This project presents a business-focused portal for exploring Ghana's investment landscape using official Bank of Ghana reports. Users can upload the latest PDF report and ask questions about sector trends, macroeconomic indicators, and regulatory changes. The system uses a Retrieval-Augmented Generation (RAG) pipeline with ChromaDB, HuggingFace embeddings, Groq LLM, and a custom Streamlit interface for a seamless, data-driven experience.
Introduction
Investors and policymakers need timely, reliable insights to make informed decisions. This portal bridges the gap between raw financial data and actionable intelligence by allowing users to interact with official Bank of Ghana reports through natural language queries. The solution is designed for clarity, transparency, and business usability.
Methodology
Tools, Frameworks, and Libraries
Python 3.10+: The primary programming language for the project.
Streamlit: Used to build a clean, interactive, and business-focused web interface for user interaction.
PyPDF2: For extracting text from PDF reports.
LangChain: Provides the pipeline for text chunking, embedding, and retrieval.
ChromaDB: A persistent vector database for storing and searching document embeddings efficiently.
HuggingFace Transformers & Sentence Transformers: Used for generating dense vector embeddings of text chunks. Specifically, the sentence-transformers/all-MiniLM-L6-v2 model was chosen for its balance of speed, accuracy, and resource efficiency in semantic search tasks.
Groq LLM (Llama 3.1-8b-instant): The large language model used for generating answers. Chosen for its strong performance, cost-effectiveness, and ability to follow custom system prompts.
python-dotenv: For secure management of API keys and environment variables.
Text Chunking: The extracted text is split into overlapping chunks using LangChain's RecursiveCharacterTextSplitter (chunk size: 1000, overlap: 200) to preserve context and improve retrieval accuracy.
Embedding & Vector Storage: Each chunk is embedded using HuggingFace's MiniLM model (all-MiniLM-L6-v2) and stored in ChromaDB. This enables fast, semantic similarity search for user queries.
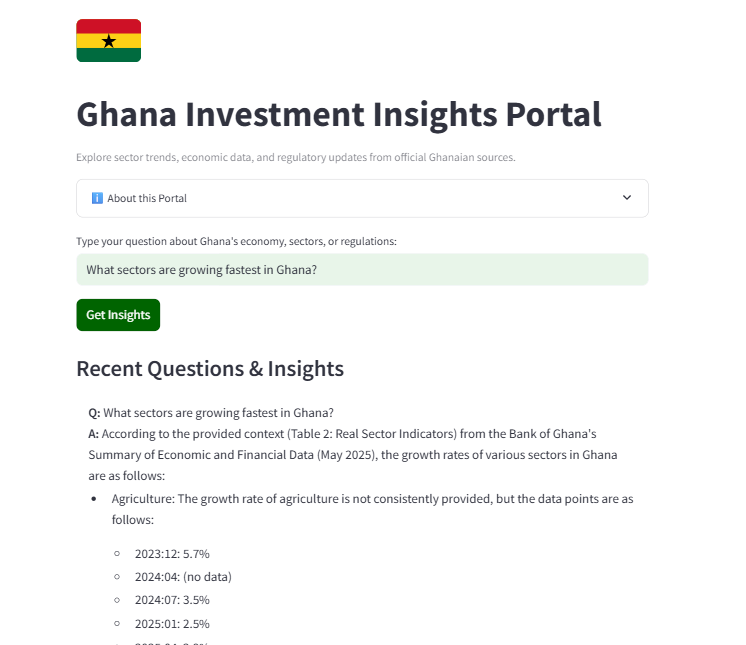
Retrieval & Prompting: When a user submits a question, it is embedded and compared to all stored chunks. The top-k most relevant chunks are retrieved. These are combined with a business-focused system prompt and sent to Groq LLM (Llama 3.1-8b-instant) for answer generation. The prompt ensures the LLM only uses information from the uploaded report and responds in a clear, professional style.
User Interface: The Streamlit UI is styled as a business portal, with branding, color, and layout tailored for professional users. Users can type questions, view answers, and see a history of their queries and responses.