
This project implements a Retrieval-Augmented Generation (RAG) assistant capable of answering natural language questions about Ready Tensor publications using only local resources. It is built for privacy, reproducibility, and zero-cost inference by integrating Ollama’s local LLMs with ChromaDB for semantic retrieval.
The assistant allows users to query a knowledge base of AI/ML publications offline, with no reliance on external APIs or cloud services. It leverages vector similarity search and local inference to deliver context-aware answers.
Developers and researchers often struggle to extract meaningful insights from dense technical documentation or AI/ML publications. Although large language models offer a powerful solution, most existing implementations depend heavily on cloud infrastructure. This introduces several issues, including high API costs, query latency, and concerns about data privacy.
To address these challenges, the assistant was designed as an offline-capable solution. It enables semantic search and answer generation directly from local publication files, without using any heavy frameworks like LangChain or SQLAlchemy. The result is a lightweight, reproducible tool that works across a wide range of Python environments.
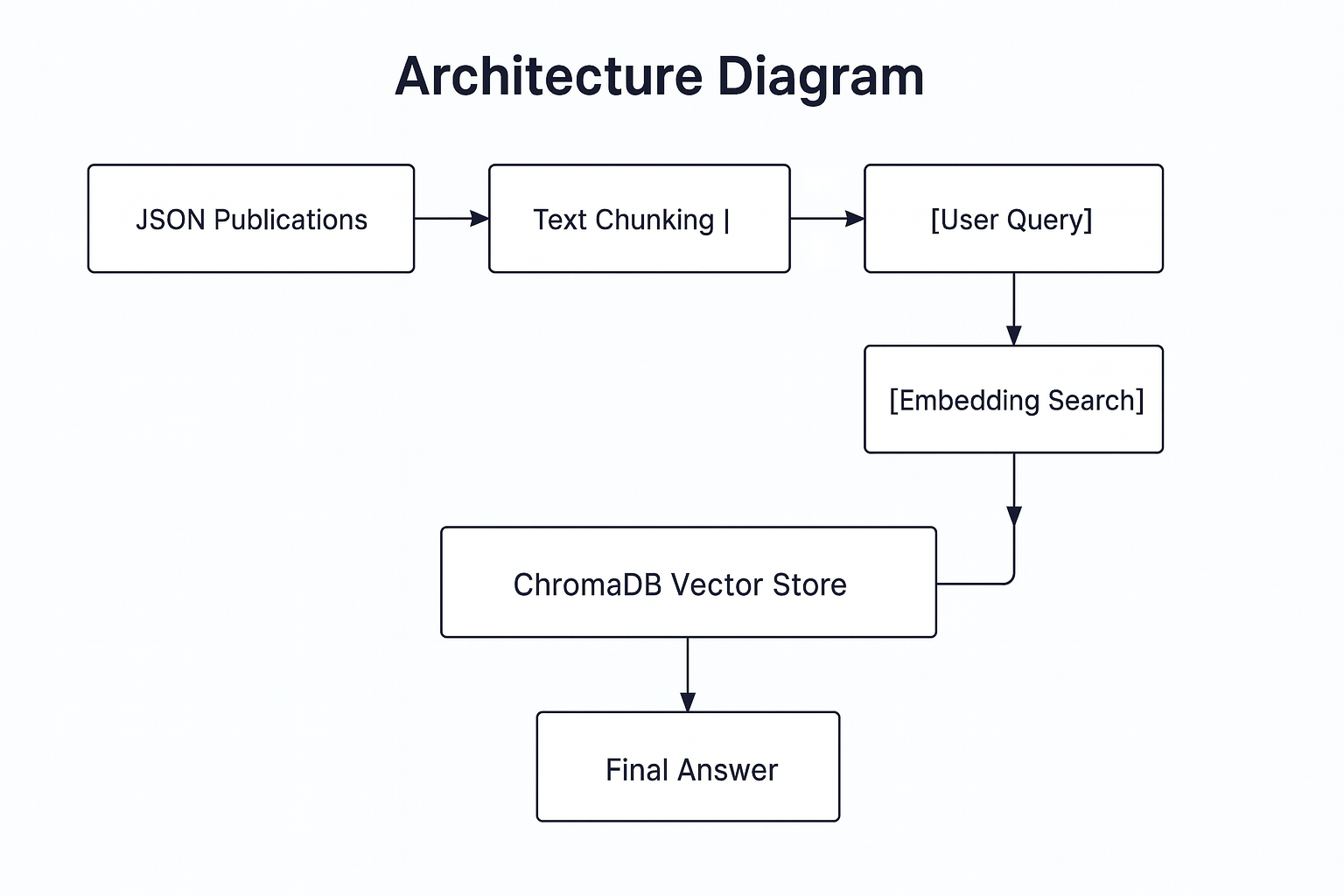
The assistant functions as a streamlined RAG pipeline, written from scratch and running entirely on local hardware. It uses Ollama for both embedding and language model inference, and ChromaDB for storing and querying vectorized data. Ready Tensor publications are parsed from JSON files, chunked into smaller sections, embedded, and stored locally. Once the setup is complete, users can initiate a command-line interface to interact with the system, asking technical questions and receiving answers directly from relevant publication content.
The assistant is fully functional offline once the necessary models are downloaded. Its dependency list is deliberately minimal—limited to ChromaDB, NumPy, and Requests—to support easy setup across different environments. By default, it uses the llama3.2
model, but can be configured to run with larger or alternative models like llama3.1 or qwen2.5, as supported by Ollama.The architecture avoids all external orchestration tools, focusing instead on direct integration between embeddings, vector search, and generation. It uses nomic-embed-text for embeddings, stores vectors in ChromaDB, and passes top-ranked chunks to Ollama for final answer generation.
“How does UV compare to pip and poetry?”
→ Retrieves citations from relevant publications and explains technical trade-offs.
“How do you add memory to RAG applications?”
→ Walkthrough with step-by-step advice from related Ready Tensor entries.
“What are best practices for repository structure?”
→ Summarizes tiered framework: Essential, Professional, Elite.
On first run, the assistant initializes embeddings and sets up the local vector database in approximately 15 seconds. Inference speed depends on model size: the llama3.2
model typically responds within 1 to 2 seconds, while larger models like llama3.1 may take 4 to 6 seconds. Memory usage during execution is around 2GB, which can be adjusted by switching to lighter or heavier models. Importantly, once created, embeddings are saved locally and reused in future sessions, avoiding redundant computation.At present, the assistant does not retain conversational context between questions. It also requires the user to manually run Ollama and download models before use. Hardware capabilities directly impact performance, and while the assistant is optimized for efficiency, larger models will naturally demand more memory and compute.
Planned improvements include support for conversational memory and follow-up prompts. A graphical web interface built with Gradio or Streamlit is also under consideration, along with expanded input types including PDF documents, tables, and image-based data. Finally, the project may evolve into a web API using FastAPI or OpenAPI for easier integration into external systems.
The assistant is built using Python 3.10 and relies on Ollama for local inference and embeddings. ChromaDB handles vector similarity search, and publication content is ingested in JSON format as exported from the Ready Tensor platform.
git clone https://github.com/hakangulcu/ready-tensor-rag-assistant cd ready-tensor-rag-assistant
chmod +x setup.sh ./setup.sh source rag_env/bin/activate
ollama serve ollama pull llama3.2:3b ollama pull nomic-embed-text
python rag_assistant.py