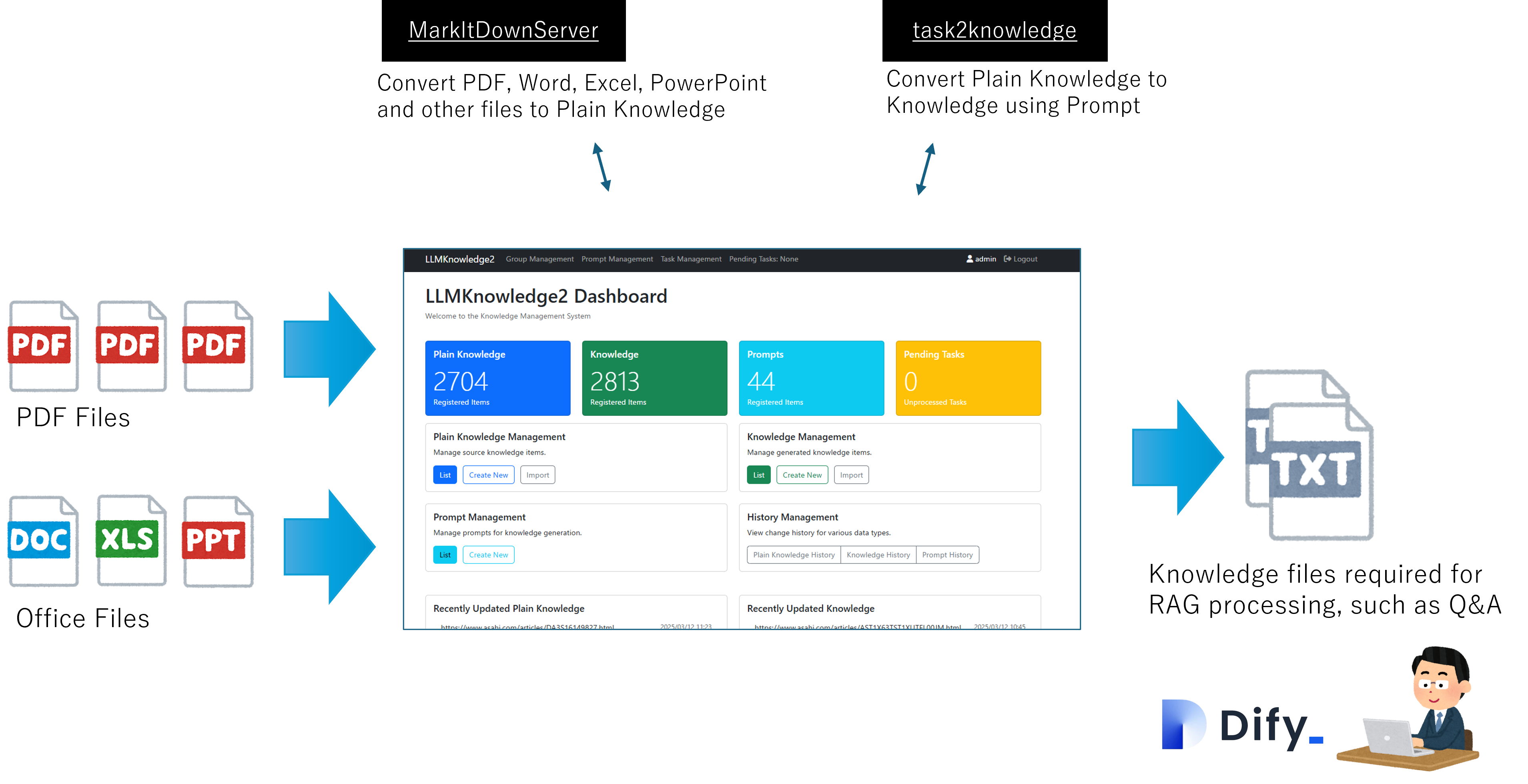
Figure 1-1: LLMKnowledge2 and RAG(Dify) Integration
The rapid advancement of generative AI technology has opened new possibilities for leveraging organizational document data as knowledge assets. Particularly, with the increasing adoption of RAG (Retrieval-Augmented Generation) systems, there is a growing demand for structured knowledge. However, this requires efficient conversion of unstructured document data into AI-ready structured knowledge.
For instance, traditionally, creating Q&A-format knowledge from product manuals required careful reading, anticipating potential questions, and extracting or creating appropriate answers. This process demanded significant time and effort for understanding context and organizing related information. However, with the advanced language understanding capabilities of modern generative AI, this process can now be significantly automated.
LLMKnowledge2 addresses this challenge through an innovative approach called knowledge prompts. A notable feature is the ability to create and refine prompts interactively within the system. Users can gradually improve prompts while verifying the quality of generated knowledge, enabling the extraction of high-quality knowledge optimized for organizational requirements.
The system's key features are as follows:
First, it provides an integrated environment from prompt creation to knowledge generation. Users can instantly adjust prompts while verifying the quality of generated knowledge. This iterative improvement process enables optimal knowledge extraction according to organizational requirements. Furthermore, by applying different knowledge prompts to the same plain knowledge, information can be extracted from various perspectives.
Second, it offers flexible switching between generative AI engines. Users can select appropriate engines according to requirements, whether cloud-based generative AI like OpenAI and Anthropic, or locally running LLMs. This is particularly important for addressing data confidentiality requirements and regional service availability restrictions.
Third, it supports diverse input formats and batch processing. The system can process plain knowledge in various formats including PDF, Word, Excel, PowerPoint, various text files, and web pages. Multiple plain knowledge sources can be processed concurrently, enabling rapid conversion of large volumes of data. Progress monitoring and bulk result management are also straightforward.
The generated knowledge can be utilized in advanced question-answering systems through integration with RAG systems like Dify. For example, it's possible to build a system that quickly responds to customer inquiries using Q&A knowledge generated from product specifications. This enables practical application of the generated knowledge in actual business operations.
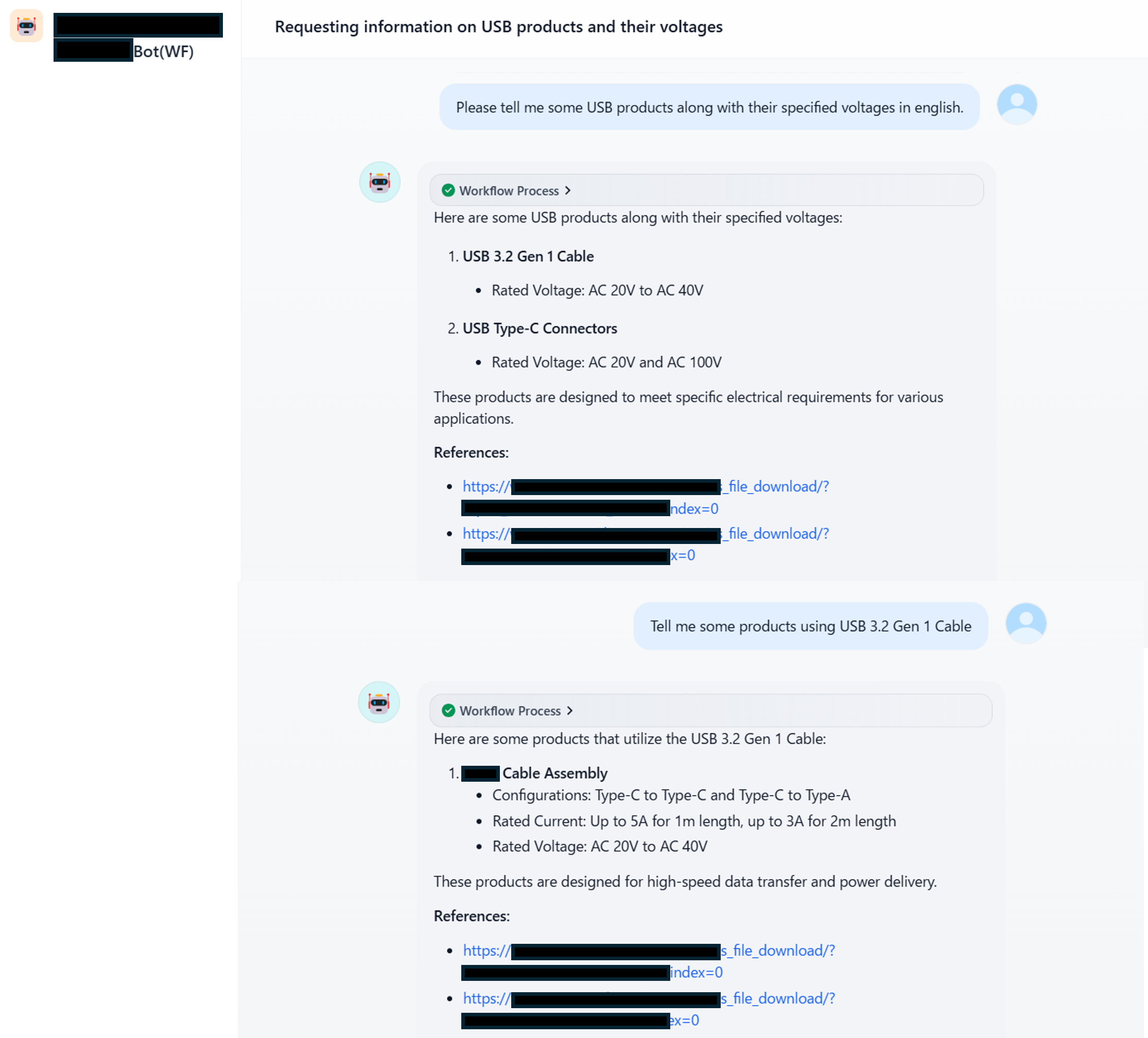
Figure 1-2: Dify
This paper details the LLMKnowledge2 system, explaining its value, technical implementation, and practical deployment and operation methods. In particular, we demonstrate its potential as a flexible knowledge generation foundation, leveraging features such as interactive prompt improvement and support for various generative AI engines.
The primary value of LLMKnowledge2 lies in enabling automated large-scale knowledge conversion and multi-perspective knowledge extraction from the same data. This chapter explains the system's specific value and actual evaluation results.
First, regarding large-scale knowledge conversion automation, the system can process multiple plain knowledge sources in batch and convert them into structured knowledge. For example, when processing 44 PDF files of product specifications as input, we successfully generated 3,085 Q&A-format knowledge entries. This represents a significant efficiency improvement compared to manual processing.
Next, regarding multi-perspective knowledge extraction, the system features flexible knowledge prompt configuration as a distinctive function. Different knowledge prompts can be applied to the same plain knowledge to extract information from various perspectives. For example, after generating basic Q&As from product specifications, the same document can be used to generate troubleshooting Q&As.
The ability to select generative AI engines is also an important value. Different organizations and regions have varying available generative AI services, and cloud-based services may not be usable due to data confidentiality requirements. Our system supports various generative AI engines including OpenAI, Anthropic, and locally running LLMs, allowing selection of appropriate engines based on circumstances.
To verify system effectiveness, we conducted specific evaluations. To assess the quality of Q&A knowledge generated from product specifications, we prepared 40 test questions and verified response accuracy. The results showed accurate answers for 29 out of 40 questions (72.5%), and correct information sources (URLs) were provided for 38 out of 40 questions (95%).
This result has significant practical implications. First, the 72.5% accuracy rate is sufficient for a first-response generation system assuming human verification. More importantly, the high 95% rate of correct information source provision enables quick manual verification of response accuracy and modifications when necessary. For example, when handling product specification inquiries, operators can provide accurate responses quickly by referencing generated answers while verifying the relevant sections in the information sources.
Regarding processing performance, using 10 parallel processes, we could process 44 PDF files in approximately 15 minutes. This processing speed meets practical requirements. For example, it can process over 1,400 PDFs within an 8-hour workday, sufficiently covering document processing demands for many organizations. Furthermore, increased parallelization enables handling of larger-scale processing.
The utilization of generated knowledge in RAG systems also provides significant value. For example, in sales support scenarios, it can provide real-time responses to questions during business negotiations. While traditional search systems only presented related documents based on keyword matching, RAG systems can generate responses by understanding context and combining necessary information. Furthermore, since all responses include source URLs, quick responses can be provided while ensuring accuracy.
Thus, LLMKnowledge2 functions not just as document processing automation but as an organizational knowledge utilization foundation. It provides particular value in three areas:
The technical implementation of LLMKnowledge2 focuses on three key elements: parallel processing for rapid knowledge generation, support for diverse input formats, and generative AI engine switching mechanism. This chapter explains these technical implementation details.
The system adopts a hierarchical architecture with two dedicated servers. The first server (MarkItDownServer) handles text conversion from various document formats, while the second server (task2knowledge) executes conversion from plain knowledge to knowledge. This two-layer structure enables optimization specialized for each process.
First, regarding parallel processing for rapid knowledge generation, the system implements a parallel processing mechanism capable of processing multiple plain knowledge sources simultaneously. Document splitting size is adjustable according to knowledge generation purposes. The basic settings specify minimum 2,000 and maximum 3,000 characters, which is appropriate context volume for generating one Q&A set. Notably, rather than simple mechanical splitting by character count, the system performs context-aware splitting. Even when exceeding the minimum size (2,000 characters), it maintains context consistency by treating up to appropriate sentence breaks as one processing unit.
Additionally, knowledge prompts can control generated Q&A density by including instructions like "output at least three Q&As." This enables appropriate granularity of knowledge extraction according to document characteristics and usage purposes.
Next, regarding support for diverse input formats, MarkItDownServer can process various formats of plain knowledge including PDF, Word, Excel, PowerPoint, various text files, and web pages. This is achieved by implementing text extraction modules for each format and converting to a unified internal format. The extracted text maintains the original document structure and format, ensuring accurate source references in generated knowledge.
Generative AI engine switching is implemented with flexible control through a configuration file (config.yaml). This configuration includes various parameters necessary for practical operation, such as chunk size control (chunk_size, max_chunk_size), API retry control (max_retries, retry_delay), and rate limit control (api_rate_limit). This enables appropriate operational settings according to usage environment and requirements.
Error handling is implemented with particular emphasis on stability in large-scale document processing. For API call failures, it executes the configured number of retries (max_retries) with intervals (retry_delay) to recover from temporary failures. Additionally, it maintains stable processing by controlling API call intervals (api_rate_limit).
Thus, LLMKnowledge2 functions as a practical knowledge generation foundation through its two-layer server architecture, flexible context-aware splitting process, and detailed operational parameter control. In particular, it achieves production-ready robustness through consistent processing flow from document processing to knowledge generation and flexible configuration according to operational environment.
The most important elements in deploying and operating LLMKnowledge2 are creating knowledge prompts and appropriately configuring generative AI engines. This chapter explains these practical aspects.
Creating knowledge prompts is a core element in effectively utilizing the system. Here is a typical prompt example for Q&A generation:
Please convert the following {source QA text} into a new format, referring to the examples and adding {{reference}} values.
Example 1:
Q: What applications is the ABC series suitable for?
A: The ABC series is suitable for antenna connections in navigation and other equipment.
Example 2:
Q: What applications is the DEF2 series suitable for?
A: The DEF2 series is a small coaxial connector suitable for antenna connections in marine navigation equipment.
Reference URL: {{reference}}
{source QA text}=
This prompt's features include:
Prompts are crucial elements controlling the quality and quantity of generated Q&As. For example, including instructions like "output at least three Q&As" allows adjustment of generated knowledge density. Additionally, prompts can be gradually improved while verifying actual output results.
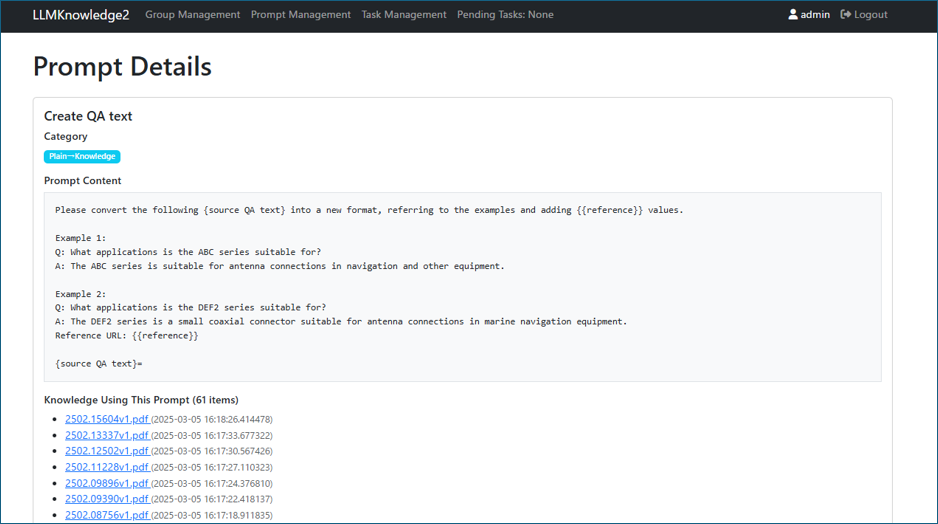
Figure 4: Prompt Details Page
The system consists of three components, each available on GitHub:
LLMKnowledge2 (Main System)
MarkItDownServer
task2knowledge
Each component can be set up following detailed installation instructions provided in GitHub repositories. In particular, configuration file examples and operation verification procedures are provided, enabling step-by-step implementation.
During system operation, the following parameters are adjusted according to the environment:
Document Processing Settings
API Control Settings
These settings are centrally managed in the config.yaml file and can be flexibly adjusted according to operational environment and requirements.
The basic system usage procedure is as follows:
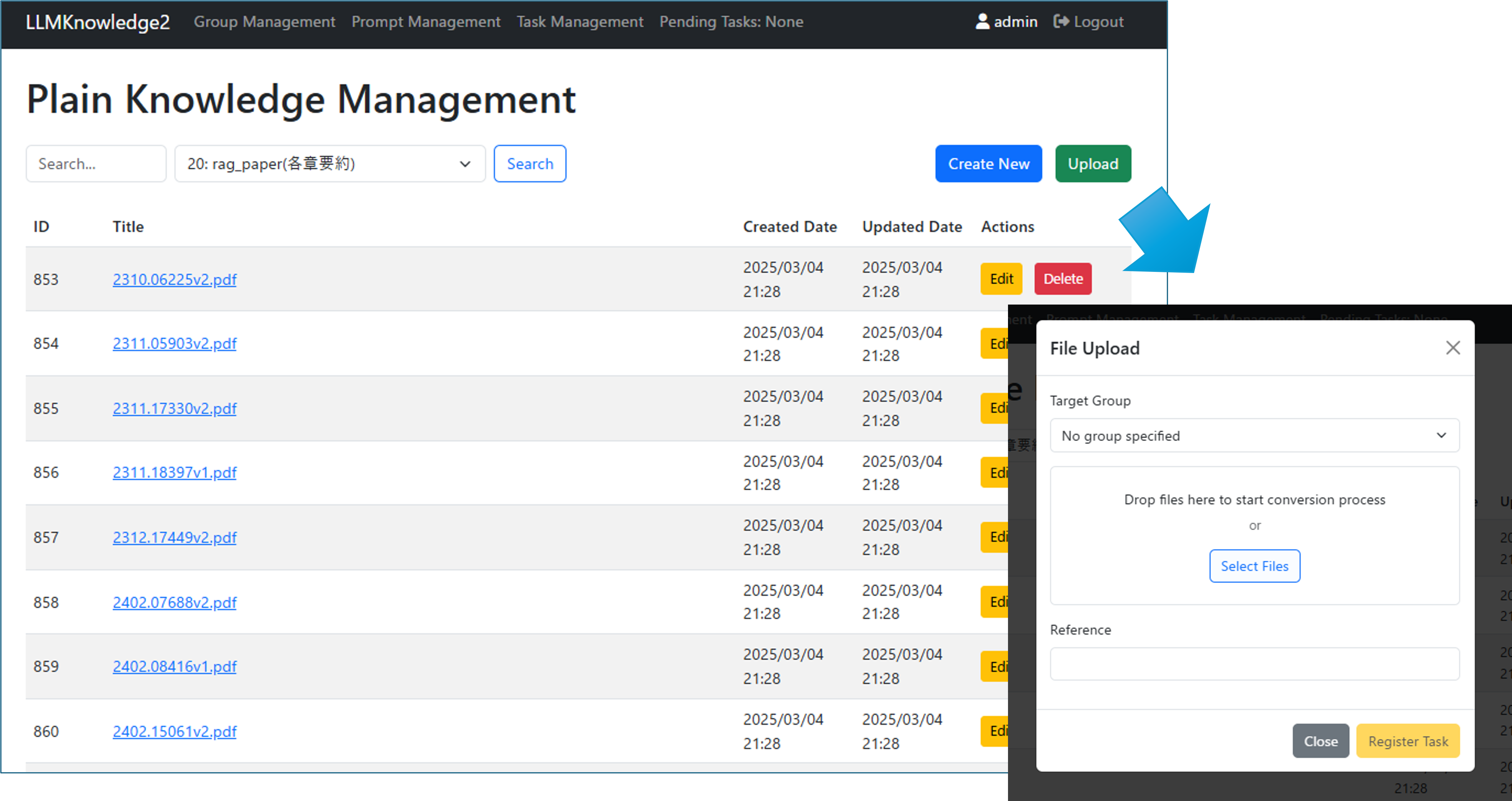
Figure 4-1: Plain Knowledge Management Page and Knowledge File Upload Page
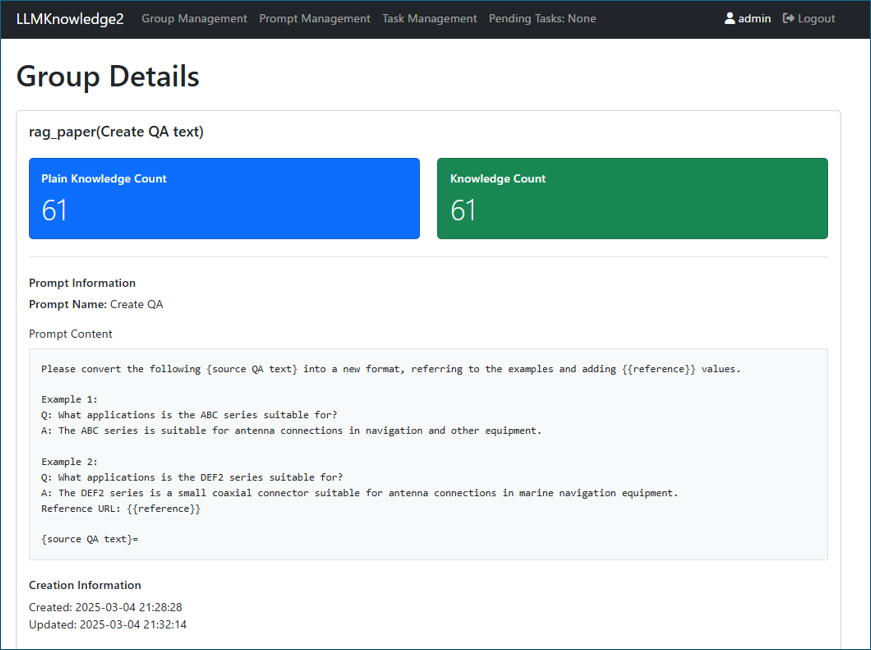
Figure 4-2: Group Dtails Page and Prompt Selection
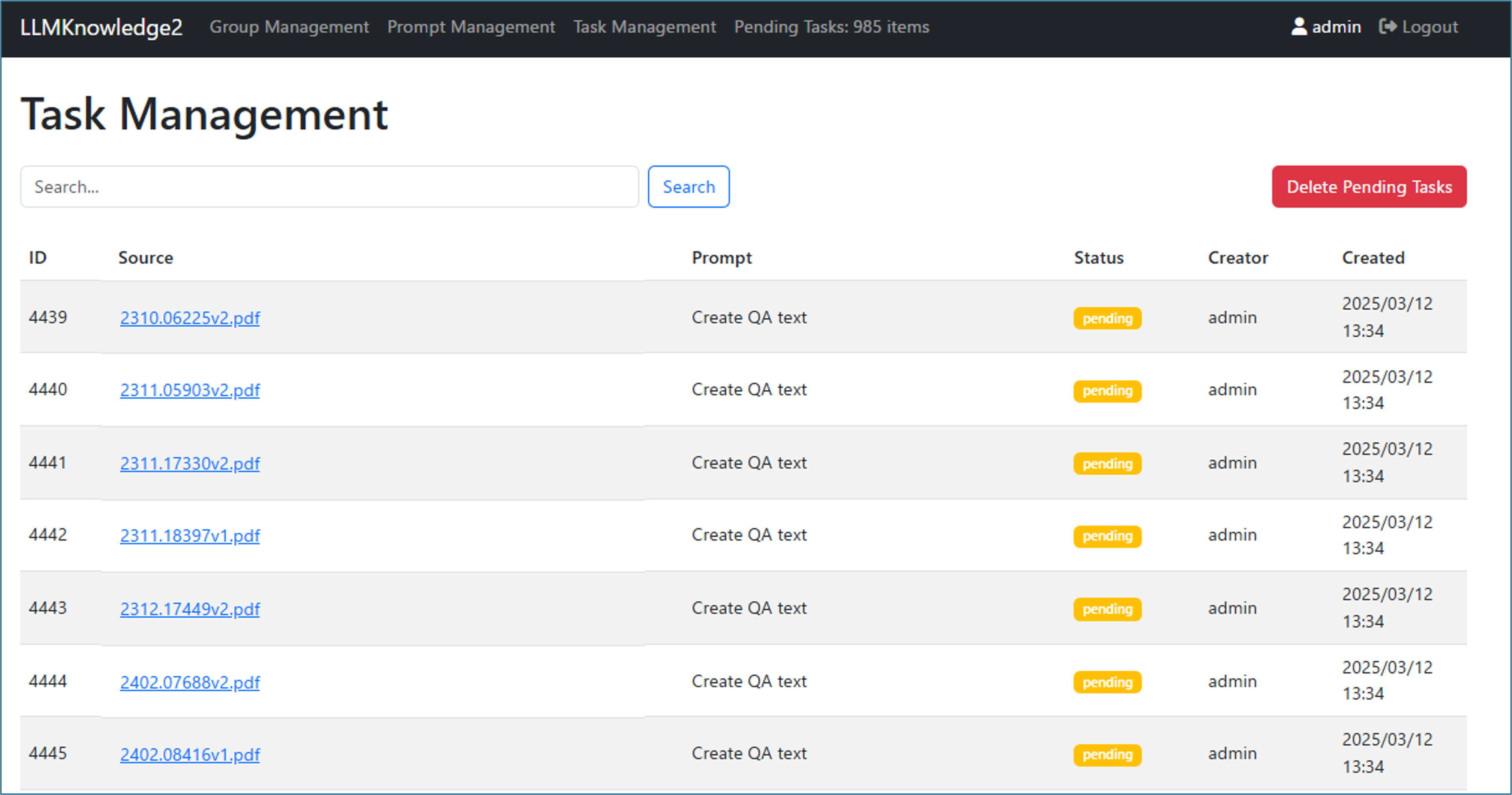
Figure 4-3: Task Management Page and Pending Tasks
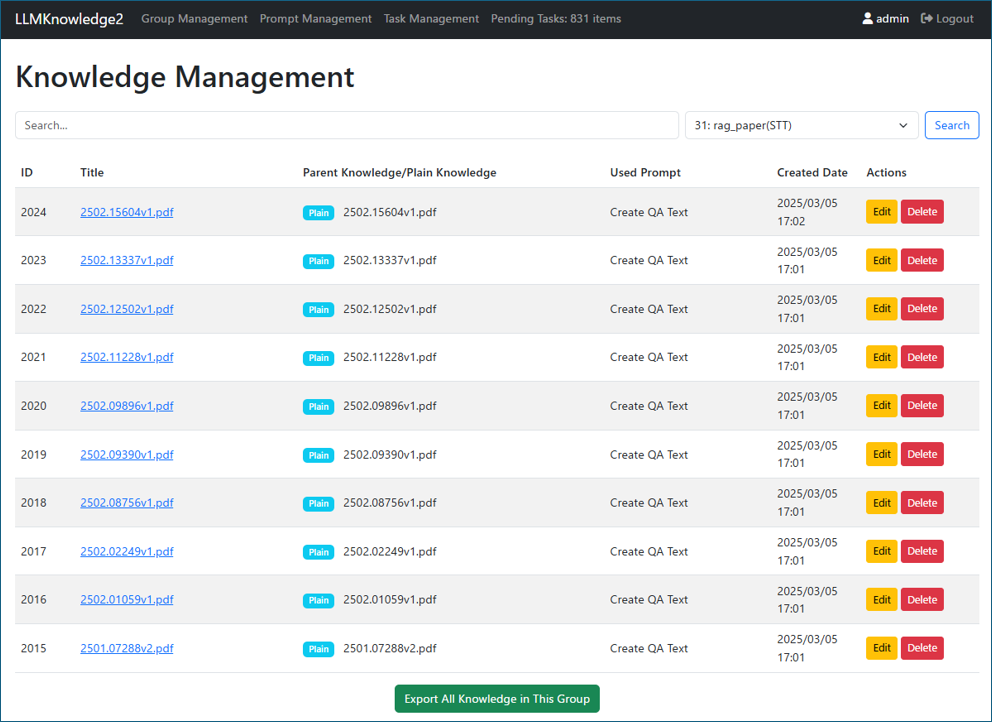
Figure 4-4: Knowledge Management Page and Processed Plain Knowledge
Thus, LLMKnowledge2 serves as a comprehensive knowledge generation foundation provided as open source, with systematic support from deployment to operation. In particular, practical utilization is facilitated through the provision of concrete prompt examples and configuration parameters.
This research presents the LLMKnowledge2 framework as an evolving system with significant potential for further development. The author, whose research interests span natural language processing, system development, and generative AI, is actively seeking collaboration partners (individuals and organizations) to expand this work. If you are interested in joint research opportunities or can recommend suitable journals or academic publications for this work, please feel free to reach out. Your expertise, perspectives, and suggestions for potential publication venues would be greatly appreciated in advancing this research.
