This project presents a Retrieval-Augmented Generation (RAG)–based Healthcare AI Assistant designed to provide accurate, reliable, and document-grounded answers to healthcare-related queries. Unlike traditional conversational AI systems that rely heavily on the internal knowledge of large language models (LLMs), this assistant retrieves information from a custom-curated healthcare knowledge base and generates responses strictly based on the retrieved content.
Conventional LLM-based systems, while powerful, are prone to hallucinations—the generation of plausible-sounding but incorrect information. In healthcare, such errors can be harmful and ethically unacceptable. This project addresses that challenge by tightly integrating information retrieval with controlled language generation, ensuring that every response is fact-based, explainable, and traceable to source documents.
By combining vector databases, semantic search, prompt engineering, and LLMs, this system demonstrates a responsible AI architecture that prioritizes safety, transparency, and reliability, making it suitable for sensitive domains such as healthcare education.

What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a hybrid artificial intelligence architecture that enhances the capabilities of large language models (LLMs) by integrating external, domain-specific knowledge sources into the response generation process. Rather than treating the language model as a closed system that relies only on pre-trained parameters, RAG explicitly separates knowledge retrieval from language generation.
In a RAG system, the language model does not act as the primary source of truth. Instead, factual knowledge is retrieved from a trusted and curated document repository at the time of the user query. This retrieved information is then provided to the model as contextual grounding, ensuring that generated responses are aligned with verified source material.
Instead of relying solely on pre-trained knowledge, a RAG system:
Dynamically retrieves the most relevant information at query time using semantic similarity search
Injects the retrieved document context directly into the prompt provided to the language model
Generates responses that are explicitly constrained to the retrieved content, rather than model assumptions
By grounding generation in retrieved documents, RAG significantly improves factual accuracy, transparency, and explainability. This architecture greatly reduces hallucinations, as the model is instructed to respond only using the supplied context and to avoid speculation when relevant information is unavailable.
From a system design perspective, RAG provides several important advantages:
It enables continuous knowledge updates without retraining the language model
It improves domain adaptability, making it suitable for specialized fields such as healthcare
It allows responses to be audited and traced back to source documents
Overall, Retrieval-Augmented Generation represents a practical and responsible approach to deploying language models in high-risk domains, where accuracy, safety, and trustworthiness are essential.
How RAG Works
A RAG system operates in two fundamental stages:
1️⃣ Retrieval Stage
When a user submits a question, the system:
Converts the query into a vector embedding
Searches a vector database using semantic similarity
Retrieves the most relevant document chunks based on meaning rather than keywords
2️⃣ Generation Stage
The retrieved document chunks are then:
Combined with the user’s question
Injected into a carefully designed prompt
Passed to a large language model (LLM), which generates a response strictly based on the provided context
This separation of retrieval and generation:
Minimizes hallucinations
Improves factual accuracy
Makes the system explainable and auditable
Why RAG is Important in Healthcare
Healthcare is a high-stakes domain where incorrect or fabricated information can lead to serious consequences. Any AI system operating in this space must meet strict requirements.
Healthcare information must be:
RAG is particularly well-suited for healthcare because:
Scope of This Project
This project focuses on educational and informational healthcare content, such as:
The system does not:
The assistant is intentionally designed not to replace medical professionals and does not provide clinical advice.
The Healthcare RAG Assistant is composed of multiple interconnected components, each playing a critical role in ensuring accuracy and reliability.
.png?Expires=1782553780&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=j~lY3D7WezH4AfJzY~9u~QCeQSO1qGfj7SMu8lex62t6~xFCleSOOv9WynLLABN~Dvnd93mfCZDVn8vJUqTmD37SPagSfFkisJB5ZUwUKdbc3-yp7EMqR3-jWgJpXfNgqw2pebMNMom6EeLPDF-ka2na0-hNQJP2LY3~tquq3NjNSERaEEIdxQdt7y11WocjRQivT3oDqD-p6cBClyJ~HrnQ7wuUvWJj6lAp7hmr0dW10gRNUhi73bd2kbqmkRDq~aPzgZwveztGjJFUVgj1Z~KBR~cKLWIWFX232yO5kv-an1hRiJmqJtNxi8JLHYXcldgMg9eSyTMqALRFzmOw2A__)
1️⃣ Document Loader
The document loader:
This modular design allows the knowledge base to be easily expanded by simply adding new documents.
2️⃣ Text Chunking Module
Large healthcare documents are often too long to be processed efficiently as a single unit. To address this, the system applies text chunking.
Chunking:
Proper chunking ensures that:
Overlapping chunks are optionally used to prevent context loss at chunk boundaries.
3️⃣ Embedding Model
The system uses Sentence Transformer models to convert text into numerical vector representations.
These embeddings:
4️⃣ Vector Database (ChromaDB)
ChromaDB serves as the vector storage and retrieval engine.
Its responsibilities include:
Using a vector database allows the system to scale efficiently while maintaining high retrieval accuracy.
5️⃣ Prompt Engineering Layer
Prompt engineering is a crucial safety mechanism in this project.
The prompt:
Combines retrieved document context with the user query
Instructs the LLM to use only the provided information
Explicitly forbids external knowledge or assumptions
This layer plays a key role in hallucination prevention and responsible AI behavior.
6️⃣ Large Language Model (LLM) Selection
The system supports LLMs such as OpenAI models, Groq-hosted models, and Google Gemini.
Rationale for LLM choice:
Why these LLMs are suitable for healthcare RAG:
This design ensures that the knowledge authority remains the documents, not the model.
🔄 End-to-End Workflow :
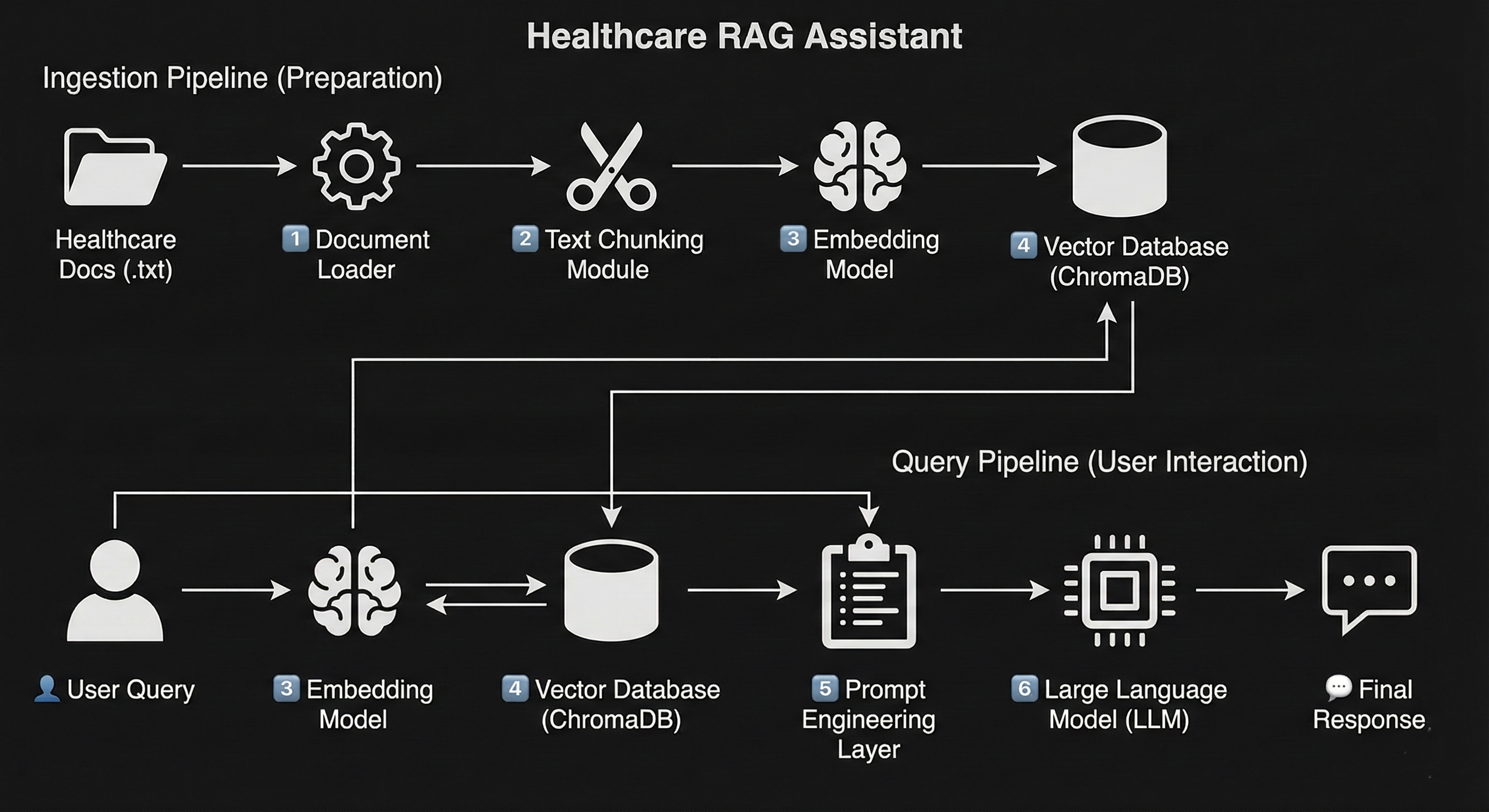
The complete system workflow proceeds as follows:
This pipeline ensures accuracy, traceability, and safety at every step.
Text Chunking Strategy
Text chunking plays an important role in improving the quality of information retrieval. In this project, the text is divided into smaller chunks in a way that balances enough context with better precision. This helps the system understand the content properly without making the chunks too large or too small.
Overlapping chunks are used when needed to prevent loss of important context between sections. Each chunk is carefully created to make sure it still contains meaningful healthcare-related information. This approach results in higher retrieval precision, more relevant and accurate answers, and reduced noise in the system’s responses, leading to an overall better user experience.
Benefits include:
Semantic Search Using Vector Embeddings
Unlike keyword-based search, semantic search focuses on meaning rather than exact terms.
Advantages include:
This enables the assistant to respond accurately even when users phrase questions differently.
Prompt Design and Hallucination Control
The system prompt enforces strict rules:
Fallback Handling
When the system is unable to find any relevant data, the assistant responds with a polite and clear message such as,
“I’m sorry, I couldn’t find relevant information about this in the provided documents.”
This helps users understand that the information is not available rather than receiving an incorrect or confusing answer.
This type of fallback behavior is important for building trustworthy AI systems, as it ensures transparency and prevents the system from generating misleading responses when sufficient data is not present.
Healthcare Ethics and Safety Considerations
This assistant:
Testing and Validation
The system was tested with different types of questions to check how well it performs in real situations. These included valid healthcare-related queries, questions about preventive care, and general public health topics. The system was also tested using out-of-scope questions to see how it behaves when the requested information is not available.
The results showed that the system provides accurate and reliable answers when relevant data exists. In cases where information is not available, it responds safely by giving a fallback message instead of incorrect or misleading information. Overall, the system behaved in a stable and predictable manner during testing, which shows that it can be trusted for consistent performance.
Learning Outcomes
This project provided practical, hands-on experience with several important concepts related to modern AI systems. It helped in understanding how RAG (Retrieval-Augmented Generation) architecture is designed and implemented in real applications. The project also gave experience in using different text chunking strategies to break large documents into smaller parts for better processing and retrieval.
In addition, the project involved working with vector embeddings and semantic retrieval, which made it possible to search and match information based on meaning rather than just keywords. ChromaDB was used for vector storage, allowing efficient management and retrieval of embedded data. The project also improved skills in prompt engineering to make sure the system behaves safely and gives appropriate responses. Overall, the work helped build awareness of responsible AI development practices and the importance of creating AI systems that are safe, reliable, and ethical.
This project is released under the MIT License, allowing free use, modification, and distribution with proper attribution.
This Healthcare RAG-Based AI Assistant demonstrates how responsible AI systems can be built by grounding language models in trusted data sources. By combining retrieval mechanisms with LLMs, the system delivers accurate, explainable, and safe healthcare information.
The project forms a strong foundation for future enhancements such as:
Omkar Patil
B.Tech CSE
Dr. D. Y. Patil Agricultural & Technical University, Talsande