combinations. For any linear transformation T: Rn -> Rm, there exists a unique m x n matrix A such that T(x) = Ax, where the jth column of A is the transformation of the jth column of the identity matrix in Rn, T(ej). The coordinate mapping, which transforms a vector x into its coordinate vector [x]B with respect to a basis B, is a one-to-one linear transformation from V onto Rn. The First Isomorphism Theorem further clarifies linear maps, stating that for a linear map α: U -> V, its kernel (ker α) and image (im α) are subspaces, and α induces an isomorphism ᾱ: U/ker α -> im α. A direct consequence is that if U and V are finite-dimensional vector spaces and α: U -> V iis an isomorphism, then dim U = dim V.
A deep understanding of linear transformations is provided by eigenvalues and eigenvectors. An eigenvector of a square matrix is a non-zero vector that, when multiplied by the matrix, results in a scalar multiple of itself. This scalar is the associated eigenvalue. For a triangular matrix, its eigenvalues are simply the entries on its main diagonal. A significant theorem states that if v1, ..., vr are eigenvectors corresponding to distinct eigenvalues λ1, ..., λr of an n x n matrix A, then the set {v1, ..., vr} is linearly independent. Eigenvalues are determined by solving the characteristic equation, det(A - λI) = 0. Similar n x n matrices A and B share the same characteristic polynomial and, consequently, the same eigenvalues with the same multiplicities.
The Diagonalization Theorem provides a condition for diagonalizability: an n x n matrix A is diagonalizable if and only if it possesses n linearly independent eigenvectors. Alternatively, an endomorphism α ∈ End(V) is diagonalizable if and only if there exists a non-zero polynomial p(t) ∈ F[t] such that p(α) = 0, and p(t) can be factored as a product of distinct linear factors. The Spectral Theorem specifies that if a matrix A is symmetric (AT = A), then there exist orthonormal eigenvectors q such that Aqi = λiqi, and A can be decomposed as A = QΛQT. Eigenvalues and eigenvectors are essential for applications such as stability analysis, quantum mechanics, and the study of dynamical systems.
Several theorems form the bedrock of linear algebra, unifying various concepts:
The Invertible Matrix Theorem: This theorem is a cornerstone, unifying numerous concepts related to square matrices. For an n x n matrix A, the following statements are equivalent: A is invertible; the system of equations Ax=b has a unique solution x for every vector b; the columns of A are linearly independent; the rows of A are linearly independent; the columns of A form a basis for Rn; the rows of A form a basis for Rn; the determinant of A is non-zero; the image of A is Rn; the kernel of A is 0; and all eigenvalues of A are non-zero. This theorem highlights the deep interconnectedness of matrix properties, linear systems, bases, and eigenvalues.
Gilbert Strang's Fundamental Theorem of Linear Algebra: This theorem describes the action of an m x n matrix A in terms of four fundamental subspaces: the row space, column space, null space, and left null space.
n (the Rank-Nullity Theorem), where the rank of A is the dimension of the column space and also equals the number of pivot positions in A.Beyond these central ideas, other significant theorems include the Fundamental Theorem of Algebra, which asserts that every non-constant polynomial over the complex numbers C has at least one root in C. The Normal Matrix Theorem and the Principal Axis Theorem deal with specific types of matrices and their diagonalization properties, often related to self-adjoint operators. Concepts like direct sums and quotients of vector spaces also provide integral tools for constructing and analyzing vector spaces.
Linear computations involve numerical methods for solving linear algebra problems, including systems of linear equations and the calculation of eigenvalues and eigenvectors. These computational techniques are indispensable in computer simulations, optimizations, and various modeling tasks. Key methods for solving linear systems include Gaussian Elimination, which transforms a matrix into row-echelon form; LU Decomposition, which efficiently solves systems by splitting a matrix into lower and upper triangular components; and QR Decomposition, particularly useful for least squares problems and eigenvalue computations. Furthermore, Eigen Decomposition, where a matrix is broken down into eigenvectors and eigenvalues, is crucial for applications like dimensionality reduction (e.g., Principal Component Analysis, PCA) and matrix factorization (e.g., Singular Value Decomposition, SVD, and Non-negative Matrix Factorization, NMF) for feature extraction.
Linear algebra is an indispensable mathematical discipline with pervasive applications across diverse scientific and technological fields, serving as a cornerstone for modern advancements.
Data Science and Machine Learning: Linear algebra is foundational, enabling the representation of datasets as matrices and vectors for analysis and manipulation. Optimization algorithms, such as gradient descent, extensively rely on linear algebraic operations to adjust model parameters and minimize cost functions; convex optimization problems are also solved using these techniques. Neural networks and deep learning models utilize linear algebra for fundamental processes like forward and backward propagation, where input features, weights, and activations are manipulated through matrix multiplications, and for convolutional operations in Convolutional Neural Networks (CNNs). Specific applications include the formulation of loss functions, regularization techniques, the computation of covariance matrices, and the operation of Support Vector Machine (SVM) classification. Overall, linear algebra enhances algorithm efficiency, aids in understanding data structures, optimizes algorithms, processes high-dimensional data, and powers critical fields such as Natural Language Processing (NLP) and Computer Vision.
Computer Science: Its principles are embedded in graphics rendering, signal processing, network analysis, the Google PageRank algorithm, and error correcting codes.
Engineering: Disciplines leverage linear algebra for modeling systems, solving differential equations, and in computational fluid dynamics (CFD) for solving equations like the Navier-Stokes equations.
Natural Sciences: It benefits from its application in modeling chemical reactions and population growth, and it is fundamental to quantum mechanics through functional analysis.
Mathematics: Within mathematics itself, linear algebra is central to modern geometry, defining basic objects such as lines, planes, and rotations, and forms the basis of functional analysis.
Economic and Social Sciences: It is applied in input-output economic models, Markov chains, and linear optimization for resource allocation and scheduling, saving significant resources annually.
Physics: Utilizes linear algebra for tasks such as finding the principal axes of inertia of solid objects and in the optimization of particle accelerators by correcting beam trajectories.
Other diverse applications include network flow analysis, electrical networks, directed graphs, and constrained optimization.
In conclusion, linear algebra provides a comprehensive framework and powerful tools for efficiently handling large datasets, performing complex computations, deriving insights from data, designing algorithms, and solving a vast array of real-world problems. Its pervasive integration across scientific and technological advancements underscores its critical role as a cornerstone of modern innovation, making it an indispensable tool for understanding and shaping the contemporary world.
The final research is coherent, and structured correctly without errors. That was a 12,349 characters, 1,843 words research.
But we may encounter cases where the searcher would miss important aspects of the topic, like the intuition behind the formal definitions and some examples in our topic, and I believe that the very next step should be making sure that this problem doesn't happen.
We could also connect the agent to a scientific articles and papers website in the future.
But for now, it does its simple purpose
