High-quality code generator based on LangChain
This is a high-quality code generator based on LangChain that can generate code according to business needs, conduct code reviews, improve code, generate test cases and unit tests.
Features
- Code generation : Generate high-quality Python function code based on the business requirements submitted by users
- Code review : Comprehensively review the generated code and provide improvement suggestions
- Code improvement : Generate improved code based on review results
- Test case generation : Generate comprehensive test cases based on business requirements and code
- Unit test generation : Generate corresponding unit test code based on business requirements, code and test cases
Install
- Clone the repository:
git clone <仓库URL> cd <仓库目录>
- Install dependencies:
pip install -r requirements.txt
- Configure environment variables:
Create a .env file and add the following content:
SILICONFLOW_API_KEY="你的API密钥"
SILICONFLOW_BASE_URL="https://api.siliconflow.cn/v1/"
How to use
Command Line Interface
# 执行所有步骤 python cli.py --requirement "你的业务需求" --all # 只执行特定步骤 python cli.py --requirement "你的业务需求" --review --improve # 使用已有代码 python cli.py --requirement "你的业务需求" --code path/to/code.py --review # 指定输出目录 python cli.py --requirement "你的业务需求" --all --output-dir my_output
Available command line parameters:
--requirement,-r: Business requirements--code,-c: Existing code file path--review,-v: Generate code review--improve,-i: Generate improved code--test-cases,-t: Generate test cases--unit-tests,-u: Generate unit tests--all,-a: Execute all steps--output-dir,-o: output directory (default is "output")
Web interface
streamlit run web_app.py
In the web interface, you can:
- Enter business requirements
- Select the steps to perform
- View and download generated code, code reviews, improved code, test cases, and unit tests
- Editing the generated test case
Project Structure
.
├── app.py # 主应用程序,提供完整的顺序Chain
├── cli.py # 命令行界面,支持灵活选择执行步骤
├── web_app.py # 基于Streamlit的Web界面,提供友好的用户交互
├── chains/ # LangChain组件
│ ├── __init__.py # 初始化文件
│ ├── code_generation_chain.py # 代码生成链,根据业务需求生成代码
│ ├── code_review_chain.py # 代码评审链,对生成的代码进行评审
│ ├── code_improvement_chain.py # 代码改进链,根据评审结果优化代码
│ ├── test_case_generation_chain.py # 测试用例生成链,根据业务需求生成测试用例
│ └── unit_test_generation_chain.py # 单元测试生成链,根据生成的代码生成单元测试
├── requirements.txt # 项目依赖
└── README.md # 项目说明
Example
Business requirement examples
创建一个函数,用于解析CSV文件并提取特定列的数据,然后计算这些数据的平均值、最大值和最小值。
Generated code example
def parse_csv_and_analyze(file_path, column_name): """ 解析CSV文件并提取特定列的数据,然后计算这些数据的平均值、最大值和最小值。 Args: file_path (str): CSV文件的路径 column_name (str): 要分析的列名 Returns: dict: 包含平均值、最大值和最小值的字典 Raises: FileNotFoundError: 如果文件不存在 ValueError: 如果列名不存在或数据无法转换为数值 """ import csv # 检查文件是否存在 try: with open(file_path, 'r', newline='', encoding='utf-8') as csvfile: # 创建CSV读取器 reader = csv.DictReader(csvfile) # 检查列名是否存在 if column_name not in reader.fieldnames: raise ValueError(f"列名 '{column_name}' 不存在于CSV文件中") # 提取数据 data = [] for row in reader: try: value = float(row[column_name]) data.append(value) except ValueError: raise ValueError(f"无法将值 '{row[column_name]}' 转换为数值") # 检查是否有数据 if not data: return { "average": None, "maximum": None, "minimum": None } # 计算统计值 average = sum(data) / len(data) maximum = max(data) minimum = min(data) return { "average": average, "maximum": maximum, "minimum": minimum } except FileNotFoundError: raise FileNotFoundError(f"文件 '{file_path}' 不存在")
Generated streamlit interface example (wab_app.py)
(Generate high-quality code, code reviews, test cases, and unit tests based on business needs)
Example input: Create a function that parses a CSV file, extracts data from specific columns, and then calculates the average, maximum, and minimum values of that data.
1. Generated code
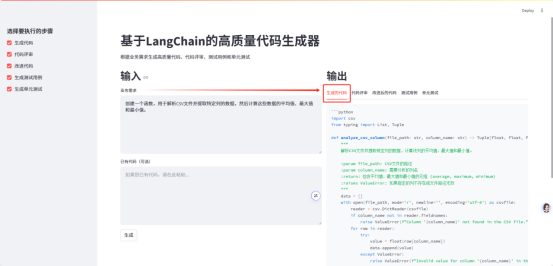
2. Code Review
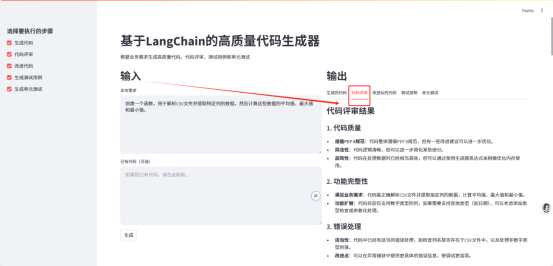
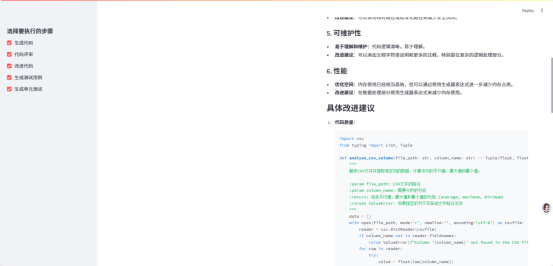
3. Improved complete code
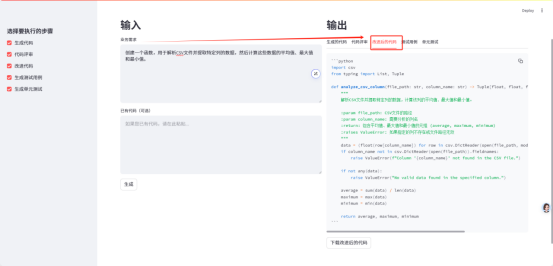
4. Test Cases
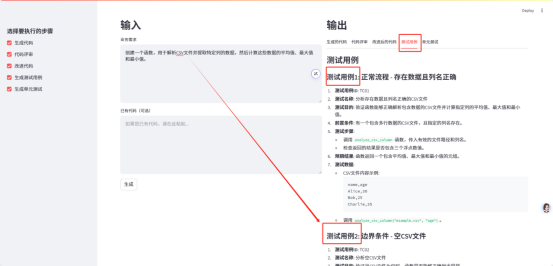
5. Unit Testing
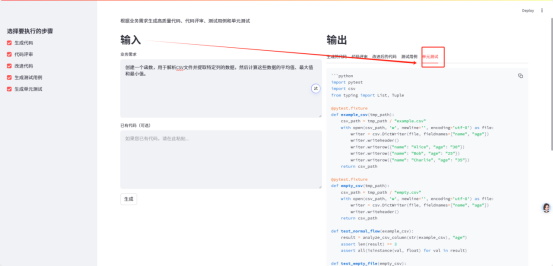
Subsequent improvement directions
- Support for more programming languages
- Adding code quality metrics
- Optimize prompt template to improve generation quality
- Add parallel processing to improve efficiency
- Support for more testing frameworks
- Add user feedback collection mechanism for continuous improvement
contribute
Contributing code, reporting issues, or suggesting improvements is welcome.