
The system is designed to ingest legal text files (statutes, case summaries, contracts), convert them into semantic embeddings, store them in a vector database, retrieve the most relevant segments based on user questions, and generate context-grounded, non-advisory explanations using an LLM. The assistant emphasizes safe, transparent, document-based reasoning and includes clear boundaries to avoid providing legal advice. The entire pipeline is implemented using LangChain, ChromaDB, SentenceTransformers, and an LLM provider (OpenAI/Groq/Google Gemini). This project demonstrates the foundational concepts of RAG, agentic workflows, and vector search using simple, modular code.
Legal documents—such as statutes, case judgments, contracts, and regulatory guidelines—are often lengthy, densely written, and filled with specialized terminology. While these documents are essential for governance and justice, their complexity makes them difficult to interpret for non-experts and time-consuming even for trained professionals. Traditional keyword-based search methods offer limited assistance, as legal reasoning depends heavily on context, semantic similarity, clause-level interpretation, and cross-referencing, rather than exact word matches.
To address these limitations, modern AI systems increasingly rely on semantic understanding rather than surface-level text matching. One such approach is Retrieval-Augmented Generation (RAG), which combines information retrieval with large language models (LLMs) to produce grounded, context-aware responses. Instead of relying solely on the LLM’s internal knowledge, RAG systems dynamically retrieve relevant information from external document collections and use it as factual context for response generation.
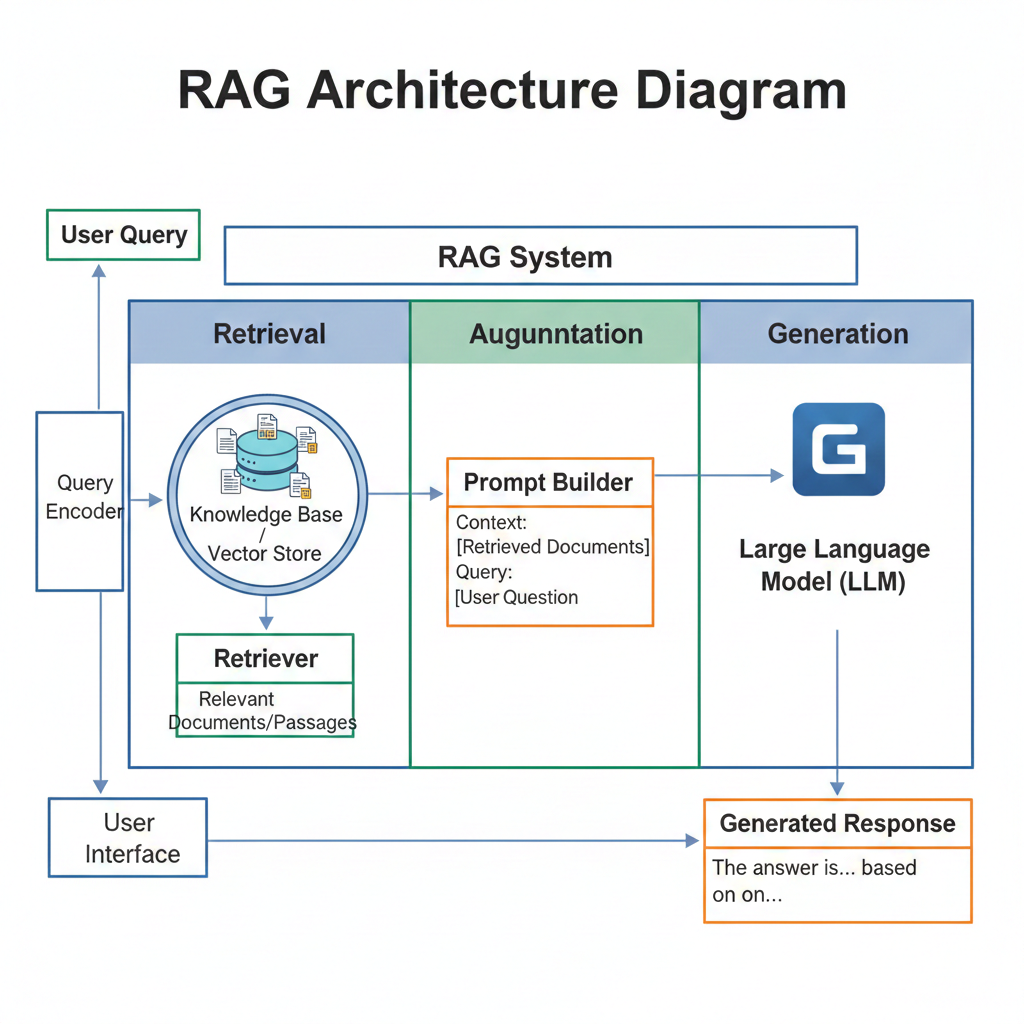
The RAG workflow can be broken down into three main stages: Retrieval, Augmentation, and Generation.
Action: When a User Query (question) is received, the system uses a Query Encoder to convert it into a numerical representation (vector).
Search: This query vector is used to search a Knowledge Base/Vector Store (a database of proprietary documents, articles, etc., also stored as vectors).
Output: A Retriever identifies the most Relevant Documents/Passages from the knowledge base that are semantically similar to the user's query.
Action: The Prompt Builder takes the original User Query and the Retrieved Documents.
Context Creation: It formats them together into a single, comprehensive Prompt. The retrieved documents serve as the context for the LLM.
Example Prompt Structure: "Based on the following context: [Retrieved Documents], answer this question: [User Query]."
Action: The augmented prompt is sent to the Large Language Model (LLM).
Response: The LLM uses the provided context (the retrieved documents) to formulate an accurate, relevant, and grounded Generated Response, reducing the chance of hallucinations and providing current information.
With the emergence of Retrieval-Augmented Generation (RAG) systems, it is now possible to:
This project implements a lightweight, domain-focused Legal Document RAG Assistant that enables:
semantic search over fragmented legal texts,
safe interpretation of retrieved context,
AI-generated summaries and explanations without giving legal advice.
This project fulfills all the requirements by implementing:
document loading
chunking
embedding and vector storage
retrieval
RAG prompt construction
LLM pipeline with safe constraints
as outlined in the ReadyTensor Module 1 specification.
The system is built using a modular pipeline consisting of seven main stages:
.png?Expires=1781544572&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=Q8mS-bRzyPZbiJ7JUnTTvLM31ZhLSkPNZt8yZefW2-FJKOEFrYNcvFW6zZgYoZRbQNqhy0OCaxCEzR8NI6hbgG5TCx0uDADKaNODvsYMJCa5-0Z9lQy360UE18brC-i1HwtRaQdY2DMqV2zVVIbgxovgvsoKQMGAFxJjWkNf0gtvDLtfl0ZnYTj-hQB3lZ2j3hdlAQcDAWI446LdSAM8Gb~6qkXlHiNSAKuZYaJuCiixwA~fgSJUZFQWaSkEp6LyuQ-r59DbB4t8UF0ntN07pddfowZyQ-d8aEEADqVUPnluhXIASnT-VSdjRMkA1UB4831Nmbe7kz3gen8yfM2NQA__)
Legal text files placed in the data/ folder are loaded using a simple loader.
Metadata such as source and doc_type are extracted automatically.
Example types:
def load_documents() -> List[Dict[str, Any]]: results: List[Dict[str, Any]] = [] if not DATA_DIR.exists(): print(f"[WARN] data directory not found: {DATA_DIR}") return results for file_path in DATA_DIR.iterdir(): if not file_path.is_file(): continue # For this project we keep it simple and support only .txt if file_path.suffix.lower() != ".txt": # You can extend this later to support PDFs, DOCX, etc. continue try: with file_path.open("r", encoding="utf-8") as f: text = f.read() except Exception as e: # noqa: BLE001 print(f"[WARN] Failed to read {file_path.name}: {e}") continue text = text.strip() if not text: continue # Simple heuristic: detect rough "type" from filename name_lower = file_path.stem.lower() if "act" in name_lower or "section" in name_lower: doc_type = "statute_or_act" elif "case" in name_lower or "judgment" in name_lower: doc_type = "case_law" elif "contract" in name_lower or "agreement" in name_lower: doc_type = "contract_or_agreement" else: doc_type = "legal_notes_or_other" results.append( { "content": text, "metadata": { "source": file_path.name, "path": str(file_path), "doc_type": doc_type, }, } ) return results
Since legal documents are long, each document is broken into overlapping text chunks.
This ensures higher recall when performing semantic search.
def chunk_text(self,text: str,chunk_size: int = 500,overlap: int = 50) -> List[str]: if not text: return [] text = text.strip() n = len(text) if n == 0: return [] chunks: List[str] = [] start = 0 # Simple character-based chunking with overlap while start < n: end = min(start + chunk_size, n) chunk = text[start:end].strip() if chunk: chunks.append(chunk) if end == n: break # move the window with overlap start = max(0, end - overlap) return chunks
Chunks are embedded using:
The embeddings capture semantic meaning rather than exact keyword matching.
A persistent ChromaDB instance stores:
embeddings
chunk text
metadata (source, document type, chunk index)
This enables fast top-k semantic similarity search during query time.
def add_documents(self, documents: List[Dict[str, Any]]) -> None: """ Process documents and add them to the vector database. Args: documents: List of documents with 'content' and optional 'metadata' """ if not documents: return all_ids: List[str] = [] all_texts: List[str] = [] all_metadatas: List[Dict[str, Any]] = [] # 1) Chunk documents and collect chunks + metadata for doc_idx, doc in enumerate(documents): content = (doc.get("content") or "").strip() if not content: continue base_meta = doc.get("metadata") or {} chunks = self.chunk_text(content) for chunk_idx, chunk in enumerate(chunks): all_texts.append(chunk) all_metadatas.append( { **base_meta, "doc_index": doc_idx, "chunk_index": chunk_idx, } ) all_ids.append(str(uuid.uuid4())) if not all_texts: return # 2) Create embeddings embeddings = self.embedding_model.encode(all_texts).tolist() # 3) Store in ChromaDB self.collection.add( ids=all_ids, documents=all_texts, metadatas=all_metadatas, embeddings=embeddings, )
When a user asks a question:
def search(self, query: str, n_results: int = 5) -> Dict[str, Any]: """ Find documents similar to the query. Args: query: Search query n_results: Number of results to return Returns: Dictionary with search results: { "documents": [...], "metadatas": [...], "distances": [...], "ids": [...] } """ query = (query or "").strip() if not query: return { "documents": [], "metadatas": [], "distances": [], "ids": [], } query_embedding = self.embedding_model.encode([query]).tolist()[0] result = self.collection.query( query_embeddings=[query_embedding], n_results=n_results, ) # Chroma returns lists-of-lists; unwrap for convenience docs = result.get("documents") or [[]] metas = result.get("metadatas") or [[]] dists = result.get("distances") or [[]] ids = result.get("ids") or [[]] return { "documents": docs[0], "metadatas": metas[0], "distances": dists[0], "ids": ids[0], }
A specialized legal-safe prompt guides the LLM to:
"""You are an assistant that helps analyze and explain legal documents.
You are NOT a lawyer and CANNOT give legal advice.
Your role is ONLY to:
- summarize the content of the provided legal documents,
- highlight relevant sections,
- explain concepts in simple language,
- compare or contrast provisions when helpful.
Follow these rules STRICTLY:
- Use ONLY the information in the context.
- If the context is not sufficient, say:
"I’m not sure based on the provided documents."
- DO NOT speculate about facts outside the documents.
- DO NOT tell the user what they "should" do, or give legal advice.
- DO NOT create or suggest legal strategies.
- If the user asks for advice, gently remind them that this is
only an educational tool and they should consult a qualified lawyer.
Context from legal documents:
{context}
User question:
{question}
Now, provide a clear, structured, and concise explanation based ONLY on the context above.
If helpful, you may:
- quote specific clauses or sections (short snippets),
- list key points in bullet form,
- mention which document or source you are referring to.
"""
The system supports multiple LLM providers via environment variables:
OpenAI (gpt-4o-mini)
Groq (Llama-3.1-8B-Instant)
Google Gemini (1.5-Flash)
The final answer is created using:
PromptTemplate → LLM → OutputParser
via a LangChain runnable chain.
The system was tested using a collection of sample legal texts, including:
Indian Contract Act – Key Sections
NDA (Non-Disclosure Agreement) Sample Contract
Fundamental Rights (Constitutional Summary)
Case Summary: Donoghue v. Stevenson
Data Protection Guidelines
Test Procedure:
Documents were placed in the data/ folder as .txt files.
The application was run using:
python src/app.py
Experimental results showed that the Legal Document RAG Assistant:
✔ Correctly retrieved relevant legal clauses
Semantic retrieval successfully matched questions to relevant sections of the Contract Act, NDA, and case summaries.
✔ Produced grounded explanations
Responses were consistent with the retrieved context and avoided hallucinations due to the strict RAG prompt.
✔ Demonstrated strong interpretability
Output included:
clause summaries,
section mentions,
bullet points,
plain-language restatements.
✔ Enforced legal-safety boundaries
The system consistently refused to give legal advice, answering with:
“I’m not sure based on the provided documents.”
when retrieval was insufficient.
✔ Worked across multiple LLM providers
OpenAI, Groq, and Gemini all generated coherent RAG-based answers.
This project demonstrates a complete end-to-end implementation of a RAG-based Legal Document Analyzer, fulfilling all requirements for AAIDC Module 1:
document ingestion
chunking
embedding
vector search
prompt construction
context-grounded LLM reasoning
The assistant is able to:
extract relevant legal information,
summarize complex clauses,
explain concepts in simple terms,
maintain safety by avoiding legal advice,
scale with additional documents and LLM providers.
This foundational architecture serves as a robust template for future modules involving:
agent workflows,
tool integration,
retrieval agents,
multi-step legal QA pipelines,
web UI deployment,
or integration with case/contract management systems.
The project successfully showcases practical use of RAG and agentic principles in a real-world legal domain.