This project presents a multi-agent system built with LangGraph for automated analysis of GitHub repositories. The system breaks down repository evaluation into smaller tasks handled by specialized agents, such as content extraction, metadata analysis, structure checking, and quality scoring. These agents work together in a structured workflow to process a repository’s README file and generate clear, structured feedback. The final output includes a summary of the project, extracted metadata, a quality score, and a pass/retry decision based on predefined rules. The goal is to show how agent-based systems can be used to improve clarity, structure, and consistency in automated codebase analysis.
README files are one of the most important parts of any GitHub repository, but their quality varies a lot across projects. Some are well structured and informative, while others are incomplete or unclear. This makes it difficult to quickly understand what a project does or how usable it is.
This project explores a multi-agent approach to solving that problem. Instead of using a single model to handle everything, the system splits the task into smaller responsibilities handled by different agents. Each agent focuses on one aspect of the repository, such as extracting information, analyzing structure, or evaluating quality.
LangGraph is used to coordinate these agents into a workflow where each step builds on the previous one. This makes the system easier to extend, debug, and reason about compared to a single monolithic model.
The system takes a GitHub repository URL as input and processes it through a series of agents. Each agent has a specific role and contributes to a shared state that is passed through the workflow.
First, the Analyzer Agent fetches the repository data using the GitHub API, including the README file and basic metadata like stars, forks, and programming language. This forms the base input for the rest of the system.
The workflow then splits into multiple parallel agents. The Content Agent extracts the project title and generates a short summary of the README. The Metadata Agent identifies keywords and generates relevant tags. The Structure Agent checks whether key sections like installation, usage, and license are present.
After that, the Quality Agent evaluates the README based on simple rules such as length, formatting, and the presence of code blocks. All these outputs are then passed to the Reviewer Agent.
The Reviewer Agent combines everything and produces the final decision. If the quality score is too low or important sections are missing, the system can trigger a retry loop for re-evaluation. The LLM agent helps in ensuring the user can interact with the system and get more clarification about the repository.
GitHub Repo URL ↓ ┌─────────────────────┐ │ Analyzer Agent │ → Fetch README + Repo metadata (API tool) └─────────────────────┘ ↓ ──────────────────────────────────────────────────────── ↓ ↓ ↓ ↓ Content Metadata Structure quality Agent Agent Agent Agent ↓ ↓ ↓ ──────────────────────────────────────────────── ↓ ↓ Reviewer Agent ↓ output ↓ Human feedback ↓ LLM agent
The Analyzer Agent is responsible for fetching the README content directly from the GitHub API. It also retrieves important repository metadata such as the number of stars, forks, and the primary programming language. This agent serves as the entry point for all repository-level understanding.
The Content Agent focuses on extracting meaningful textual information from the README. It identifies the project title and generates a concise summary that captures the core purpose of the repository in natural language.
The Metadata Agent is responsible for analyzing the README content to extract relevant keywords. These keywords are then transformed into meaningful tags that represent the core themes and functionality of the repository.
The Structure Agent evaluates the documentation quality of the repository by checking for essential sections such as Installation, Usage, and License. It also identifies any missing or incomplete documentation sections that may affect usability.
The Quality Agent computes a quality score for the README based on multiple factors including overall length, formatting consistency, and the presence of structured code blocks. This helps in assessing how well-documented the repository is.
The Reviewer Agent aggregates outputs from all previous agents and evaluates the overall system output. It generates final feedback and determines whether the repository analysis passes quality standards or requires a retry based on defined evaluation rules.
The LLM Agent enables natural language interaction with the system. It can answer user questions about the repository and also improve or refine the generated summary when additional clarity or enhancement is requested.
This system integrates multiple tools to enable intelligent agent behavior:
This tool fetches repository metadata and README content using GitHub’s REST API. It enables the system to extract structured information such as stars, forks, and primary programming language.
The system integrates Ollama as a local large language model inference engine. It is responsible for enhancing and rewriting repository summaries, improving readability, and generating higher-quality descriptions based on structured repository data. This enables offline, privacy-preserving LLM execution without relying on external APIs.
This tool processes raw README content into structured outputs. It performs tasks such as summary generation, keyword extraction (tags), and readability scoring.
git clone https://github.com/Electrobello1/LangGraph-Multi-Agent-Intelligence-Orchestration-System.git cd LangGraph-Multi-Agent-Intelligence-Orchestration-System
pip install requirements.txt
irm https://ollama.com/install.ps1 | iex
python main.py
The system was evaluated using a set of GitHub repositories with varying levels of documentation quality. The objective was to assess how well the multi-agent pipeline handles differences in structure, completeness, and clarity of README files.
The test set included:
The system returns a structured breakdown of a GitHub repository after processing its README and metadata.
Each output includes:
Repositories with clear and complete READMEs usually return:
Repositories with partial documentation:
The outputs are consistent across runs because the evaluation is rule-based.
The same input produces the same result, which makes the system predictable and easier to debug.
Each part of the result comes from a specific agent:
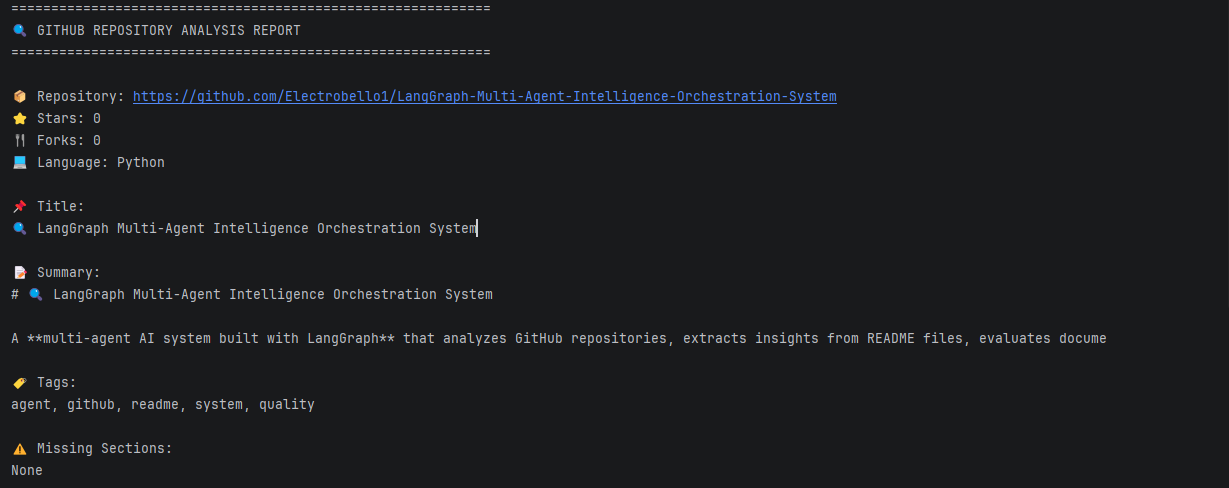
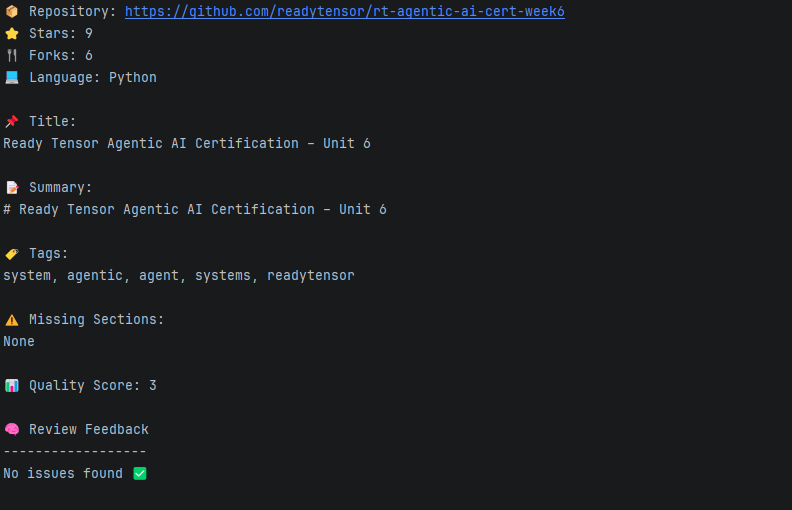
This project shows how a GitHub repository can be broken down and understood using a simple multi-agent setup instead of a single model doing everything at once. Each agent handles a specific part of the job, reading the README, pulling metadata, checking structure, and scoring quality; then everything is combined into one final result.
The main benefit of this approach is clarity. It’s easy to see what each part of the system is doing and why a repository gets a certain score or status. It also makes the system easier to adjust or improve without breaking everything.
From the results, well-documented repositories are handled smoothly, while weaker ones are clearly flagged for missing information or poor structure. The final output stays consistent and easy to interpret across different cases.
Overall, the system works well as a lightweight way to evaluate repository quality and shows how splitting a task into smaller agents can make the process more organised and practical.