Machine Learning - Classical Pipeline
Table of contents
GitHUB :https://github.com/RamyaNandhan/machineLearning/tree/main/decision-tree-ml-project
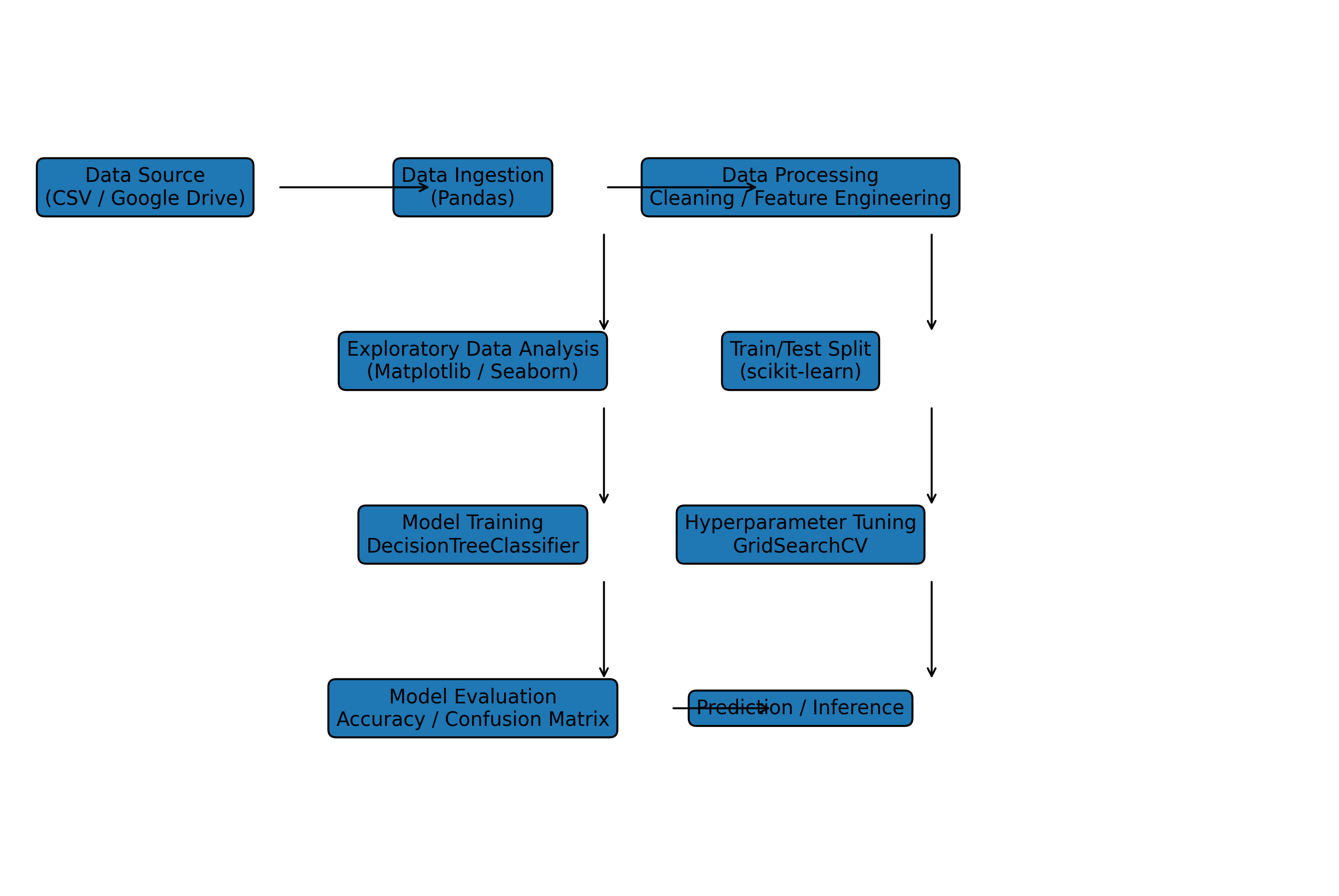
This is an example of classical Machine Learning pipeline built with:
Visualization / EDA: seaborn, matplotlib,
Modeling: scikit-learn,
Model: DecisionTreeClassifier,
Tuning: GridSearchCV,
Evaluation: sklearn.metrics,
Data split: train_test_split,
Storage source: Google Drive (Colab)
Machine Learning_Architecture :
Microservice level Machine Learning Architecture
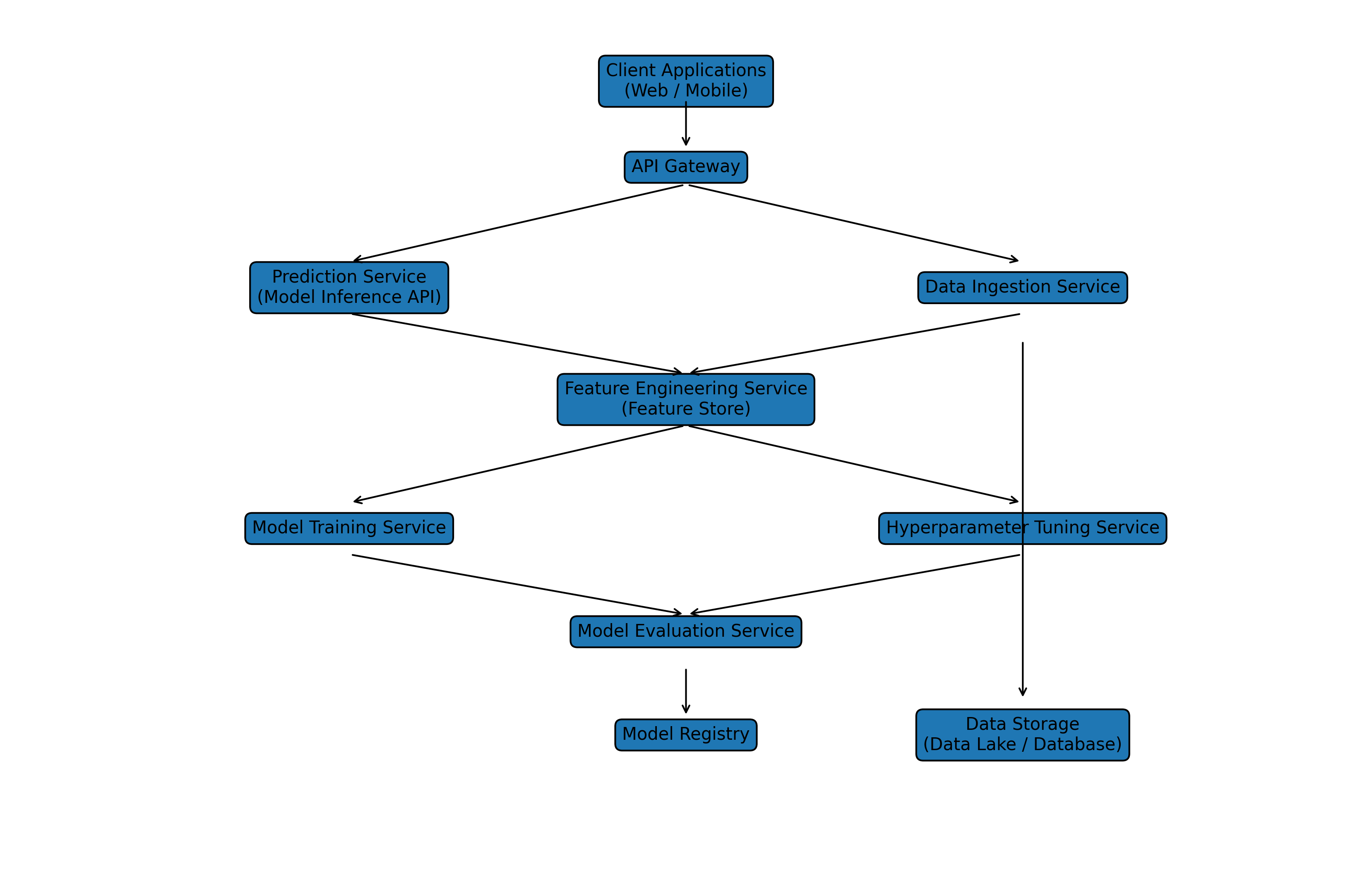
The microservice_ml_architecture diagram includes these services:
Client Applications
API Gateway
Prediction (Inference) Service
Data Ingestion Service
Feature Engineering Service / Feature Store
Model Training Service
Hyperparameter Tuning Service
Model Evaluation Service
Model Registry
Data Storage
Why Microservice ML Architecture?
Advantages
Independent scaling of services
Easier model updates
Fault isolation
Continuous deployment of models
Works well with MLOps pipelines
Data Flow
User sends request to API Gateway
Request routed to Prediction Service
Prediction service retrieves features
Latest model fetched from Model Registry
Prediction returned to client
Data logged for future training pipeline
The Problem on this notebook, is basically a comparison of three Decision Tree models:
Default Decision Tree
Pre-Pruned Decision Tree
Post-Pruned Decision Tree
we get to evaluate them using Accuracy, Recall, Precision, and F1 score.
This article explains a classification model using a Decision Tree to predict a target category based on input features.
Typical real-world problems that use this exact approach include:
Customer churn prediction
Loan approval / credit risk
Fraud detection
Medical diagnosis classification
Customer purchase prediction
demonstrates the complete ML lifecycle:
Data loading, Data exploration,Model training,Hyperparameter tuning,Model evaluation,Selecting the best model
Overall, this article shows steps to build a machine learning classification pipeline using a Decision Tree model. The workflow included data preprocessing, exploratory analysis, model training, hyperparameter tuning using GridSearchCV, and evaluation using accuracy, precision, recall, and F1 metrics.
compared default, pre-pruned, and post-pruned trees and selected the post-pruned model because it achieved the best balance between accuracy and generalization.