
This project is the Module 3 Capstone, designed to transform the functional prototype into a robust, production-grade application. The system solves the critical problem of unstable and poorly documented technical assets.
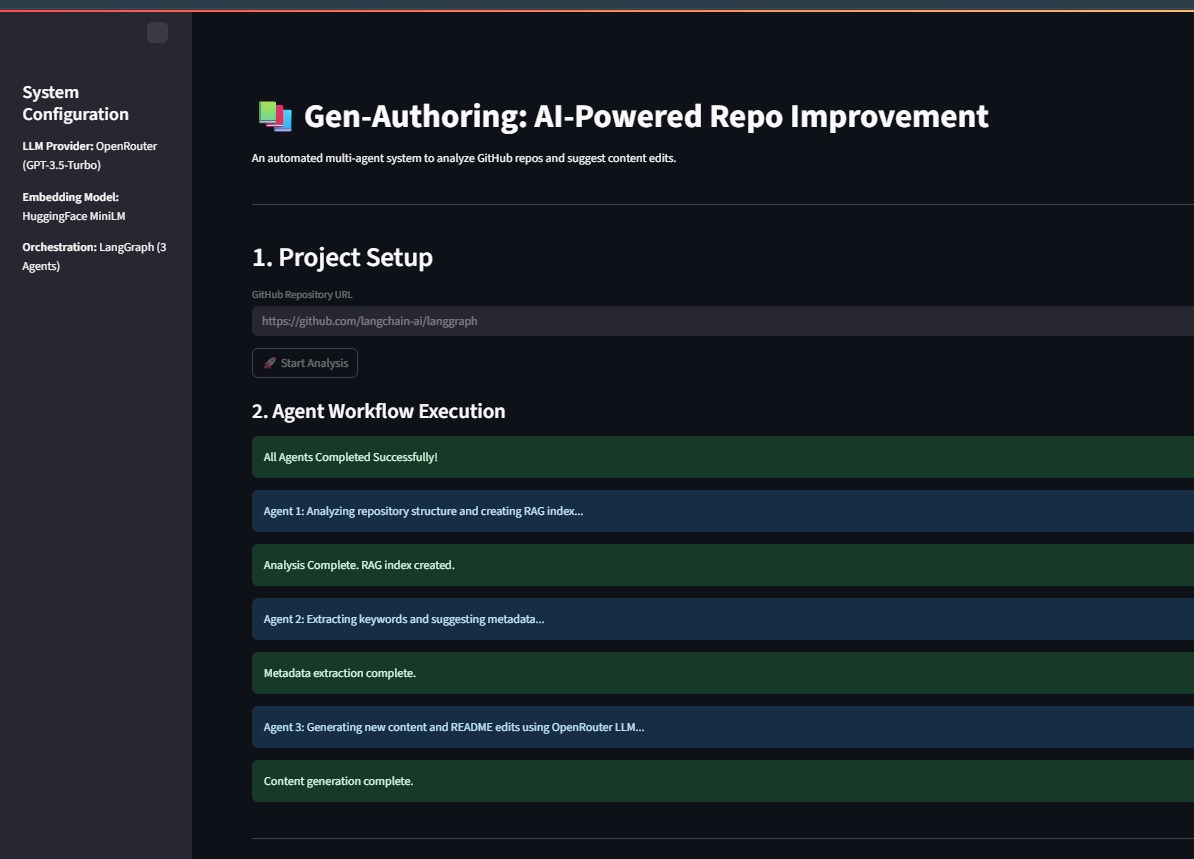
The GitHub Production Agent is a multi-agent system designed to automatically analyze any public GitHub repository, generating grounded, actionable recommendations for improving its documentation.
This final deliverable demonstrates mastery over: Production Readiness, Agent Orchestration (LangGraph), Security Guardrails, and Comprehensive Testing.
The architecture is a controlled, sequential LangGraph pipeline ensuring predictable execution and stability.
| Agent | Core Responsibility | Key Tool Integration |
|---|---|---|
| RepoAnalyzerAgent | Repository Preparation & RAG Indexing. Clones the target URL and prepares content for analysis. | Repo Reader Tool (gitpython, TextLoader) & RAG Retriever Tool (FAISS). |
| MetadataRecommenderAgent | Keyword & Tag Extraction. Identifies key project terminology. | Keyword Extractor Tool (nltk). |
| ContentImproverAgent | Structured Generation. Synthesizes suggestions based on RAG context. | LLM Generation API (OpenRouter/GPT-4o Mini) and Retriever Object. |
The system implements robust measures for technical credibility and reliability:
tests/ directory contains Unit and Integration Tests for critical components (e.g., keyword extraction, data handoff), providing verifiable evidence of the testing methodology requested by reviewers.ContentImproverAgent utilizes Retry Logic with Exponential Backoff (a core operational feature) to ensure stability against transient API failures. This is our specific metric for system stability..env file) are fully detailed in the GitHub repository README.md.app.py) serves as the user-friendly interface. The user provides the URL and initiates the agent flow, effectively integrating human oversight for final validation of the generated edits.| Setting | Value | Rationale for Technical Rigor |
|---|---|---|
| Text Chunk Size | 1000 tokens | Optimal size for maintaining complete code blocks and full documentation context. |
| Text Chunk Overlap | 200 tokens | Ensures semantic continuity for high-quality RAG retrieval. |
| Embedding Model | HuggingFaceEmbeddings(all-MiniLM-L6-v2) | Chosen for efficiency and strong semantic performance. |
By: Sudarshan Maddi