Mini-RAG Chat: Local Document Retrieval and Answering via LangChain, FAISS, and Ollama
Table of contents
Abstract
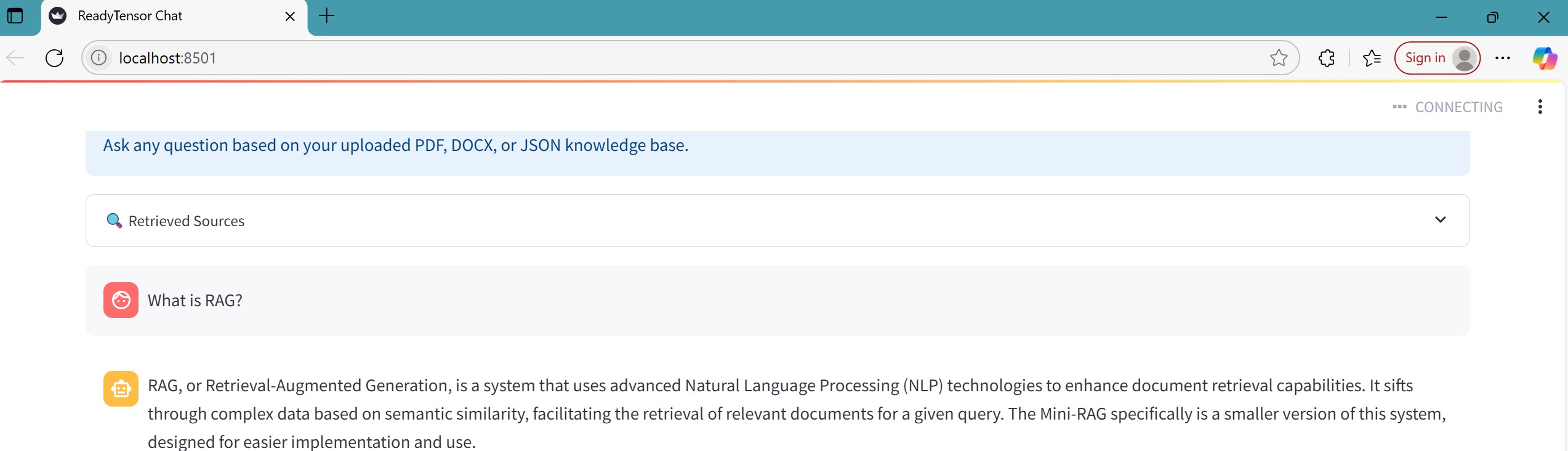
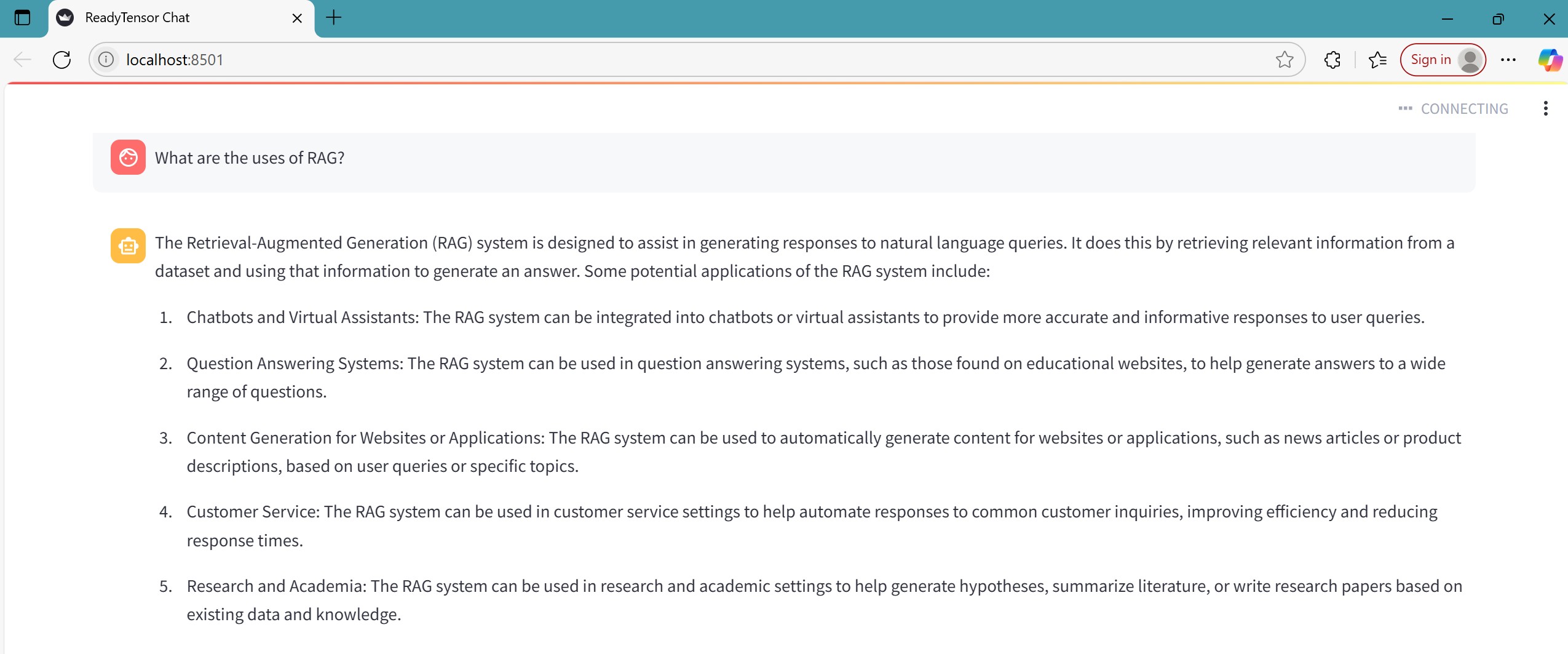
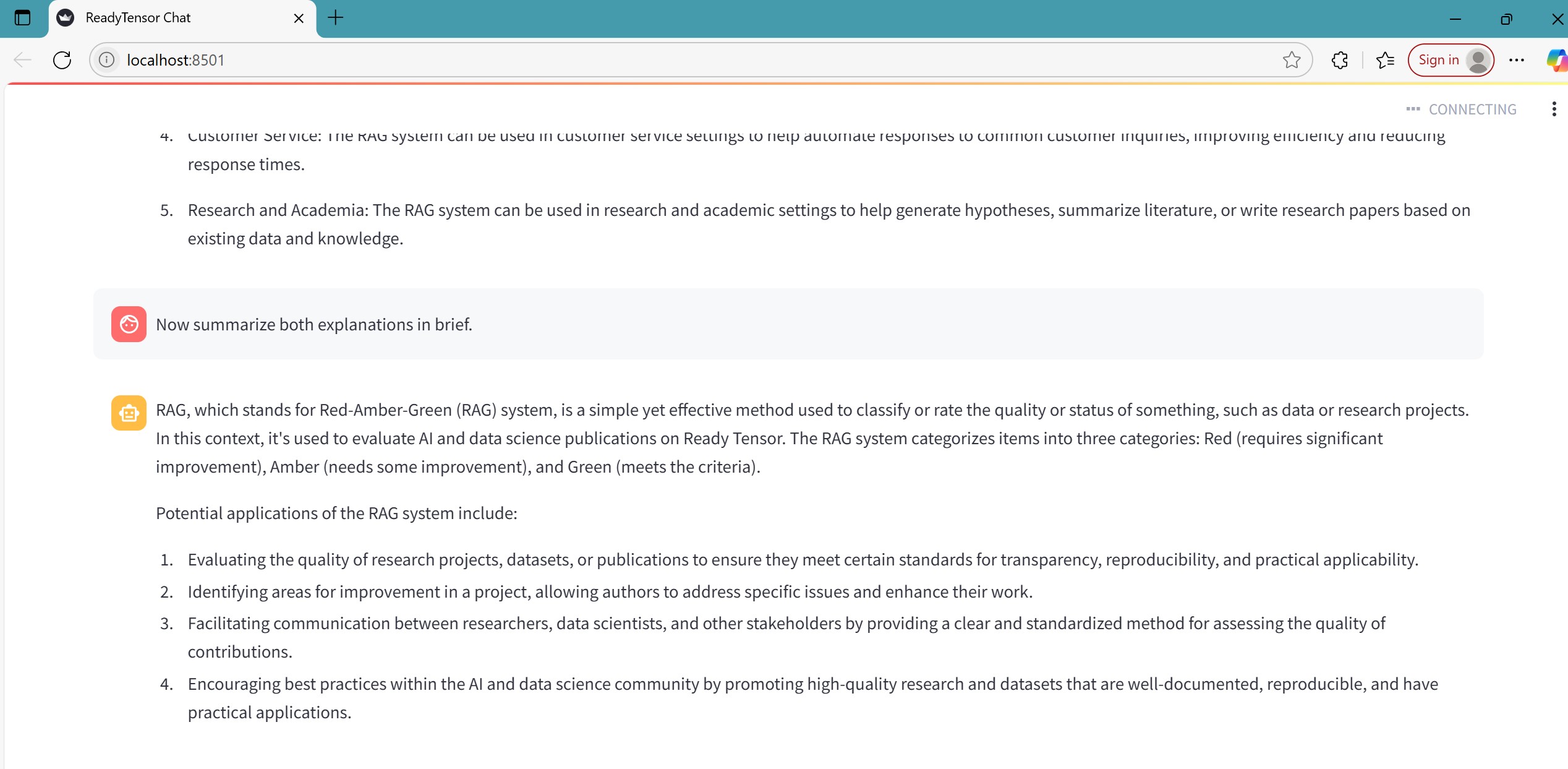
This publication introduces Mini-RAG Chat, a fully offline, lightweight document question-answering system using LangChain, FAISS for vector retrieval, and Ollama for local LLM inference. Users can upload PDFs, DOCX, or JSON files, which are chunked, embedded, and indexed locally. The system retrieves the most relevant context and formulates responses using a selected LLM (e.g., Mistral or LLaMA). Built with Streamlit, it features session memory, dynamic prompt templates, and real-time QA. It serves as a privacy-preserving assistant for enterprise, education, and research applications — with no internet or cloud dependencies. All processing is performed locally on the user’s machine.
Methodology
Methodology
The Mini-RAG Chat system is designed using a modular pipeline that integrates document processing, semantic search, and local LLM-based generation. It follows the core Retrieval-Augmented Generation (RAG) architecture with the following components:
-
Document Ingestion
Accepts user-uploaded .pdf, .docx, and .json files.
Files are parsed and converted into plain text using the Unstructured library.
Text is split into overlapping chunks using RecursiveCharacterTextSplitter to preserve semantic context. -
Embedding and Vector Store Construction
Each text chunk is embedded using HuggingFace Embeddings (all-MiniLM-L6-v2) or optionally via Ollama Embeddings if local-only setup is preferred.
Resulting dense vectors are stored in a local FAISS index.
Metadata such as source filename and position is attached to each vector for traceability. -
Semantic Retrieval and Prompt Formulation
On each user query, the system retrieves the top k semantically similar chunks using FAISS.
These retrieved chunks are formatted into a custom prompt template.
The prompt is passed to a local LLM (e.g., mistral or llama2 via Ollama) to generate a grounded response. -
Conversational Memory
A ConversationBufferMemory is attached to the chain to retain previous question-answer pairs.
This enables contextual follow-up questions and continuity across interactions.
The memory stores only the answer key to avoid ambiguity with source_documents. -
User Interface
A lightweight Streamlit frontend enables user interaction.
Features include a chat box, document upload area, and persistent session state.
Chat history is rendered using st.chat_message, and sources can optionally be displayed for transparency.
This architecture ensures data privacy, modularity, and local-first inference, suitable for secure enterprise use and academic research without dependency on cloud APIs.
Results