Abstract
Retail businesses depend heavily on accurate demand forecasting to optimize inventory, pricing, and supply chain decisions. In this project, a machine learning solution was developed to predict Product_Store_Sales_Total for SuperKart retail outlets using historical product and store-level data.
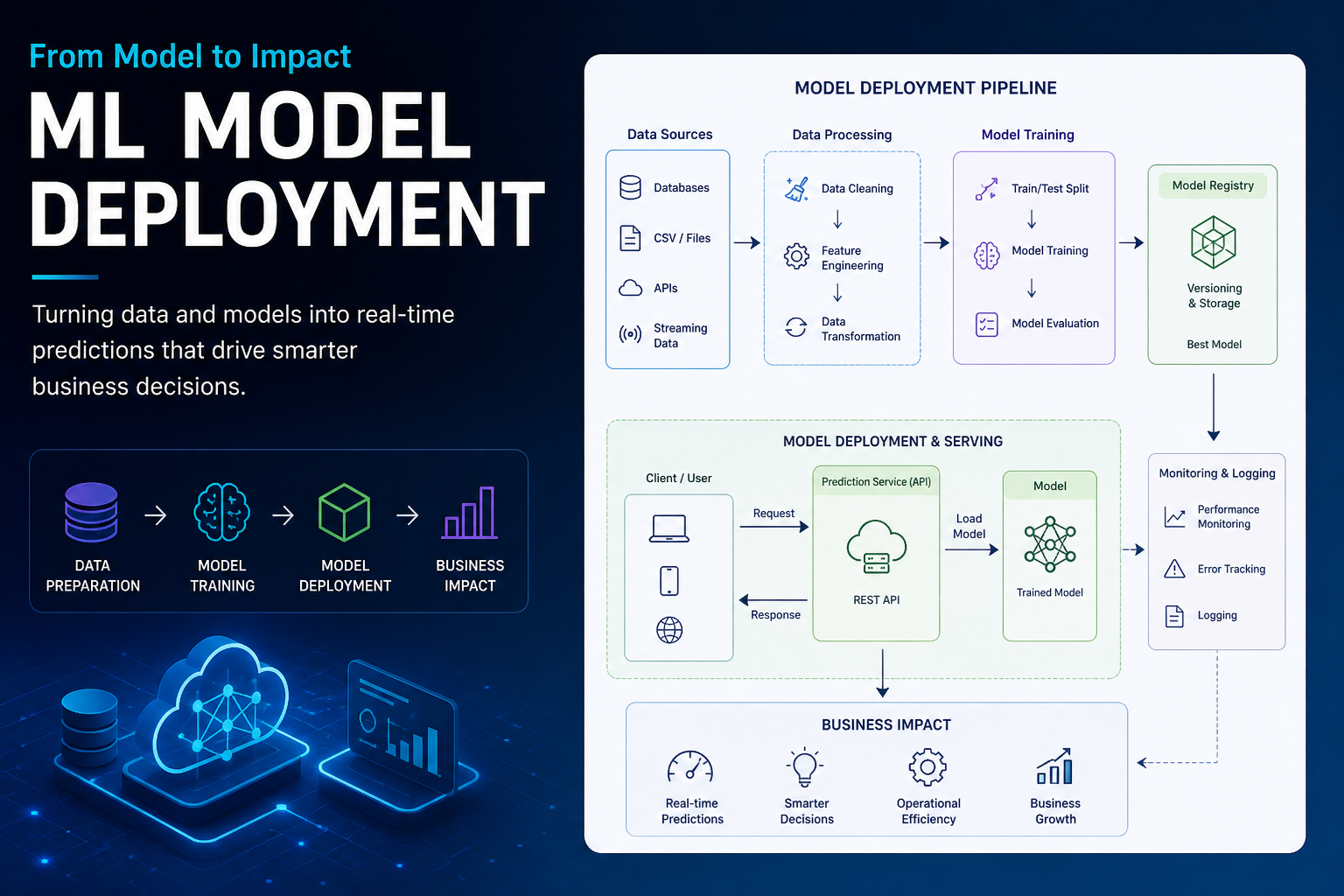
The workflow includes data preprocessing, exploratory data analysis, feature engineering, regression model benchmarking, hyperparameter tuning, model evaluation, and deployment artifact generation.
Multiple regression models were tested, including Random Forest, Decision Tree, and XGBoost. The final selected model achieved strong predictive performance with an R² Score of 0.9239, demonstrating high forecasting accuracy.
The project concludes with deployment-ready .pkl model files and API integration readiness.
GitHub Reference : https://github.com/RamyaNandhan/modelDeployment
Introduction
Sales forecasting is a critical challenge in retail operations. Incorrect forecasting leads to:
Overstocking
Understocking
Revenue leakage
Poor customer experience
Supply chain inefficiencies
Traditional spreadsheet-based forecasting methods often fail to capture nonlinear patterns in large datasets.
Machine learning provides a scalable solution by learning patterns from:
Product features
Store attributes
Historical sales trends
This project builds an intelligent forecasting engine for SuperKart stores.
This project builds a Machine Learning Regression Model to forecast sales revenue for SuperKart retail outlets using historical product and store data.
The solution helps business teams improve:
Inventory planning
Demand forecasting
Outlet performance strategy
Pricing decisions
Supply chain efficiency
✅ Data Cleaning
✅ Exploratory Data Analysis
✅ Feature Engineering
✅ Multiple Regression Models
✅ Hyperparameter Tuning
✅ Best Model Selection
✅ Deployment Artifacts (.pkl)
✅ API Ready Model Files
🏢 Business Problem
SuperKart operates multiple supermarkets and food marts across cities.
To optimize stock and improve sales planning, the company needs to accurately predict:
🎯 Target Variable
Product_Store_Sales_Total
This represents total product sales at a store.
⚙️ Project Workflow
Raw Dataset
↓
Data Cleaning
↓
EDA & Insights
↓
Feature Engineering
↓
Train/Test Split
↓
Model Training
↓
Hyperparameter Tuning
↓
Best Model Selection
↓
Model Deployment Files
🧠 Models Used
The notebook compares:
Regressor
Regressor
Regressor
🏆 Final Best Model
✅ Tuned Random Forest Regressor
Why it was selected:
Highest R² Score
Lowest RMSE
Lowest MAE
Strong generalization performance
Final Metrics
Metric Value
RMSE 0.101688
MAE 0.038903
R² Score 0.923969
Adjusted R² 0.922853
MAPE 0.005017
📂 Repository Structure
superkart-sales-forecasting
│
├── data
│ └── sales_data.csv
│
├── notebooks
│ └── FC_SuperKart_Model_Deployment_Notebook.ipynb
│
├── src
│ ├── preprocess.py
│ ├── train.py
│ ├── evaluate.py
│ └── predict.py
│
├── deployment_files
│ ├── best_random_forest_model.pkl
│ └── preprocessor.pkl
│
├── api
│ └── app.py
│
├── visuals
│ └── architecture.png
│
├── requirements.txt
└── README.md
📦 Deployment Files Generated
Notebook generates
deployment_files/
best_random_forest_model.pkl
preprocessor.pkl
Meaning:
best_random_forest_model.pkl → trained model
preprocessor.pkl → feature transformation pipeline
These are used directly in production APIs.
🌐 API Deployment Example
Using or
model = joblib.load("best_random_forest_model.pkl")
preprocessor = joblib.load("preprocessor.pkl")
Then predict from incoming JSON requests.
📈 Business Impact
This forecasting system can help:
✅ Reduce stock-outs
✅ Improve replenishment planning
✅ Predict high-performing stores
✅ Improve seasonal planning
✅ Reduce overstock losses
▶️ How to Run
pip install -r requirements.txt
jupyter notebook
Run all notebook cells.
🚀 Future Enhancements
Streamlit Dashboard
Real-time sales prediction API
Docker deployment
Cloud deployment on AWS
CI/CD pipeline
MLOps model monitoring
Experiments
| Experiment | Model | Outcome |
|---|---|---|
| Exp 1 | Decision Tree | Moderate accuracy |
| Exp 2 | Random Forest | Best performance |
| Exp 3 | XGBoost | Competitive but slower |
| Exp 4 | Tuned RF | Final winner |
Results
| Metric | Final Score |
|---|---|
| R² Score | 0.9239 |
| RMSE | 0.1016 |
| MAE | 0.0389 |
| MAPE | 0.0050 |
Interpretation
The model explains 92.39% of sales variance, indicating strong forecasting ability.
Conclusion
This project successfully developed a machine learning forecasting engine for retail sales prediction.
Key Outcomes:
Strong predictive accuracy
Deployment-ready model files
Real business use case
End-to-end ML pipeline
Real-World Impact:
SuperKart can use this system for:
Better stocking decisions
Lower inventory waste
Improved revenue planning
Smarter retail expansion