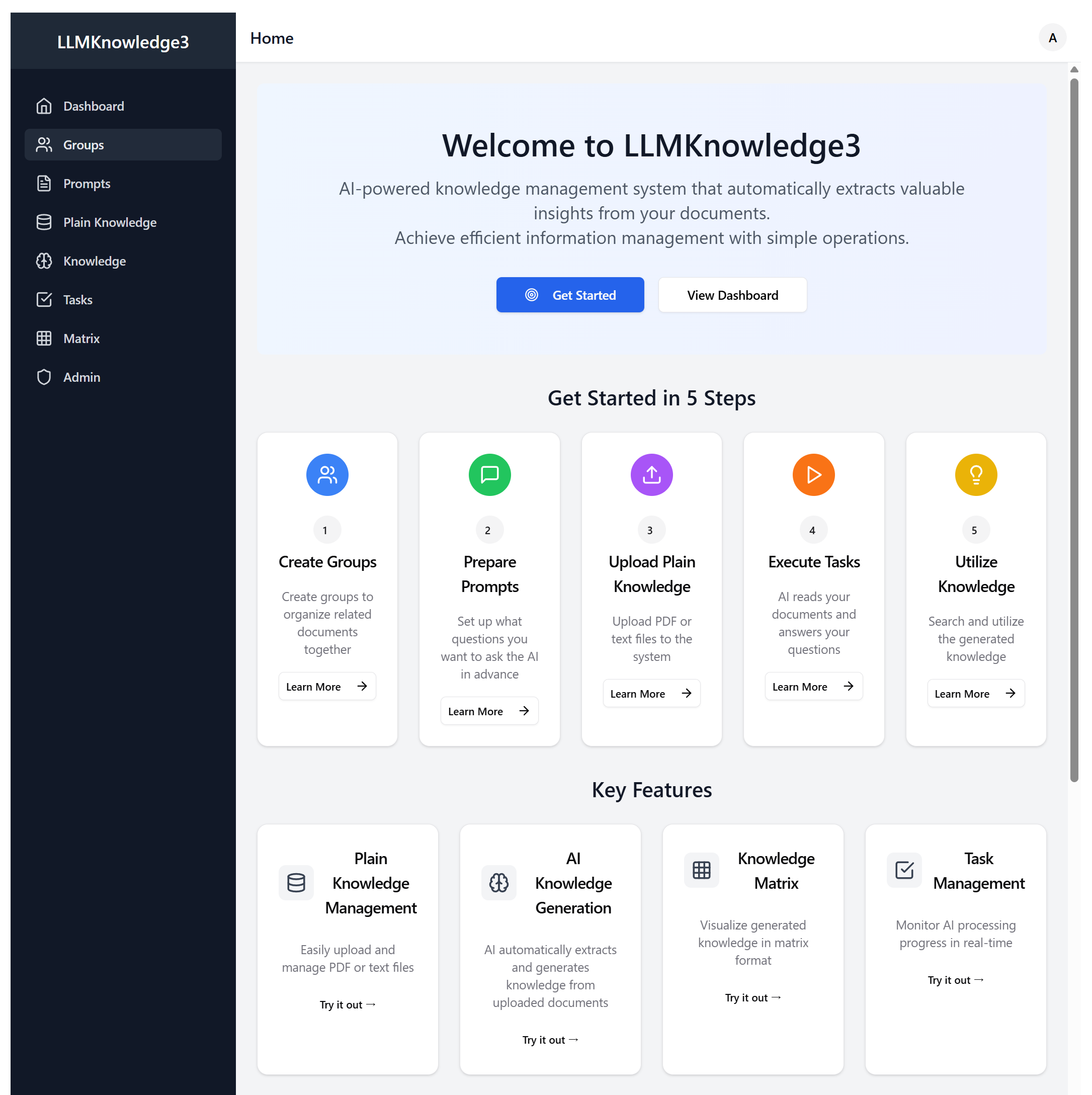
Figure 1-1: LLMKnowledge3 Homepage with Modern Interface
Remember LLMKnowledge2? It was pretty cool for extracting knowledge from documents automatically, but let's be honest - it was more of a proof of concept than something you'd want to use every day. LLMKnowledge3 changes all that.
We've completely rebuilt the system from the ground up. Now it's a proper web application that you can actually use in your organization, with multiple users, a clean interface, and APIs that let you integrate it with your existing systems.
The big difference? LLMKnowledge2 was like having a powerful tool in your garage that only you knew how to use. LLMKnowledge3 is like having that same power, but now it's packaged in a way that your whole team can use - and it looks good doing it.
Here's what we've completely rebuilt:
Everything is now API-first: Now everything has a proper REST API. Want to integrate it with your existing systems? No problem. Want to build your own interface on top of it? Go for it. The API handles everything the web interface can do, and more.
A real web application: LLMKnowledge3 has a modern React interface that works on your phone, tablet, or desktop. You can actually see your knowledge matrices in real-time, track processing progress, and manage everything from a browser.
Multiple users, proper security: Your whole team can use it now. We've built in user accounts, role-based permissions, and data isolation. Your documents stay yours, admin users can manage the system, and everyone gets their own workspace.
No more server juggling: Remember setting up LLMKnowledge2 and task2knowledge separately? Those days are over. Everything's integrated into one system now. Deploy once, use everything.
The Frontend (What You See):
The Backend (What Does The Work):
The Infrastructure (Deploy Without Drama):
We've built this with a clean separation that actually makes sense:
The Frontend (What You Interact With): A React app that looks good and works everywhere - your phone, tablet, laptop, whatever. It adapts to your screen and doesn't make you squint at tiny buttons.
The Backend (The Brain): FastAPI handling all the heavy lifting - user logins, AI processing, task management, and serving up data through clean APIs. It's fast, well-documented, and doesn't break when you look at it funny.
The Database (Where Everything Lives): SQLAlchemy managing your data - user accounts, documents, generated knowledge, system settings. Start with SQLite for testing, move to PostgreSQL when you're ready for production.
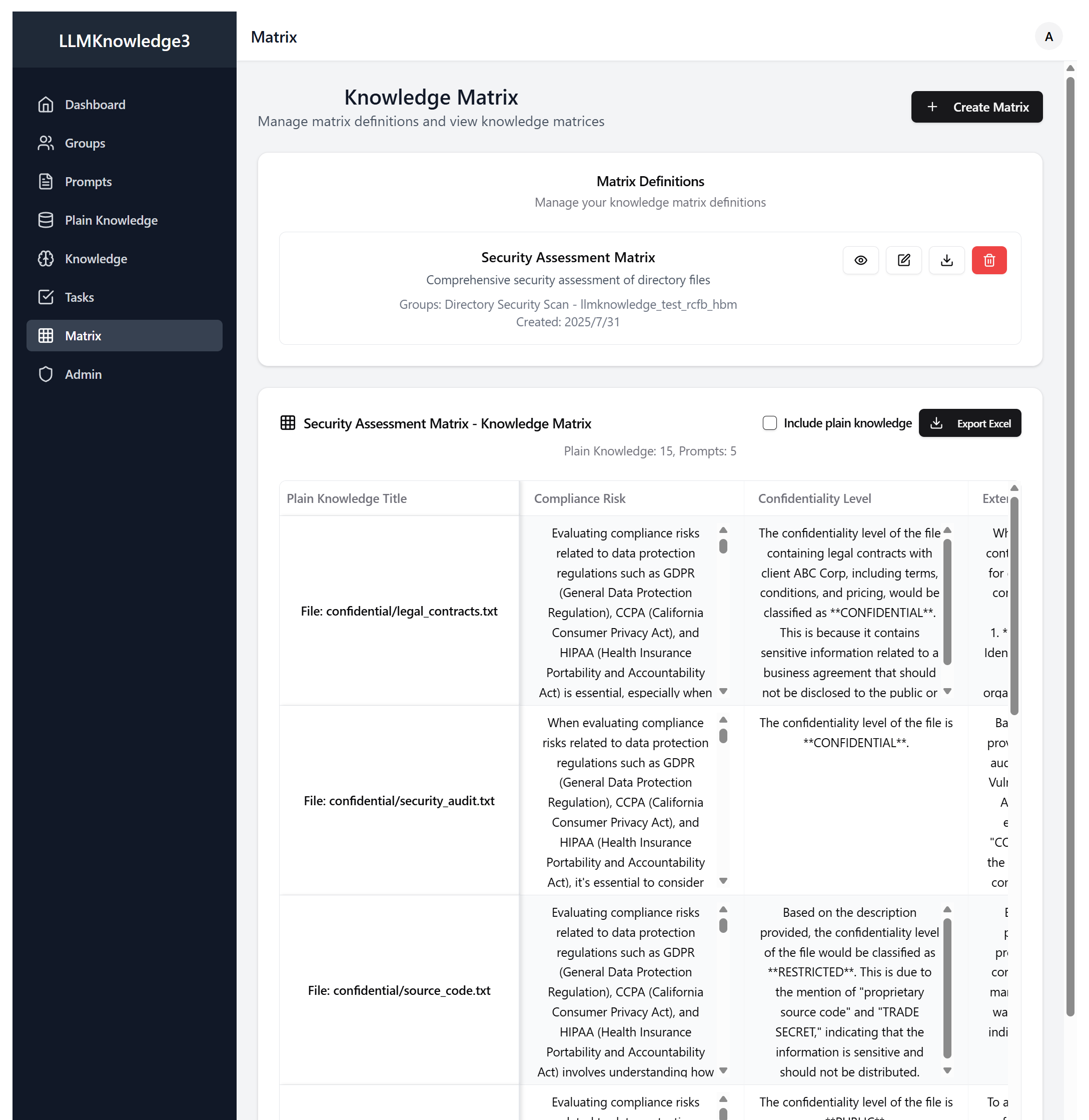
Figure 2-1: Interactive Knowledge Matrix with Real-time Data
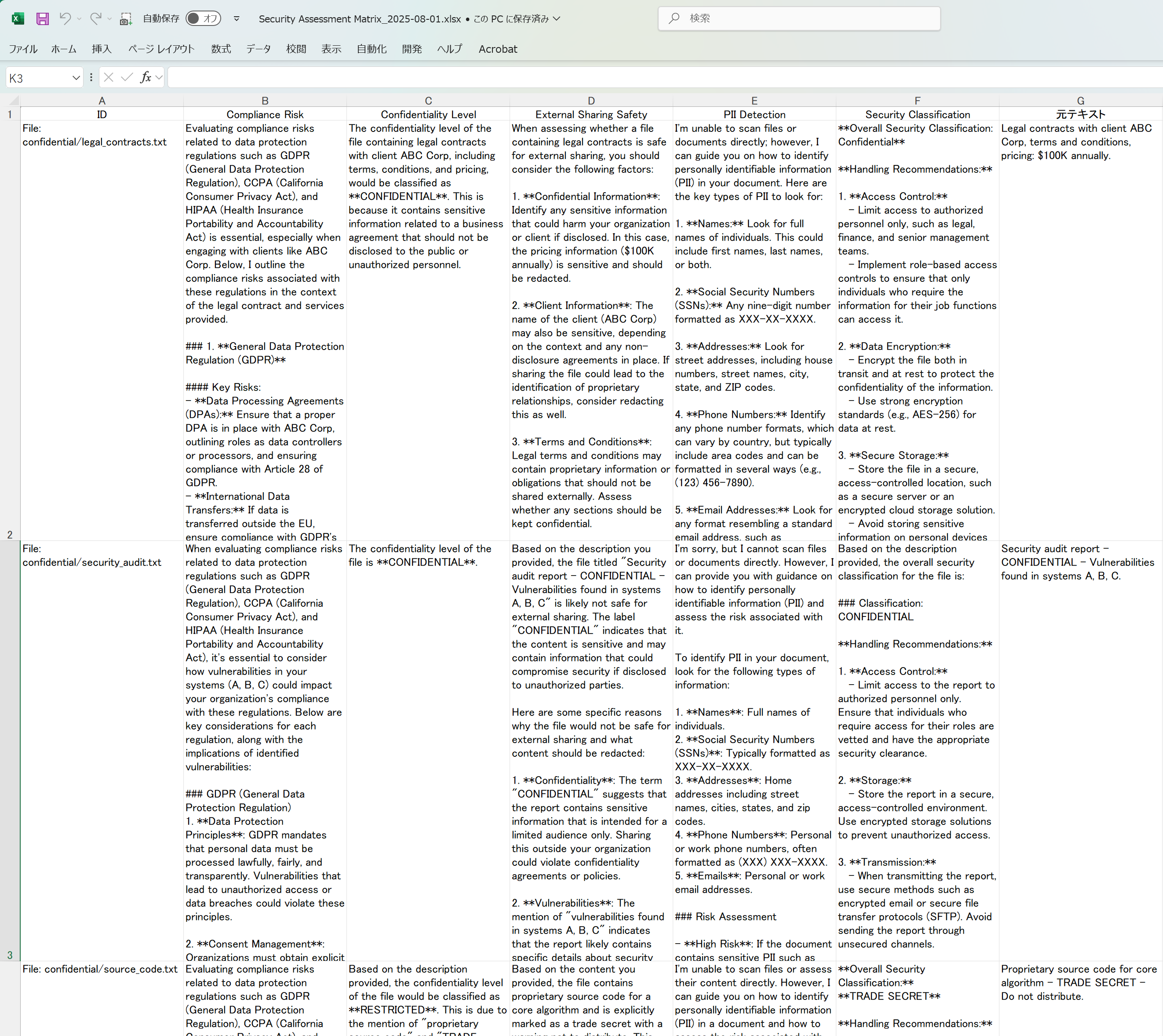
Figure 2-2: Knowledge Matrix Excel File
This was the big missing piece in LLMKnowledge2. Sure, you could export to Excel, but who wants to export to Excel every time they want to see what's happening?
See Your Results Live: The knowledge matrix updates in real-time as your documents are processed. No more guessing what's happening - you can watch your knowledge base grow.
Actually Usable Interface: Sort it, filter it, search through it. Find what you need without opening Excel file. Toggle between different views depending on what you're looking for.
Know Where It Came From: Every piece of knowledge shows you exactly which document it came from. Click through to verify, check context, or just satisfy your curiosity.
Finally, you can let your whole team use this without worrying about security or people seeing each other's stuff:
Proper User Roles: Admins can manage the system and see usage stats. Regular users get their own workspace and can't mess with other people's data. Simple, secure, sensible.
Your Data Stays Yours: Each user's documents and knowledge are completely separate. No accidental data leaks, no privacy concerns, no "oops, I can see everyone's files" moments.
Usage Controls: Set limits on AI API usage so nobody accidentally burns through your OpenAI credits in one afternoon. Fair usage for everyone, with monitoring so you can see who's using what.
Secure Authentication: JWT tokens, proper session management, secure password handling. All the security stuff you expect, without making login a pain.
We built this API-first, which means you can integrate it with whatever you're already using:
Document Processing: Send documents via API, check processing status, get results back. Perfect for automating workflows or building it into existing document management systems.
Knowledge Search and Retrieval: Query your knowledge base programmatically. Filter by document, prompt, date, whatever you need. Build custom dashboards or integrate with other tools.
User Management: Integrate with your existing user systems. Create accounts, manage permissions, track usage - all through clean API endpoints.
Event Notifications: Set up webhooks to get notified when processing finishes, errors occur, or other events happen. No more polling APIs to check status.
Here's where this gets interesting. With the API and web interface, you can actually solve real business problems:
The Problem: You're a VC or running an accelerator, and you get dozens of business plans every week. Reading through them all takes forever, and it's hard to evaluate them consistently.
The LLMKnowledge3 Solution:
Upload business plans through the web interface or API
Set up evaluation prompts that ask the right questions:
Get a comprehensive evaluation matrix showing scores and detailed feedback across all criteria
Make better decisions faster with consistent evaluation criteria
Integration Options: Hook this into your existing deal flow software. New business plans come in, get automatically evaluated, and you get a summary report in your inbox.
Why This Works: You get consistent, thorough evaluations without spending hours reading every plan. Save your time for the promising ones.
The Problem: You're a professor with 200 students, they all submit papers, and you need to grade them consistently against multiple rubric criteria. Your weekend is gone.
The LLMKnowledge3 Solution:
Upload all papers at once - drag and drop or API integration with your LMS
Define your rubric as prompts:
Get detailed feedback for every paper across all rubric criteria
Review and adjust the AI assessments before finalizing grades
Integration Options: Connect with Blackboard, Canvas, Moodle, or whatever LMS you're using. Papers get auto-evaluated, you review the results, students get detailed feedback.
Why This Works: First-pass grading that's consistent and thorough, with detailed feedback that helps students improve. You review and adjust, but you're not starting from scratch every time.
The Problem: Your company has thousands of files on servers, SharePoint, everywhere. Some contain personal information, some are confidential, some are public. You need to know what's what for compliance and security, but manually reviewing everything would take years.
The LLMKnowledge3 Solution:
Point it at your file servers - API integration scans directories and processes documents in batches
Security evaluation prompts analyze each document:
Get a security assessment matrix for your entire document repository
Implement appropriate controls based on the classifications and recommendations
Integration Options: Hook into your document management system for ongoing classification of new files. Integrate with security tools for automated policy enforcement.
Why This Works: Systematic security assessment of your entire document landscape. Know what you have, where it is, and how to protect it. Perfect for compliance audits and security planning.
We've tried to make this as painless as possible:
What You Need:
Development Setup:
Follow the GitHub README - we've actually kept it up to date this time. Poetry handles Python dependencies, npm handles frontend stuff. No "works on my machine" surprises.
Production Deployment:
Docker containers, traditional servers, cloud platforms - whatever you prefer. Environment variables for configuration, database migrations that actually work, and deployment scripts that don't assume you're psychic.
We use environment variables and config files like normal people:
AI Provider Setup: Use OpenAI, Claude, Gemini, or your own local models. Set primary and backup providers so you don't get stuck if one service is down.
Database Choice: SQLite for getting started quickly, PostgreSQL when you need the real deal. Switch between them without rewriting everything.
Security Settings: JWT configuration, API rate limits, CORS policies, user permissions - all the security stuff you need, with sensible defaults.
Performance Tuning: Adjust chunk sizes, parallel processing, retry policies. Start with the defaults, tweak as needed based on your hardware and usage patterns.
Because nobody likes systems that fail silently:
User Activity Logs: See who's doing what, track API usage, monitor system performance. Useful for debugging and usage planning.
Task Progress: Watch document processing in real-time. See what's working, what's stuck, what failed and why.
System Health: Built-in health checks and status endpoints. Monitor with your existing tools or use the web interface.
Admin Interface: Web-based admin panel for user management, system configuration, and monitoring.
We've built something that should work, but we want to prove it actually does:
Business Plan Evaluation Testing:
Academic Grading Verification:
Security Classification Validation:
Better AI Integration: As new AI models come out, we'll integrate them. Multi-modal processing for images and videos in documents is on the roadmap.
Smarter Analytics: Trend analysis, pattern recognition in your knowledge, predictive insights based on what you've processed before.
Enterprise Features: Single sign-on, integration with enterprise databases, workflow automation. All the stuff that makes IT departments happy.
Performance Improvements: Faster processing, better scalability, handling larger document volumes. Because nobody likes waiting.
This is all available on GitHub (https://github.com/daishir0/LLMKnowledge3). We welcome contributions:
If you find bugs, have ideas, or want to contribute code, jump in. The project is designed to be extensible and we're happy to review pull requests.
We're always looking for partners who want to push this further:
If you're working on related problems or have interesting use cases, let's talk.
LLMKnowledge3 takes the cool concept from LLMKnowledge2 and makes it something you can actually deploy and use in your organization. We've gone from "interesting proof of concept" to "production-ready platform that solves real problems."
The planned real-world testing will prove whether this actually works as well as we think it does. The open source approach means it'll keep getting better as more people use it and contribute to it.
Most importantly, we've built something that makes AI knowledge processing accessible to regular people, not just data scientists. Whether you're a VC evaluating business plans, a professor grading papers, or an IT admin trying to secure your document repositories, you can actually use this system to solve real problems.
That's the real achievement here - taking powerful AI capabilities and packaging them in a way that's actually useful for everyday business operations. No PhD in machine learning required.
LLMKnowledge3 is a platform with lots of potential, and we're looking for partners to help make it even better.
We're especially interested in working with:
If you want to collaborate, have ideas, or just want to chat about AI knowledge management, check out our GitHub (https://github.com/daishir0/LLMKnowledge3) or reach out directly. We're always interested in real-world use cases and practical feedback.
The best software comes from solving real problems for real people. Help us make this better.