.jpg?versionId=2BjaUl.UzwE0DMCgIOOE603Rz15mOBNS&Expires=1785231181&Key-Pair-Id=K3EVG0QTJR4SK0&Signature=vqRn4HkDhb-l9QojAfMr-rsEHVnCUDFLCXNtAhtrgVpMxFVyh33JNEXZC9gnkr0dMmLTnpP07dp3-~ml~1PW-A3ay2QhuAfiy5Y3cq1EZvtZYQycnj5wdmSR188RF~DHudZSJoa-DdJLh2eHa5U-4AkookgVfXzqT01K1wQoorcmOC7gZW0duM7Wvd7DTMmYF6tRIh9e8~qtYndxWoIeuVuo23CM-YHFrC-4zs2J9bDLsB~RuP6eYnG7QP~JJyRimyieXSQYj6FFC1wT968Os78gwEvyXE4oZCBgOaBAy1XVqmeSubJj7qCpbD2R45rZp0fmc3BcrOsz3MP5W1pe4g__)
The Interview Status Chatbot is a Retrieval Augmented Generation (RAG)-powered HR assistant designed to streamline job application tracking for both applicants and organizations. Built using Python, Pinecone, and the Groq LLM API, the chatbot retrieves real-time applicant data from a CSV file and provides personalized updates on application status, interview scheduling, and logistics. It features a user-friendly interface built with Chainlit, allowing applicants to simply enter their name and the position they applied for to receive structured, human-like responses. The project demonstrates how modern AI techniques like RAG can be effectively applied to automate HR processes, improve communication transparency, and enhance the candidate experience—all while ensuring data privacy and scalability.
Interview Status Chatbot is a professional HR assistant chatbot designed to streamline the job application experience by allowing applicants to check their status through a simple natural language interface. The chatbot provides real-time updates on application status, interview schedules, and locations — eliminating the need for manual communication from HR teams.
This solution is built using the Retrieval-Augmented Generation (RAG) paradigm and demonstrates the practical application of LLMs in human resources workflows. It empowers both organizations and applicants by automating status retrieval while ensuring personalized, privacy-conscious responses.
Interview Status Chatbot leverages a Retrieval-Augmented Generation (RAG) architecture combining Pinecone for vector search, Groq’s LLM API for natural language generation, and Chainlit for an interactive web interface. Applicant data is embedded and stored as vectors, enabling real-time semantic search and personalized HR-style responses without compromising privacy.
The chatbot is built using a Retrieval-Augmented Generation (RAG) pipeline, which combines semantic search with generative AI to retrieve accurate applicant data and respond with professional HR messages.
sentence-transformers/all-MiniLM-L6-v2 from Hugging Face and stored in a Pinecone index.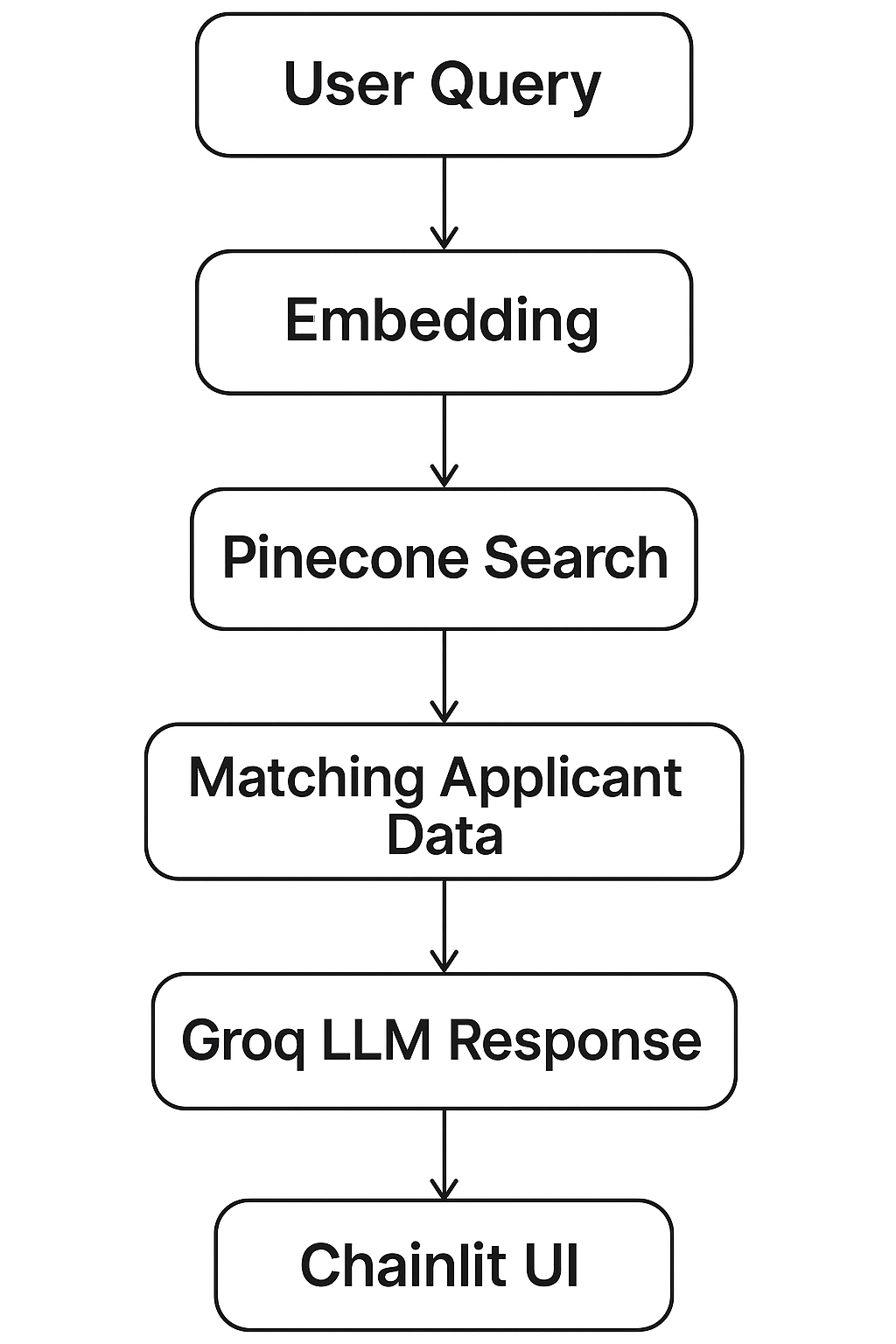
| Tool / Library / Technology | Purpose |
|---|---|
| Python | Core programming language |
| Chainlit | Web UI for LLM-powered chat interfaces |
| Pinecone | Vector database for storing and querying embeddings |
| Groq Cloud | High-speed LLM inference for response generation using llama-3.3-70b-versatile |
| dontenv | Securely load API keys from environment variables |
| pandas | Load and preprocess tabular data |
| Hugging Face | Generate text embeddings for semantic search using sentence-transformers/all-MiniLM-L6-v2 |
| LangChain | Orchestrates RAG pipeline components |
The project was tested using a sample dataset containing 200 above rows of applicant information sourced from a publicly shared Google Sheet. The test prompts followed the format:
"My name is [Name] and I have applied for [Position]"
The system was evaluated through its web interface built on Chainlit, with Groq Cloud handling response generation and Pinecone serving as the vector database for embedding retrieval.
To evaluate the model’s robustness and accuracy, a diverse set of representative prompts was used. These included both correct and incorrect name-role pairings, as well as edge cases to test the model’s tolerance to input noise and variation.
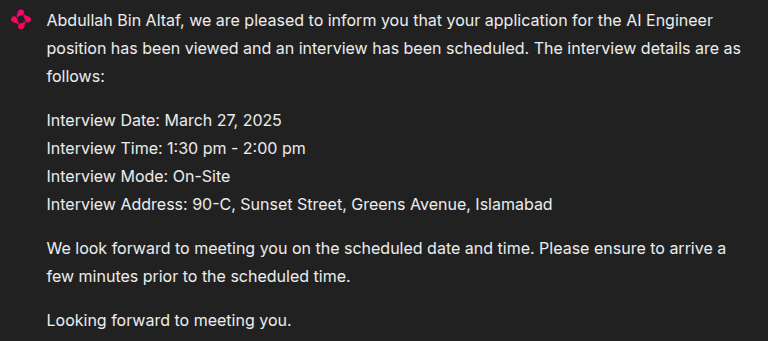
Prompt: My name is Abdullah and I have applied for AI Engineer position.
Expected Outcome: Matched — The name and role pair is valid and present in the dataset.
Actual Result:
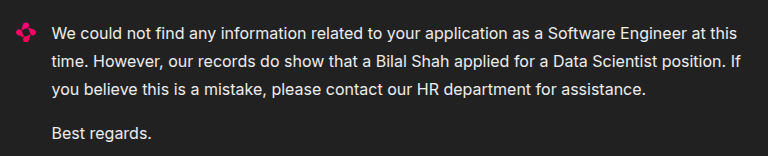
Prompt: My name is Bilal Shah and I have applied for Software Engineer position.
Expected Outcome: Mismatched — Although "Bilal Shah" exists, he applied for the Data Scientist role, not Software Engineer.
Actual Result:
Prompt: My name is Sarah and I applied for Content Writer role.
Expected Outcome: Not Found — "Sarah" does not exist in the dataset.
Actual Result:

Prompts such as “My name is Abudllah and I applied for AI Engineer position.” were tested to evaluate resilience against minor spelling errors.
Inputs with varying capitalization like “my name is abdullah…” or “MY NAME IS ABDULLAH…” were also tested to ensure consistent behavior.
These test cases helped verify that the system accurately retrieves valid records while rejecting incorrect or unseen combinations. By incorporating both standard and noisy inputs, we ensured the model performs reliably under realistic user behavior.
The chatbot’s performance was assessed based on the following:
The system’s performance was evaluated based on the following key metrics
The chatbot successfully retrieved correct applicant details for the valid query that was “Abdullah – AI Engineer”. Invalid queries like the one for “Sarah” and "Bilal Shah" resulted in appropriate responses indicating no matching records found, demonstrating effective handling of unknown applicants.
Generated responses were fluent, professional, and personalized, clearly providing interview status, dates, and locations when available. The use of Groq Cloud’s LLM ensured that answers were contextually relevant and human-like.
The system demonstrated resilience against input variations, correctly interpreting prompts with minor typos and differences in casing without significant loss in accuracy.
Average response time per query was under 15 seconds, showing fast retrieval and generation through Pinecone embeddings and Groq Cloud API.
The Interview Status Chatbot showcases the practical application of Retrieval-Augmented Generation (RAG) for automating HR communication in a personalized, efficient, and scalable manner. By integrating Groq Cloud's LLM capabilities with Pinecone for semantic search and Chainlit for user interaction, the system delivers accurate, context-aware responses to job applicants.
The project validates how small-scale RAG systems can be rapidly deployed using structured data sources like CSV files, enabling businesses to improve candidate experience without heavy infrastructure. Future enhancements will include real-time data updates on every query.
