KnowBot is ideal for researchers, students, and professionals navigating complex literature with a focus on rigor and clarity.
While RAG-based systems are increasingly used in general tasks like web search and chatbots, they often fall short in academic workflows. Below is a comparison of common limitations and how KnowBot addresses them:
| Limitation in Existing Systems | How KnowBot Addresses It |
|---|---|
| ❌ No source traceability | ✅ Explicit citations and document-level attribution in every answer |
| ❌ Broad, unfocused retrieval | ✅ User-controlled, document-specific reference selection |
| ❌ Poor document interaction | ✅ Markdown previews, LLM summaries, and metadata tags |
| ❌ Opaque reasoning | ✅ Clear multi-source attribution for transparency |
| ❌ Lack of academic workflow support | ✅ Designed for research: reference refinement, follow-up Q&A, and controlled context |
KnowBot is built to support transparent, controllable, and document-grounded academic search and questioning—empowering users to explore literature with precision.

KnowBot introduces several innovations:
KnowBot helps users explore academic documents through explainable, reference-based semantic search. Below is a summary of its core capabilities:
| Area | Description |
|---|---|
| 🔍 Semantic Retrieval | Context-aware search across academic JSON/PDFs using HuggingFace embeddings + MongoDB vector search. Results are scoped to user-selected references. |
| 📄 Document Interaction | Markdown preview of full content with LLM-generated summaries. Real-time reference panel for adding/removing relevant documents. |
| 💡 Follow-up Suggestions | Multi-turn questioning with suggested next questions tailored to the current topic and reference set. |
| 🔎 Explainable Answers | Generated responses cite sources by document ID and explain multi-source contribution. |
| 🛠️ Modular System | Backend supports custom embeddings and models. Frontend built with Streamlit. Integrated CI/CD via GitLab. |
KnowBot’s core system consists of modules for document ingestion, metadata tagging, chunk summarization, embedding and indexing in MongoDB, and retrieval-augmented generation powered by large language models. A responsive UI and automated CI/CD pipelines support efficient and transparent academic search and question answering.
1️⃣ Ingest 📄 PDF/JSON documents ↓ 2️⃣ Process 📝 Chunk, tag metadata, summarize (Vertex AI), embed (HuggingFace BGE) ↓ 3️⃣ Index 🗂️ Store embeddings + metadata in MongoDB Atlas (vector index) ↓ 4️⃣ Retrieve 🔍 Semantic search + user selects reference documents ↓ 5️⃣ Interact 🤖 Ask questions & get cited answers via Vertex AI on Streamlit UI
KnowBot’s dataset combines publications from Ready Tensor with a diverse range of theses, academic papers, and conference proceedings sourced globally. The content spans a broad spectrum—from large language models to psychotherapy and counseling.
Machine Learning: 20Artificial Intelligence: 8Prostate Cancer: 6Psychometrics: 5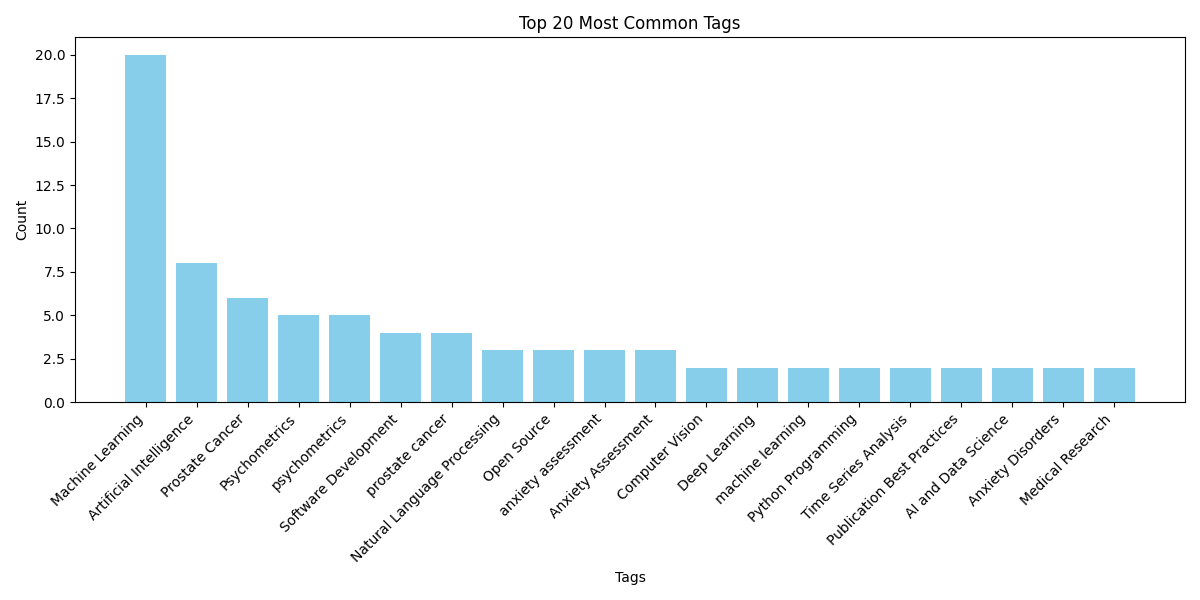
[!Note] Consider normalizing tag casing and merging semantically similar tags to improve data quality.
To prepare the data for retrieval-augmented tasks, each document undergoes:
KnowBot integrates several key AI components:
SUMMARY_PROMPT = """ You are a helpful assistant. Your task is to summarize a single document. Instructions: - If the document is short, provide a concise summary in one sentence. - If the document covers multiple key ideas, present them as a bulleted list. - Do **not** begin with generic phrases like "This document is about...". - Focus solely on the core content, highlighting the most important insights. """
REFERENCE_PROMPT = """You are a helpful assistant. Your task is to answer the user's question using only the information provided in the reference documents below. Instructions: - Use **only** the provided references. Do not use external knowledge or assumptions. - Always begin your answer with a brief **summary** (1-2 sentences). - Follow the summary with a detailed explanation, **formatted in Markdown**, with clear paragraph breaks. - At the end of **each paragraph**, add a **footnote reference** in Markdown style linking to the supporting document(s), e.g., `[^1]`. - If the answer is not found in the references, explicitly state that. - Finish with 2–3 thoughtful, open-ended follow-up questions formatted as a Markdown blockquote. Example format: ### Summary > Brief summary here. ### Detailed Answer First paragraph of detailed explanation.[^2] Second paragraph continuing the explanation.[^3] Third paragraph adding further details.[^2][^4] [^1]: [Document Title 2](#doc1) [^2]: [Document Title 3](#doc2) [^3]: [Document Title 4](#doc3) ### 💡 Follow-up Questions > #### Question 1? > #### Question 2? > #### Question 3? Question: {{user_question}} References: {{references}} """
The interface is specifically designed to support detailed academic exploration and research workflows, providing the following features:
 |  |
💡 Summary: KnowBot delivers accurate academic retrieval and transparent responses. Semantic search and chunk-level summarization enable users to quickly find and assess relevant content. Feedback highlights clear citation, easy document preview, and enhanced control over reference selection—streamlining academic workflows.
Clone the repository:
git clone git@gitlab.com:sc310542-group/KnowBot.git cd KnowBot
Install dependencies:
bash script/build-docker-image.sh
Set up your .env file:
📌 Note: You can choose one method to start model inference, just leave the other
"", and the app will automatically choose the one available
.env.example to .envMONGODB_URIMONGODB_NAMECOLLECTIONINDEX_NAMEOPENAI_API_KEYVERTEX_PROJECT_IDVERTEX_LOCATIONVERTEX_MODEL_NAMEGOOGLE_APPLICATION_CREDENTIALS (credential filepath)Launch the app:
cd deploy docker-compose up -d # for development bash script/run-dev-mode.sh streamlit run app.py --server.port=7860
Search for academic content
Enter your question in the search panel. The system performs semantic search over ingested JSON/PDF documents.
Explore and select references
Browse the retrieved documents and their AI-generated summaries. Choose relevant ones by clicking "Add to Ref".
Ask your question
With references selected, ask a question. The system uses only those documents to generate accurate, grounded answers.
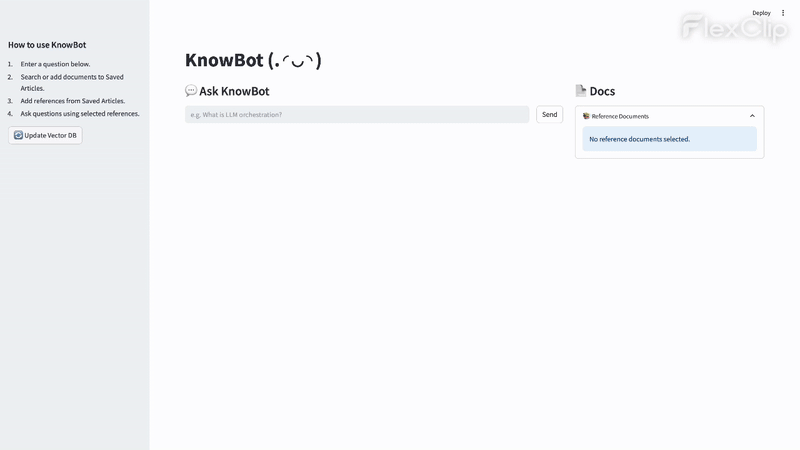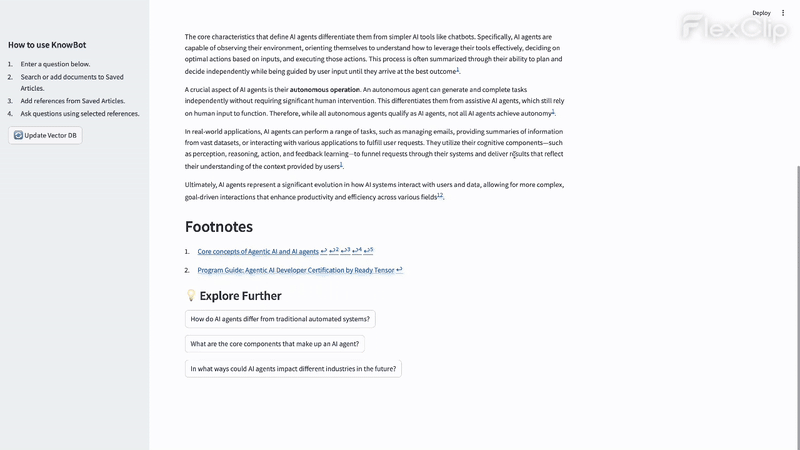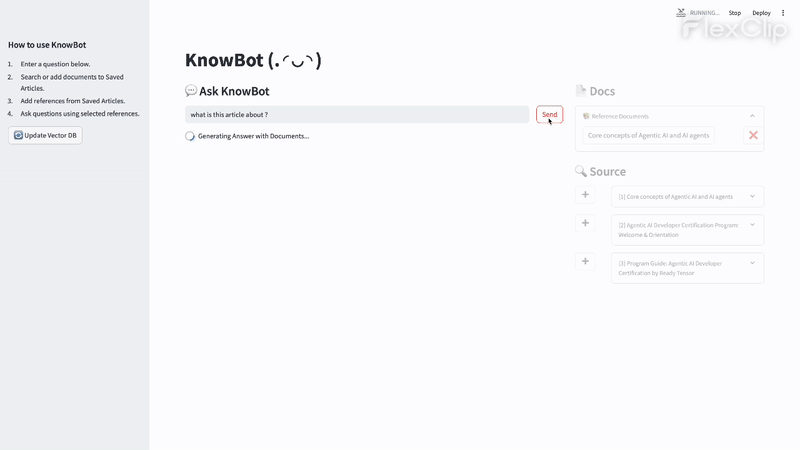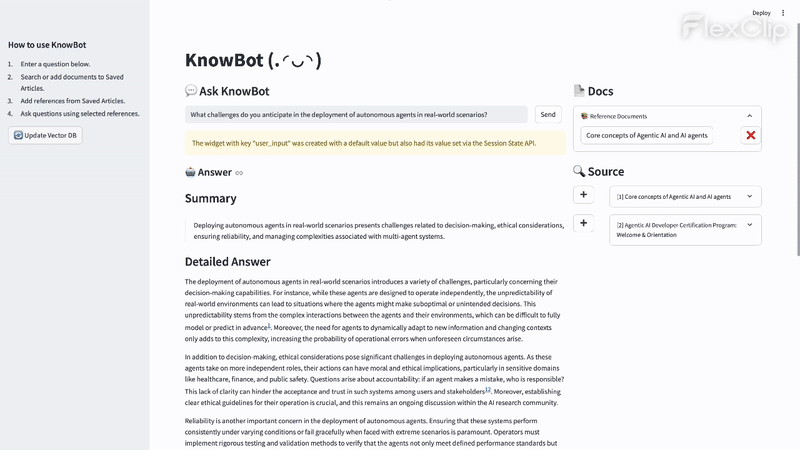
View source and follow-ups
Check the sources of the answer, and explore suggested follow-up questions to continue your research.
| Current Limitations | Planned Improvements |
|---|---|
| Fixed-size chunking may break context | Dynamic chunking algorithms |
| Basic metadata & tagging only | Smart tagging & classification |
| Limited file types supported | Expand to DOCX, HTML, etc. |
| No quantitative eval yet | Benchmarking with academic datasets |