![]()
A Retrieval-Augmented Generation (RAG) AI assistant for question answering over custom document collections, using a vector database and local LLMs.
See GitHub repository.
KnowledgeBot enables you to index web content or Wikipedia articles into a vector database and ask questions about the ingested knowledge. It uses a local LLM (via Ollama), Qdrant as a vector store, and provides both a web UI and an API for interaction.
While numerous AI-powered question answering systems exist, many rely on cloud-based LLMs and proprietary vector databases, raising concerns about data privacy, cost, and control.
Existing solutions often require complex setup, lack transparency, or do not support fully local deployments.
KnowledgeBot addresses these gaps by providing an open-source, fully containerized RAG pipeline that runs entirely on local hardware, using open components like Ollama and Qdrant.
This approach empowers users to build private, domain-specific Q&A bots without exposing sensitive data to third parties.
However, the current implementation does not yet support advanced features such as incremental data updates, fine-grained access control, or integration with non-web data sources (e.g., PDFs, Office documents).
Future work should address these limitations and further benchmark KnowledgeBot against state-of-the-art RAG systems.
Clone the repository and start the services:
git clone https://github.com/mgoltzsche/knowledgebot.git cd knowledgebot make compose-up
This will launch the following services:
go.mod for details).To download the required LLMs into the Ollama volume, run:
make pull-models
Depending on your internet connection the model download takes a while.
With 100Mbit/s the download takes around 5 minutes.
Before you can use the web app you need to populate the vector database with useful data about the topic you want the AI to answer questions about.
To crawl and embed a website or Wikipedia page, use the provided Makefile targets.
For example, to crawl 100 Futurama-related Wikipedia pages, run:
make crawl-wikipedia-futurama
(Takes around 2.5 minutes.)
To crawl a custom site:
make crawl URL=https://example.com MAX_DEPTH=2
You can adjust URL and MAX_DEPTH as needed.
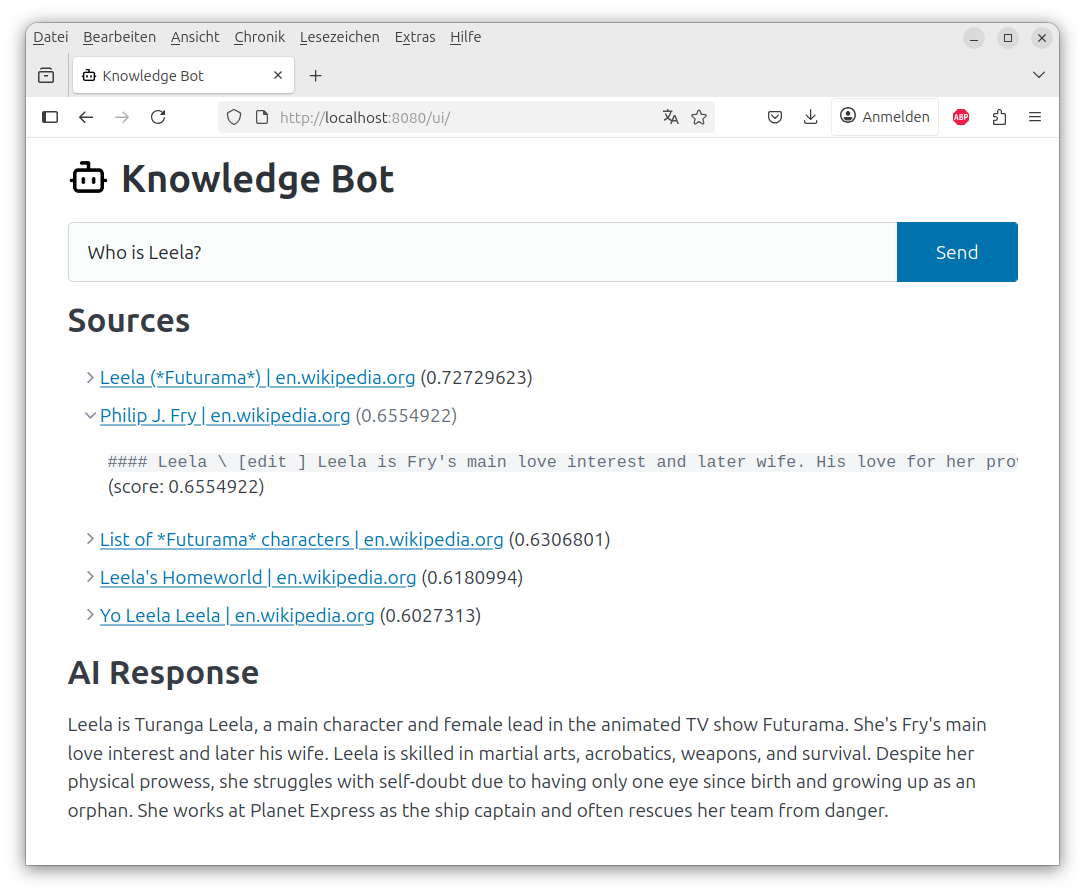
The primary interface provides an intuitive chat experience:
Open your browser at http://localhost
and enter your question (see example questions below).You can also query the API directly:
curl "http://localhost:8080/api/qna?q=What%20are%20the%20main%20Futurama%20characters?"
The /api/qna endpoint returns a stream of Server-Sent Events (SSE) with structured JSON, e.g.:
{"sources": [{"url": "...", "title": "...", "snippets": [{"text": "...", "score": 0.753}]}]}
{"chunk": "The main characters"}
{"chunk": " in Futurama include"}
{"chunk": " Fry, Leela, Bender and others."}
You can inspect the vector database using the Qdrant web UI at: http://localhost
/dashboardall-minilm for embeddings.qwen2.5:3b for chat completion in order to work with CPU inference on consumer hardware.Run unit tests:
make test
You don't have to configure anything because the defaults are sufficient.
All configuration options can be overwritten via environment variables in compose.yaml.
Optionally you can configure host-specific values such as e.g. an OpenAI API key by copying the .env_example file to .env and making your changes there.
Corresponding to the CLI options, the following environment variables are supported:
| Name | Default | Description |
|---|---|---|
KLB_EMBEDDING_DIMENSIONS | 384 | LLM embedding model dimensions |
KLB_EMBEDDING_MODEL | all-minilm | Embedding model to use |
KLB_LISTEN | :8080 | Address the server should listen on |
KLB_MAX_DOCS | 15 | Maximum number of document chunks to retrieve from qdrant < |
KLB_MODEL | qwen2.5:3b | LLM model to use for question answering |
KLB_OPENAI_KEY | API key for the OpenAI LLM API | |
KLB_OPENAI_URL | http://ollama:11434 | URL pointing to the OpenAI LLM API server |
KLB_QDRANT_COLLECTION | knowledgebot | Qdrant collection to use |
KLB_QDRANT__URL | http://qdrant:6333 | URL pointing to the Qdrant server |
KLB_SCORE_THRESHOLD | 0.5 | Qdrant document match score |
KLB_TOPIC | The TV show Futurama | Topic that is injected into the system prompt |
KnowledgeBot implements a classic RAG pipeline within a Go service, using the Qdrant vector database and Ollama.
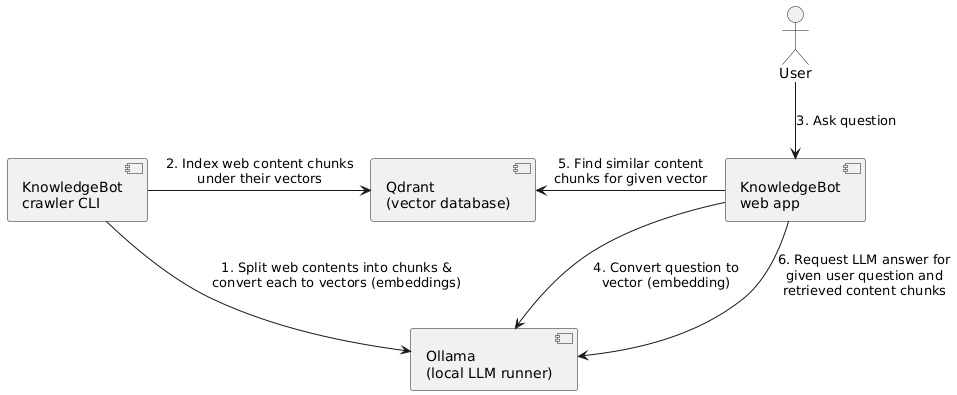
1. Document Ingestion
html-to-markdownall-minilm model (384 dimensions)2. Semantic Retrieval
3. Response Generation
Go for Core Logic: Chosen for its excellent concurrency model, making it ideal for web crawling and serving concurrent user requests while maintaining low resource usage. Also, as a statically typed programming language it can help reduce the amount of turnarounds since obvious errors are caught by the compiler early.
Qdrant Vector Database: Selected for its production-ready vector search capabilities, efficient storage, scalability and excellent Go client library support.
Ollama for LLM Serving: Provides a Docker-friendly way to run local models with consistent APIs, avoiding external dependencies and ensuring data privacy.
Local-First Architecture: Ensures all user data and queries remain on the user's infrastructure, addressing privacy concerns common in enterprise environments.
The RAG approach comes with some general limitations:
This project is licensed under the Apache 2.0 License.
Contributions are welcome! Please feel free to open issues or pull requests within the GitHub repository.
For questions or support, please open an issue on GitHub.