
Modern software ecosystems generate millions of repositories, yet repository intelligence remains shallow. Search engines rely on surface-level metadata, documentation is inconsistent, and automated evaluation tools lack semantic depth.
RepoMetaAgent is a deterministic, assembly-line multi-agent system designed to deeply analyze any public GitHub repository from a single URL input. The system performs structural parsing, semantic code understanding, metadata generation, tag extraction, review synthesis, and improvement recommendations — all orchestrated through a LangGraph-based state pipeline.
RepoMetaAgent transforms raw repositories into structured, publication-ready intelligence artifacts including:
Title generation
Short and long summaries
Structured metadata
Extracted and validated keywords
Missing documentation detection
Code review and improvement suggestions
Final unified JSON intelligence bundle
This system is designed as a core intelligence engine that can be integrated across multiple domains, including developer tooling platforms, AI agents that require repository context, repository indexing and search systems, documentation automation pipelines, and software quality dashboards, enabling scalable and structured repository understanding.
True mastery of a complex repository demands more than a cursory glance; it requires a deep, architectural synthesis of its structure, intent, and inherent code quality—a process that simply cannot scale through manual effort alone. While standard AI summarization often falters under the weight of excessive token limits and fragmented file relationships, leaving behind inconsistent metadata and unpredictable results, RepoMetaAgent introduces a paradigm shift. By orchestrating a sophisticated multi-agent system over a meticulously structured shared state, it decomposes even the most intricate codebases into actionable intelligence, ensuring that no nuance is lost and every insight is grounded in deterministic precision.
RepoMetaAgent follows a deterministic assembly-line multi-agent architecture implemented using LangGraph StateGraph.
Instead of conversational agent chatter, the system uses:
Directed Acyclic Graph (DAG) execution
Structured shared JSON state
Explicit input/output contracts per agent
Schema-validated outputs
Conflict resolution node
The pipeline is powered by Groq LLM inference for ultra-fast structured generation.
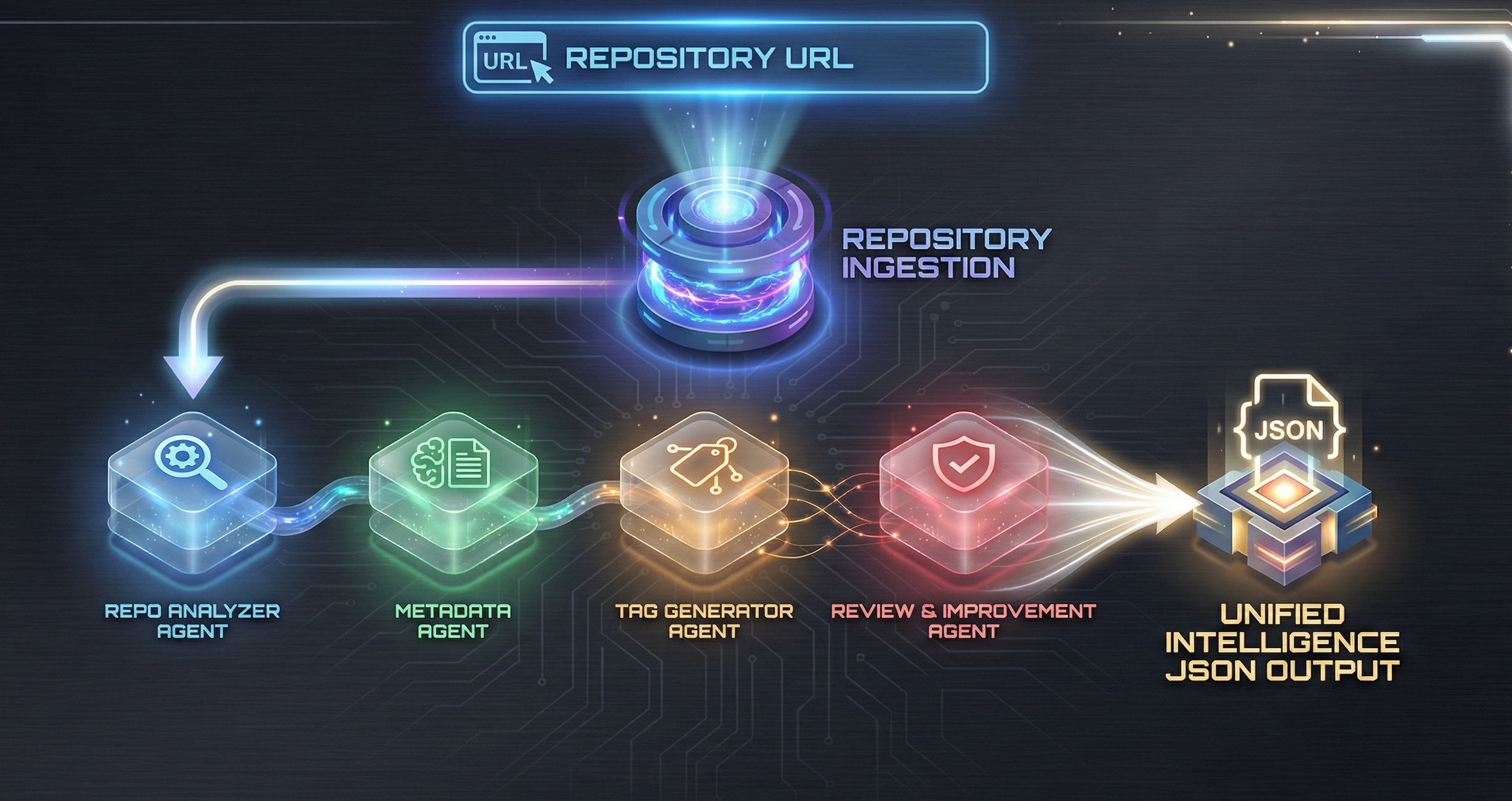
Each stage enriches the shared state rather than replacing it.
The agent is responsible for cloning and parsing the repository, extracting the directory structure, identifying critical files such as README, LICENSE, and CONTRIBUTING, detecting missing documentation, extracting raw textual and code content, performing structural analysis, and generating an initial pool of keywords for downstream processing.
This component consumes the README, structural insights, and the extracted keyword pool to generate a refined set of metadata, including a repository title, short and long summaries, detailed overview notes, and use case classification.
Output is structured and schema-validated.
This stage performs multi-strategy keyword extraction by combining gazetteer-based methods, SpaCy-driven NLP keyword detection, and LLM-based semantic keyword generation, followed by type classification (such as framework, language, domain, and tool) and a selector mechanism to finalize a consistent set of canonical tags.
Conflict resolution removes duplicates and noisy tags.
Acts as convergence node.
This component consumes outputs from the Repo Analyzer, Metadata Agent and Tag Generator to produce a comprehensive evaluation of the repository, including a code review summary, improvement recommendations, a best practices checklist, potential refactoring suggestions, a missing documentation report, and an overall repository maturity score.
This stage validates cross-agent consistency before generating final output.
RepoMetaAgent does not rely on conversational memory.
All agents operate on a single unified JSON state bundle, where each step produces a new immutable version of the state rather than modifying it in place. Every downstream agent only consumes explicitly declared fields from this structured state, and execution follows a strict DAG-based order to ensure determinism. This design improves reproducibility, enables strong fault isolation between steps, supports safe retries without side effects, makes debugging straightforward through versioned state history, and enforces long-term schema stability across the system.

Every LLM interaction is governed by strict design rules, including a clearly defined system role, an explicit output schema, and enforced anti-hallucination constraints. The model is instructed not to fabricate missing files or assume unavailable context, ensuring grounded responses based only on provided inputs. All outputs must strictly adhere to a JSON-only format, enforcing structure, predictability, and machine-readable consistency across interactions.
Goal: Deterministic structured intelligence generation.
The system requires a mandatory repository URL (string) along with essential configuration inputs, including a GROQ API key, a gazetteer configuration YAML, and prompt template definitions. These form the core setup needed for execution. In addition, several optional parameters can be provided to fine-tune behavior, such as analysis depth, tag strictness mode, and the verbosity level for summarization, allowing flexible control over the system’s processing intensity and output detail.
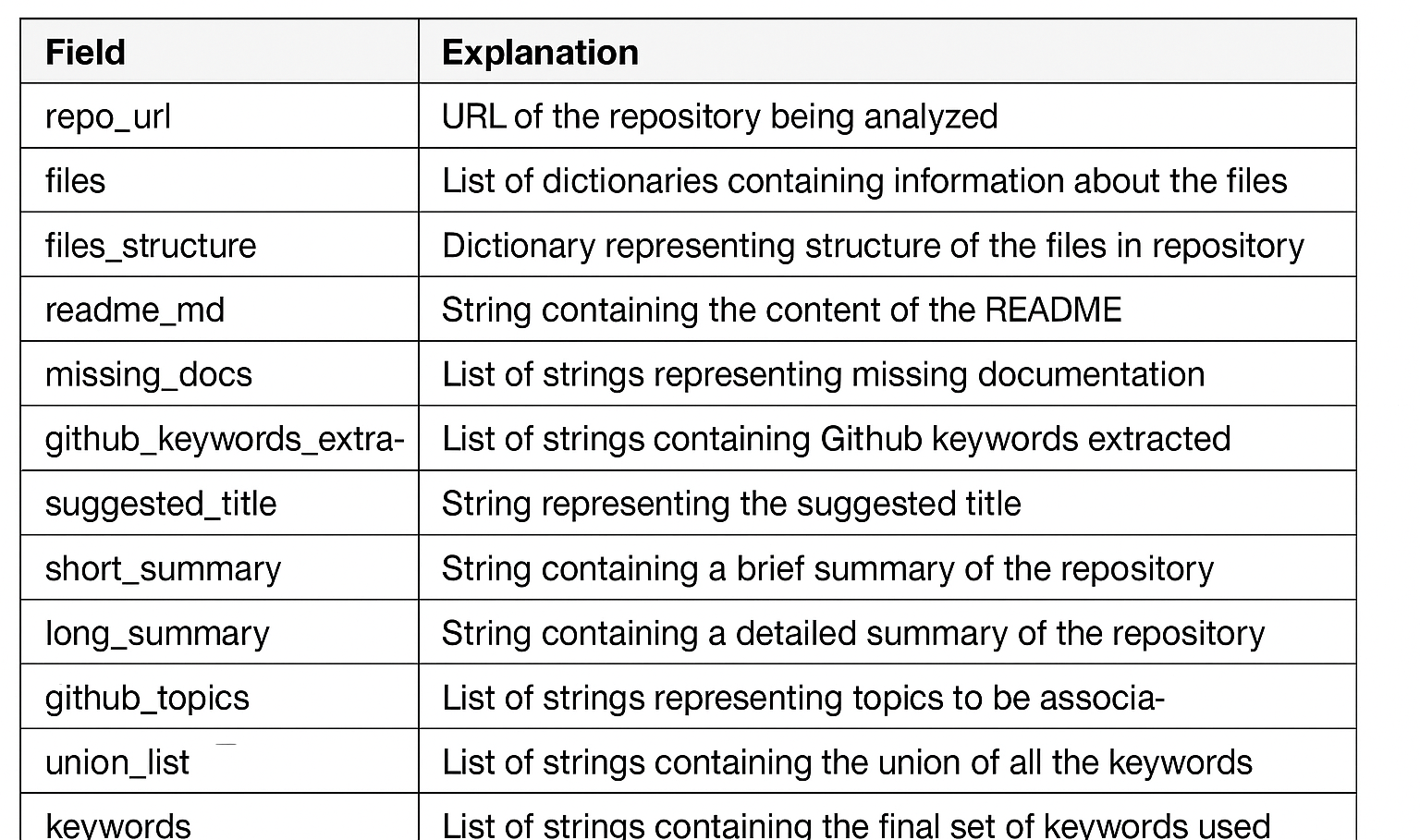
The final output is a unified JSON intelligence bundle that consolidates all generated insights into a single structured response. It includes repository metadata along with an automatically generated title, a concise short summary, and a more detailed long-form summary. The bundle also contains extracted keywords, a comprehensive code review report, actionable improvement recommendations, and a list of identified documentation gaps. Additionally, it provides a structural analysis of the repository, ensuring a complete and organized view of both content and architecture in one consistent JSON format.
RepoMetaAgent is not a single LLM prompt — it is a deterministic multi-agent intelligence pipeline.
System validation focuses on ensuring each agent behaves correctly within its defined responsibilities, while maintaining consistent and reliable state across all execution steps. Orchestration integrity is verified to confirm that the DAG execution flow remains accurate and dependency-respecting at all times. Outputs are strictly checked for schema compliance to guarantee structured and predictable results. Failure isolation mechanisms ensure that errors in one component do not cascade through the system, preserving overall stability. Finally, security robustness is continuously evaluated to defend against injection attempts, malformed inputs, and other potential vulnerabilities.
The testing framework is designed to ensure reproducibility, stability, and production readiness.
The system implements a multi-layer validation strategy:
| Test Layer | Objective |
|---|---|
| Unit Tests | Validate individual agent logic |
| Integration Tests | Validate state transitions between agents |
| End-to-End Tests | Validate complete repository analysis flow |
| Schema Validation Tests | Ensure strict JSON output contracts |
| Failure & Edge Case Tests | Validate robustness under abnormal input |
| Performance Tests | Measure inference and pipeline latency |
Each agent node is tested in isolation.
Coverage Includes:
Quality checks focus on validating core ingestion and analysis accuracy, starting with correct repository parsing and reliable extraction of the full directory tree structure. They also verify that missing files are properly detected without false positives or omissions, ensuring the system has an accurate view of repository completeness. In addition, keyword extraction is evaluated against a defined baseline to confirm consistency, relevance, and coverage across the analyzed codebase.
Validation ensures that the generated title follows the required formatting rules, while both short and long summaries adhere to their defined structural guidelines. The system output is checked for strict adherence to a deterministic JSON schema, guaranteeing consistency across runs. In parallel, hallucination guard mechanisms are enforced to prevent any unsupported or fabricated information from appearing in the final output.
Validation covers the accuracy of gazetteer-based entity mapping, ensuring terms are correctly matched to predefined references. It also checks the integrity of SpaCy-driven keyword extraction to confirm linguistic features are captured reliably. LLM-based keyword merging is verified for correctness, making sure combined outputs remain relevant and non-redundant. Finally, duplicate tag resolution logic is evaluated to ensure repeated or overlapping tags are properly consolidated without losing semantic meaning.
Review outputs are validated for consistent structure, ensuring the code review section follows a standardized and predictable format. Recommendation formatting is checked to confirm clarity, actionability, and adherence to predefined output rules. In addition, cross-agent consistency checks are performed to ensure alignment between different agent outputs, preventing contradictions and maintaining a coherent overall analysis.
Each agent test mocks LLM responses where needed to validate logic without external dependency.
Integration tests verify that state flows correctly through all nodes, ensuring each step receives the expected inputs and produces valid outputs. They confirm that required fields are available before execution begins and that no node unintentionally overwrites or corrupts existing state data. Additionally, the tests enforce correct DAG execution order, ensuring that dependencies are respected and the pipeline runs deterministically from start to finish.
These tests simulate the LangGraph StateGraph execution using synthetic repository inputs.
Validation enforces strict boundary control over data usage, ensuring downstream agents access only explicitly declared fields and nothing beyond their defined contract. At every transition, the shared state object is checked against its schema to guarantee structural compliance and prevent drift or inconsistencies. In the event of failures, retry mechanisms are designed to re-execute safely without mutating or corrupting the existing state, preserving integrity throughout the pipeline.
End-to-end testing runs the entire pipeline against a range of repository types, including small projects, medium structured codebases, documentation-heavy systems, code-dominant repositories, and incomplete repositories lacking elements like README or license files. Each execution verifies that the final unified JSON output is fully complete, with coherent metadata, relevant and meaningful tags, and logically consistent review results. It also ensures that no critical fields are left empty, maintaining output integrity across all repository conditions.
This ensures the system works in realistic production scenarios.
Every agent output is validated against strict JSON schema rules.
Strict schema enforcement guarantees that all required fields are always present and properly populated, with no null values allowed in core metadata. Tags are enforced as arrays, and the review section must follow a predefined structured format with clearly defined subsections. Free-form text outside the JSON root is disallowed, ensuring the output remains fully machine-parseable. This validation layer prevents prompt drift, blocks hallucinated or unexpected fields from the LLM, eliminates structural corruption, and ensures consistent integration across downstream systems.
The system is evaluated against a wide range of edge cases, including invalid GitHub URLs, private or inaccessible repositories, empty repositories, repositories containing only binary files, extremely large codebases, malformed README files, and even prompt injection attempts embedded within documentation. In all failure scenarios, the system is required to handle errors in a controlled manner by logging a structured error state, stopping execution gracefully, and avoiding any generation of partial or corrupted JSON output. Instead of incomplete results, it must return a clearly defined error response containing explicit error metadata for debugging and traceability.
Key risks in the system center around security and reliability threats such as prompt injection attacks embedded in repository content, malicious instructions hidden within README files, and file path traversal attempts designed to escape intended directory boundaries. Additional concerns include repository payload manipulation that can distort analysis inputs, JSON schema poisoning that can corrupt expected output structures, and excessive resource consumption that may degrade performance or cause system instability.
Input security is enforced through strict URL validation to ensure only legitimate repository sources are processed, along with repository size thresholds to prevent overload from excessively large projects. The system applies text-only file filtering to focus analysis on meaningful content while excluding irrelevant or unsafe inputs, and it explicitly filters out binary files to avoid processing unsupported or potentially harmful data.
System prompts are designed to strictly control model behavior by preventing any fabrication of missing files and blocking execution of any instructions embedded within user or repository content. Outputs are constrained to JSON-only formatting to ensure structured, machine-readable results, while also prohibiting any exposure of internal system details, configurations, or metadata.
Each agent is restricted to operating strictly within its permitted fields, with no access to or reliance on hidden memory shared across nodes. State changes are handled through immutable transitions, meaning every step produces a new version of the state rather than modifying previous data, ensuring traceability, isolation, and predictable behavior throughout the pipeline.
All Markdown input is sanitized to remove or neutralize potentially unsafe or malformed content before processing. The system also enforces strict output rules by rejecting any unstructured responses, ensuring that only properly formatted, schema-compliant data is allowed through the pipeline.
RepoMetaAgent uses a deterministic DAG-based architecture built on LangGraph StateGraph.
Core Improvements Over Basic LLM Summarization
| Traditional Approach | RepoMetaAgent |
|---|---|
| Single prompt | Multi-agent assembly line |
| No structure guarantee | Strict JSON schema |
| No validation | Cross-agent validation |
| Context overload | Chunked structured ingestion |
| Hallucination prone | Guarded prompt templates |
| No retry logic | Fault-tolerant node execution |
The system enforces deterministic execution by following a strictly defined DAG, ensuring every agent runs only after its dependencies are satisfied and never executes prematurely. Communication between all components is handled through a structured, versioned JSON state bundle, which acts as the single source of truth across the pipeline. The architecture is modular by design, allowing individual agents to be upgraded, replaced, or refactored without impacting the rest of the system. In addition, the node graph is fully extensible, enabling new capabilities—such as security scanners or UML generators—to be integrated seamlessly without disrupting existing workflow integrity.
Threat Model:
The system is designed around a strict threat model that eliminates unsafe execution paths and enforces controlled behavior at every layer. It disallows arbitrary shell execution and restricts all file operations to controlled, validated access patterns. All inputs are schema-validated to prevent malformed or unexpected data from entering the pipeline, while dedicated prompt injection mitigation rules block attempts to override or manipulate system instructions. File traversal protections ensure the system cannot access unauthorized paths, and outputs are strictly limited to JSON-only formatting to maintain structure and predictability. In addition, hallucination constraints are enforced to prevent the model from generating unsupported, fabricated, or out-of-scope information.
Optional future hardening:
Security is reinforced through static code scanning to detect unsafe patterns, misconfigurations, and potential vulnerabilities before execution. Dependency vulnerability checks are performed to identify and flag known security issues in third-party packages, ensuring the software stack remains safe and up to date. Additionally, a sandbox execution layer isolates runtime processes, preventing any harmful actions from affecting the host system or leaking beyond controlled boundaries.





Clone the repository:
git clone https://github.com/your-org/repo-meta-agent.git
cd repo-meta-agent
Create environment:
python -m venv venv
Activate:
Windows:
venv\Scripts\activate
MacOS/Linux:
source venv/bin/activate
Install dependencies:
pip install -r requirements.txt
Set API key:
GROQ_API_KEY="your_api_key_here"
Run pipeline:
python code/_Runner.py
To support reliable production operation, RepoMetaAgent integrates a structured monitoring and observability approach that enables developers to track system behavior, diagnose issues, and evaluate performance. The pipeline generates structured logs capturing key execution events, including node start and completion times, processed repository identifiers, and error details when failures occur. Pipeline tracing allows developers to follow the execution path of each analysis job across the directed acyclic graph, improving transparency and simplifying debugging. Performance metrics such as pipeline latency, node execution time, and LLM inference duration provide insights into system efficiency and help identify performance bottlenecks. These observability features can be integrated with external monitoring tools to create dashboards, trigger alerting mechanisms, and monitor system health in real time, ensuring that the repository intelligence pipeline remains stable, traceable, and scalable in production environments.
Every cutting-edge system operates within a defined technical horizon, and RepoMetaAgent is no exception. To maintain its high-velocity performance at scale, the platform leans on the power of Groq acceleration, focusing its intelligence on sophisticated static analysis rather than active code execution. While its deep semantic insights are naturally shaped by the current boundaries of LLM capabilities, the system is optimized for text-based codebases, intentionally bypassing binary files to preserve analytical focus. Furthermore, as repository complexity grows, the system navigates the balance between comprehensive depth and the logistical realities of token consumption, ensuring that even within these constraints, the delivered intelligence remains sharp, secure, and deterministic.
The evolution of RepoMetaAgent is directed toward a future where repository intelligence is not just observational, but deeply analytical and predictive. The upcoming roadmap envisions a platform that transcends metadata extraction to offer a full-spectrum architectural audit, beginning with the seamless integration of static code analysis and the automated generation of UML diagrams to visualize complex logic. By implementing a repository health scoring model and security vulnerability scanning, the system will transform from an analyzer into a guardian, proactively identifying risks and structural decay.
Looking further ahead, the intelligence engine will expand into cross-repository comparative intelligence and similarity searches, allowing developers to map patterns across entire ecosystems. To achieve unprecedented precision, we are moving toward fine-tuned, repo-specific embedding models, ensuring that the system doesn't just read code—it masters the unique vernacular of your specific project. This is the path toward a truly autonomous, self-documenting, and security-aware intelligence layer for the modern development lifecycle.
RepoMetaAgent is released under the MIT License, enabling broad adoption across research, academic, and commercial environments. Users are permitted to use, modify, distribute, sublicense, and integrate the system into proprietary or open-source projects, provided that the original copyright notice and license terms are preserved. The software is distributed “as is,” without warranty of any kind, express or implied, including but not limited to fitness for a particular purpose or non-infringement. Any third-party dependencies—including language models served via Groq or NLP libraries such as spaCy—remain subject to their respective licenses, and users are responsible for ensuring compliance when deploying the system in production environments. Redistribution of modified versions must clearly indicate changes made to the original implementation.
RepoMetaAgent demonstrates how deterministic multi-agent orchestration can move repository analysis beyond superficial summarization into structured, machine-consumable intelligence. By combining DAG-based coordination, schema-enforced LLM outputs, multi-strategy keyword extraction, and cross-agent validation, the system provides reproducible, scalable, and production-ready repository insights from a single GitHub URL. Its architecture prioritizes modularity, fault isolation, and strict output contracts, making it suitable for integration into developer platforms, AI agent pipelines, search indexing systems, and documentation automation workflows. Rather than relying on a single monolithic prompt, RepoMetaAgent decomposes repository understanding into specialized stages that collectively produce consistent, high-value metadata and improvement recommendations. As software ecosystems continue to grow in scale and complexity, systems like RepoMetaAgent represent a practical shift toward automated repository intelligence that is structured, extensible, and ready for real-world deployment.